Big Data Sets are available since BellaDati 2.9
Big Data Sets are special types of data sets that can be used to store a very large amount of data and build pre-calculated cubes. The main differences between standard data sets and big data sets are:
- Reports cannot be built directly on big data sets. Cubes have to be created first.
Since BellaDati 2.9.17, Reports can be built directly on big data sets. - In big data sets, it is not possible to browse all data. Only a random data sample is available. Filters, edit function, and delete function are not available in the data sample.
- Big data sets cannot be joined.
The main advantage of Big Data Sets is the ability to create pre-calculated cubes resulting in a rapid speedup of reports loading times.
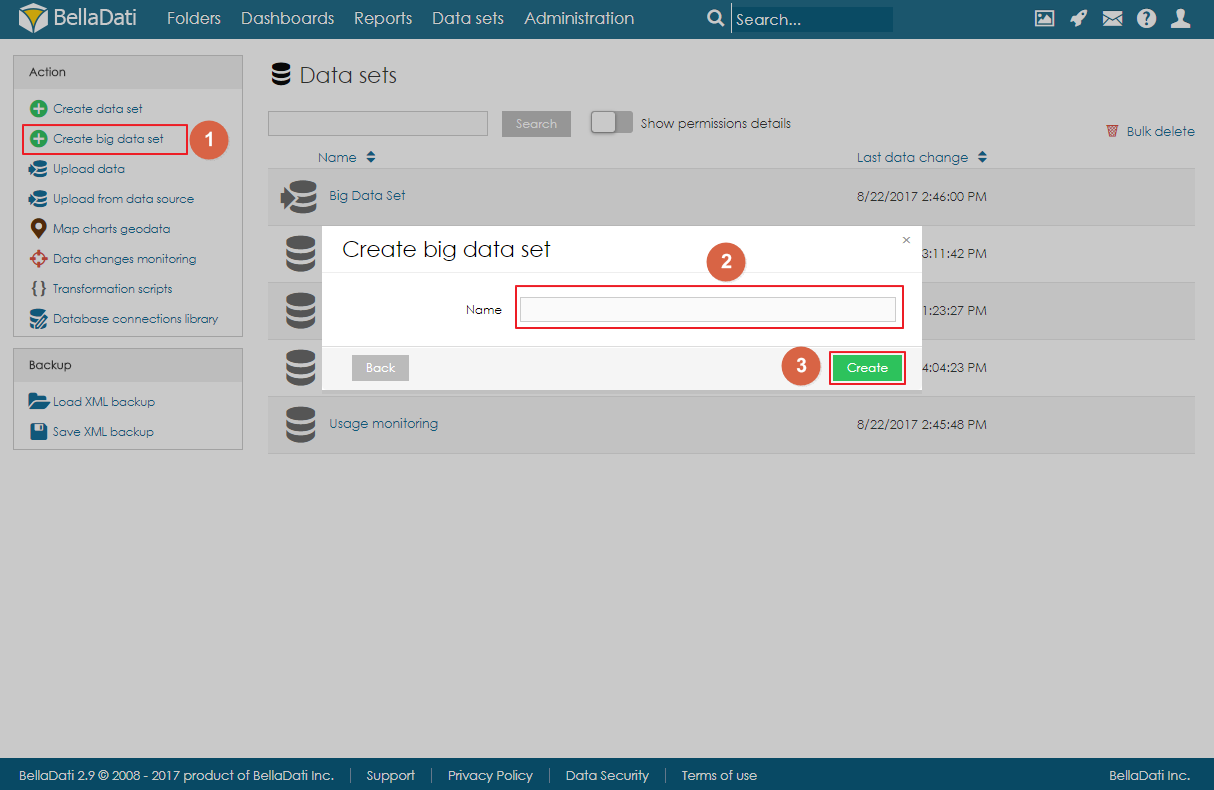
Creating Big Data Set
Please note that Big Data Set functionality needs to be enabled in the license and in the domain.
Big Data Set can be created by clicking on the link Create big data set in the Action menu on the Data Sets page, filling in the name of the big data set, and clicking on Create.
Big Data Set summary page
The landing page (summary page) is very similar to the standard data set summary page. There are a left navigation menu and the main area with basic information about the data set:
- description,
- date of last change,
- records count,
- cubes overview,
- import history.
Actions
- Update from XML - User can upload XML of structure with missing columns. Those columns will be updated and added.
Importing Data
Data can be imported to a big data set the same way as to standard data set. Users can either import data from a file or from a data source. However, the big data set is not using standard indicators and attributes, but instead, each column is defined as an object. These objects can have various data types:
- text,
- date,
- time,
- DateTime,
- GEO point,
- GEO JSON,
- long text,
- boolean,
- numeric.
After import, users can open the data sample page to see a randomly selected part of the data.
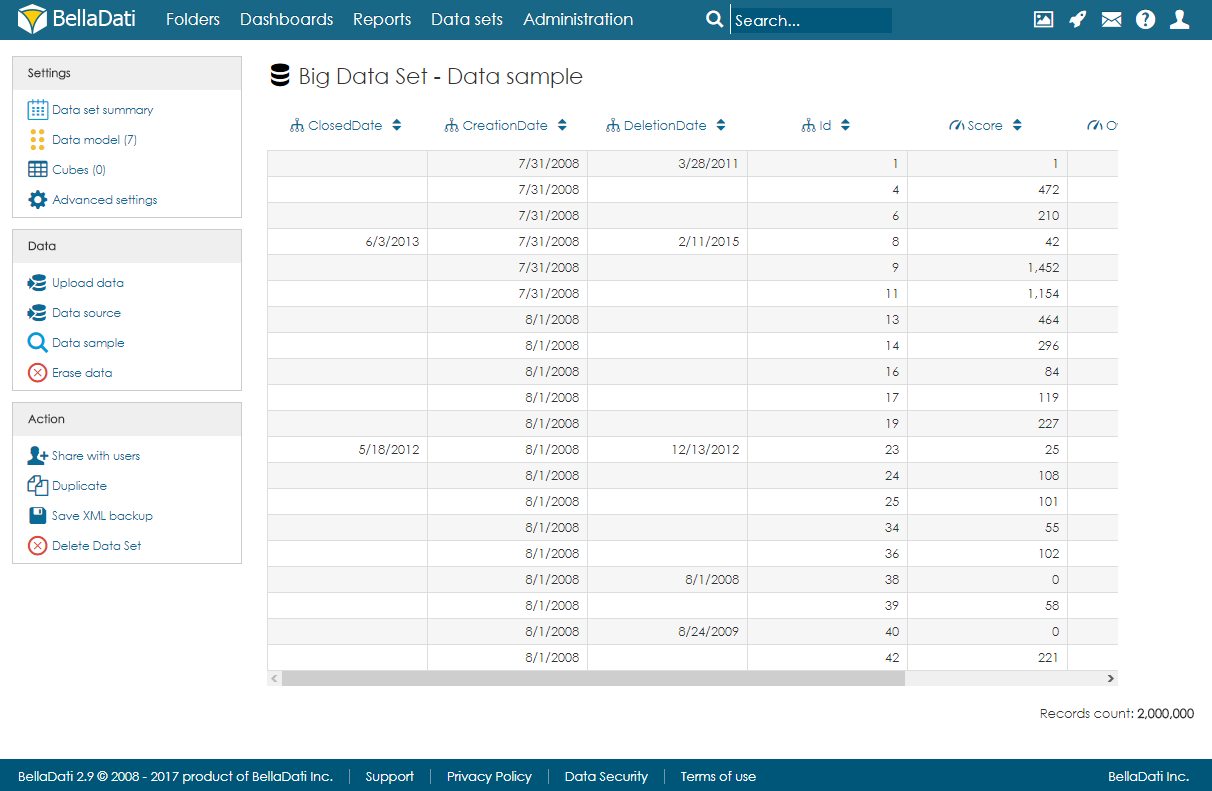
Managing Objects
Objects (columns) can be created automatically during the import, or they can be defined on the data model page. When adding a new object, users can specify its name, data type, indexation, and whether it can contain empty values or not. Please note that GEO point, GEO JSON, long text, boolean and numeric cannot be indexed.
Objects can also be edited and deleted by clicking on the row.
Cubes
Cube is a data table that contains aggregated data from the big data set. Users can define the aggregation and also limit the data by applying filters. Data from the cube can then be imported to a data set. Each big data set can have more than one cube, and each cube can have different settings.
Creating Cube
To create a cube, users need to follow these steps:
- Click on Create cube
- Fill-in the name and optionally the description.
- Select which columns (attribute elements and data elements). Attribute elements define the aggregation of the cube. For example, if the user selects column Country, the data will be aggregated for each country (one row = one country). Users can also create formula indicators. In real-time, users can also see the preview of the cube on the right side of the screen. Please note that the preview is built on the data sample only, which means that it can be empty, although some data will be imported to the data set after the execution. If you want to see result of whole content of Big Data Set, you can switch off "Use tablesample". This will load all data. This operation might be load intensive. It is possible to change the order of attributes and indicators by using the arrows located next to the names.
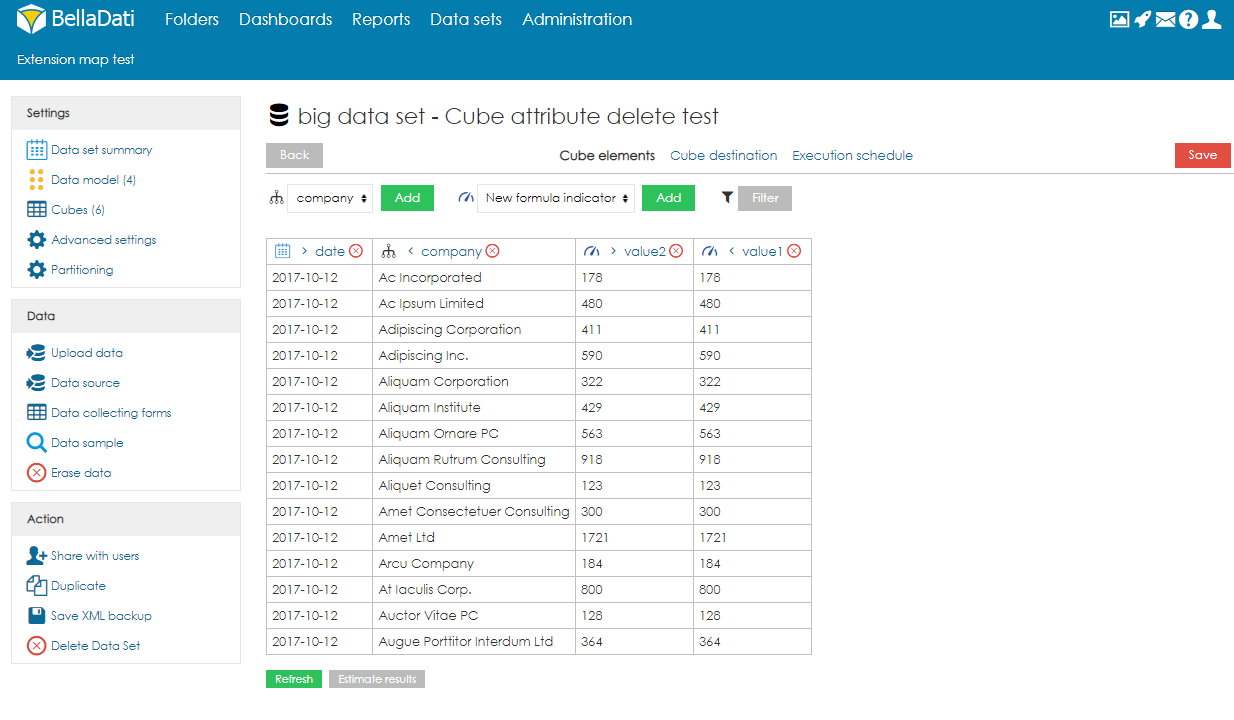
- Optionally, users can also apply filters to work with only part of the data.
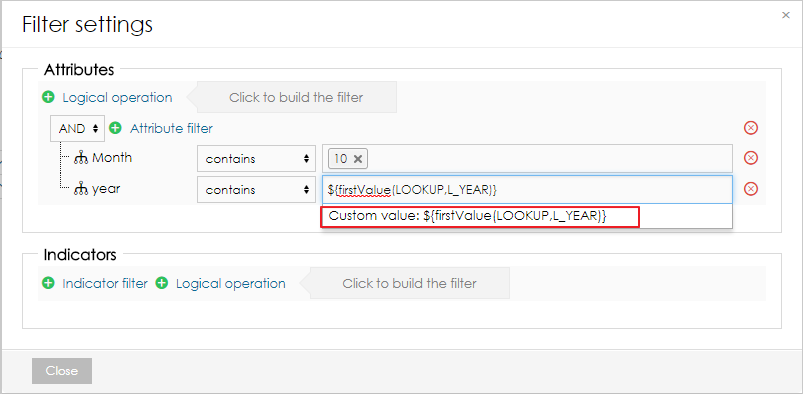
In the filters, users can reference first and last values from different data set by using the following functions:
${firstValue(DATA_SET_CODE,L_ATTRIBUTE)} ${lastValue(DATA_SET_CODE,L_ATTRIBUTE)} ${firstValue(DATA_SET_CODE,M_INDICATOR)} ${lastValue(DATA_SET_CODE,M_INDICATOR)}The function has to be added as a custom value to the filter.
It is also possible to add a filter formula. This allows users to create more complex filter algorithms. It is also possible to use the function getLastSuccessfulCubeExecution() or getCurrentCubeExecution() to get the date and time of the last successful or current cube execution correspondently.
def f = createFilter() andFilter(f, 'M_TIMESTAMP_INDICATOR', 'GT', timestamp(datetime(getLastSuccessfulCubeExecution().toString('yyyy-MM-dd HH:mm:ss.SSS')))) return f
- Select destination data set and mapping. By using the search field, users have to select the destination data set. After execution, data will be imported from the cube to this data set. After choosing the data set, users have to specify the mapping. Each column of the cube has to be assigned to an attribute or indicator of the destination data set. Attribute elements can be mapped to attribute columns in the destination data set. Data elements can be mapped to indicator columns and also attribute columns.
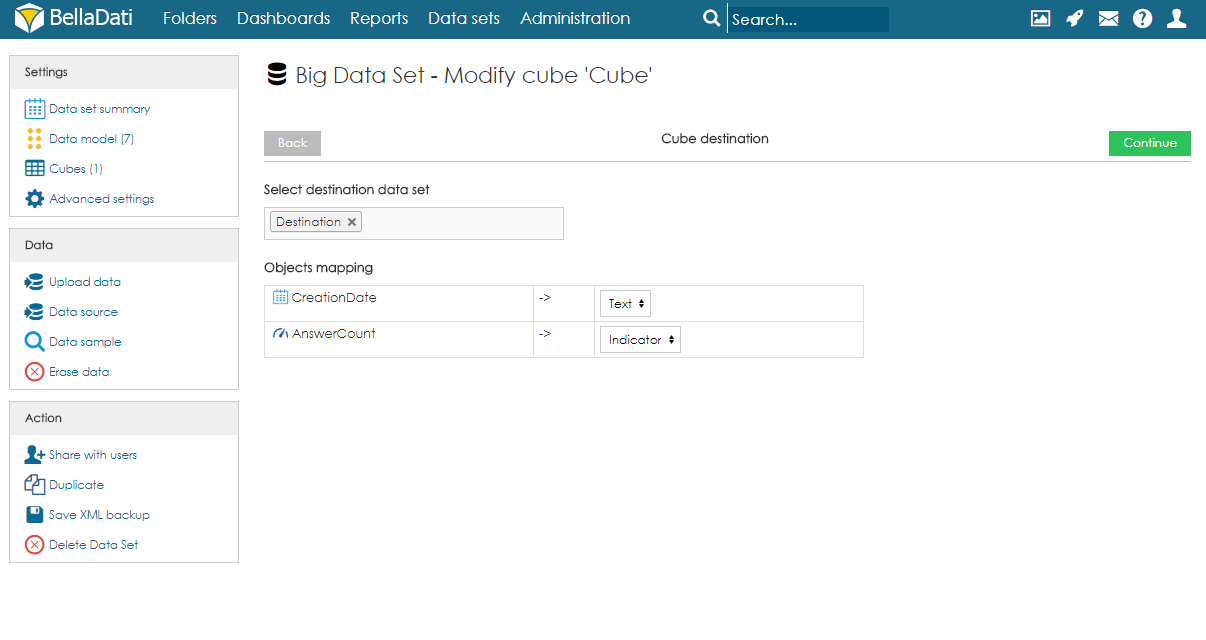
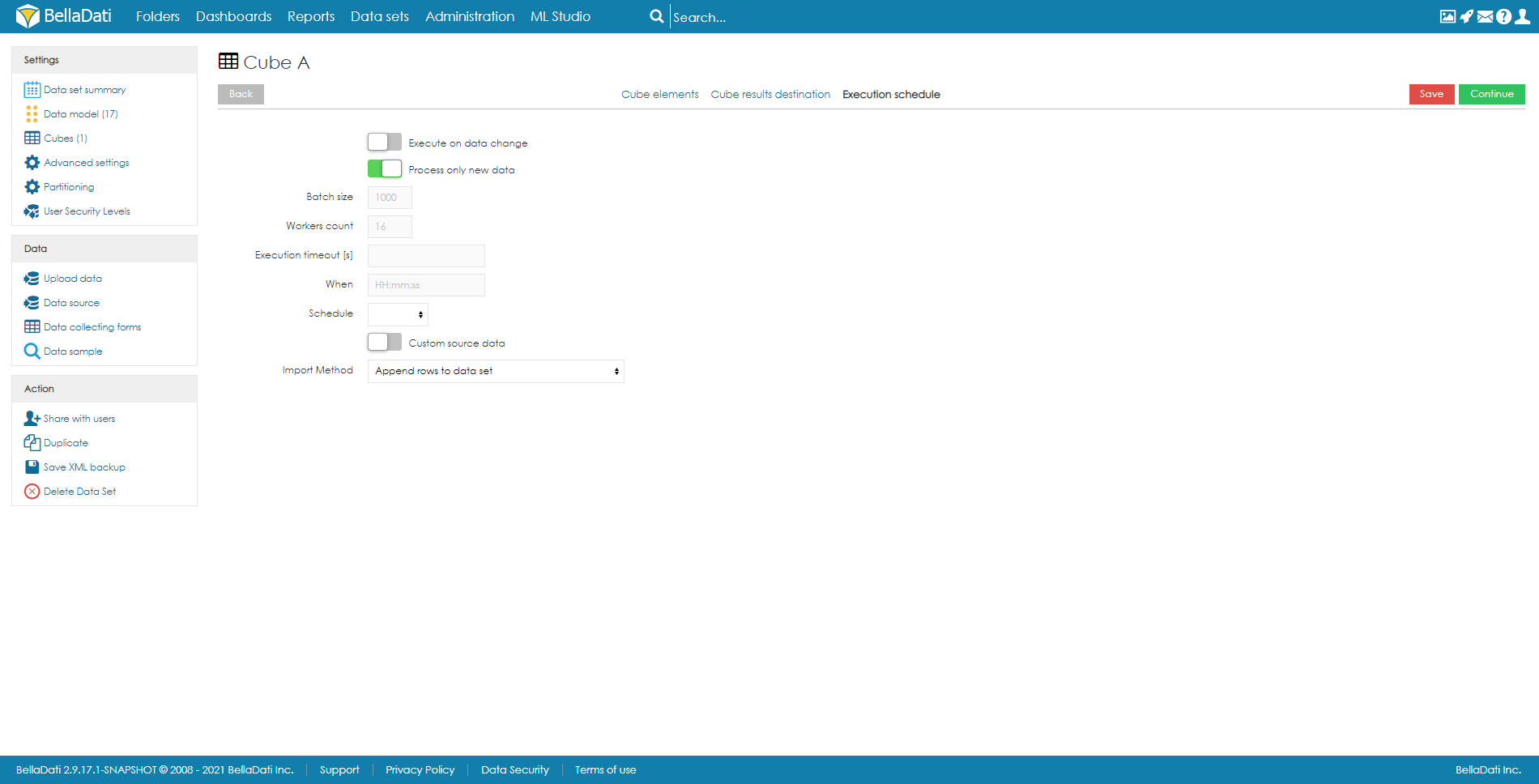
- Set up execution schedule. The execution can be run manually, on data change, or by schedule. When scheduling the execution, users can specify the following parameters:
- Process only new data - an option to automatically filter new data
Batch size (default 1000) - the number of rows that will be executed in one batch. In special cases, it might be beneficial to increase or decrease the value. However, in most cases, we strongly suggest leaving it on default.
Workers count (default 8) - the number of workers that should be used for parallel execution.
- Execution timeout [s] - sets the maximum duration of the execution.
When - time of the first execution.
Schedule - how often should be executed.
Import Method - what should happen with data in the destination data set. See Data overwriting policy for more information.
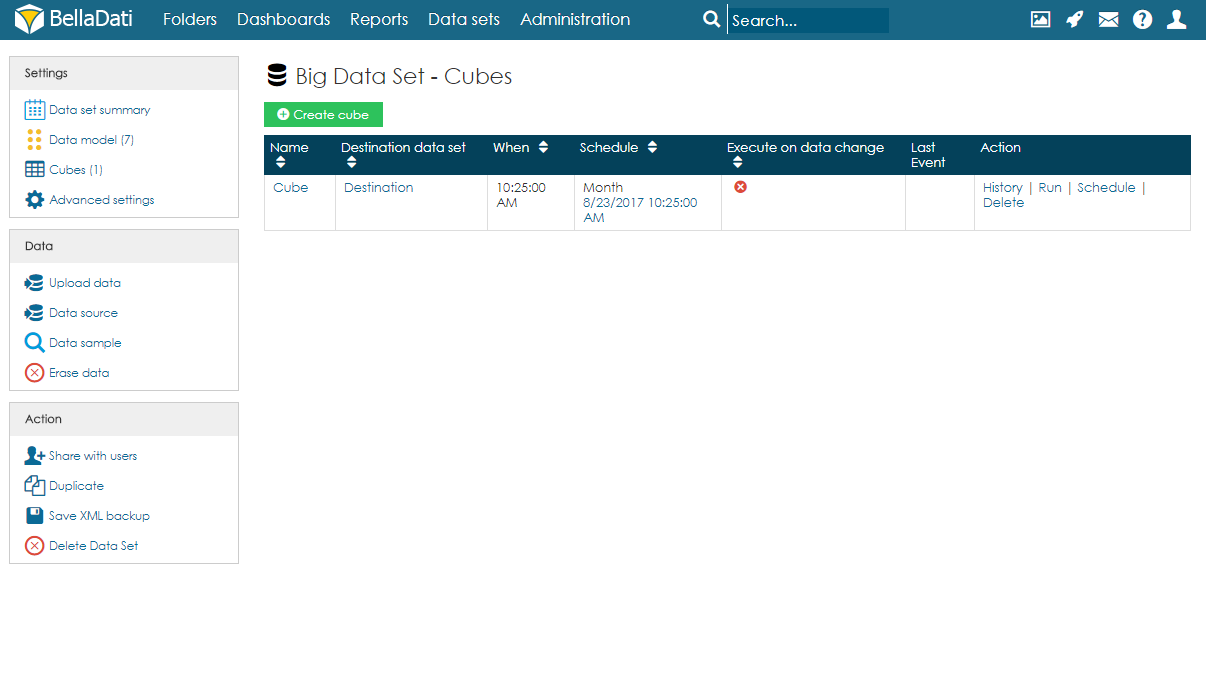
Cubes summary
On the Cubes page, users can see a table with all cubes associated with the big data set. For each cube, information about the schedule and last event are available. Users can also edit the cube by clicking anywhere on the row or on the name of the cube. Several actions are also available for each cube:
- History - see a list of previous executions and their result.
- Run - manually run the execution.
- Schedule - reschedule the execution. Previous settings will be overwritten.
- Delete - delete the cube.
Cube execution
As mentioned above, execution can be run manually, on data change, or by schedule.
- Manual execution - by clicking on Run in the Action column, users can start the execution manually. They can also select the import method, which can be different than the one used for scheduled execution.
- On data change - every time there is a change in the big data set, the execution will be started. If there is an already running cube execution, the new execution is placed in a queue and automatically triggered after the previous cube execution is completed.
- Scheduled execution - execution will be run periodically after a specified amount of time.
Users can also cancel the next scheduled execution by clicking on the date in the column Schedule and confirming the cancellation. Please note this will only cancel the execution and it won't delete it. After running the execution manually, the schedule will be restored. To delete the scheduled execution completely, users have to edit the cube and delete the Execution schedule.
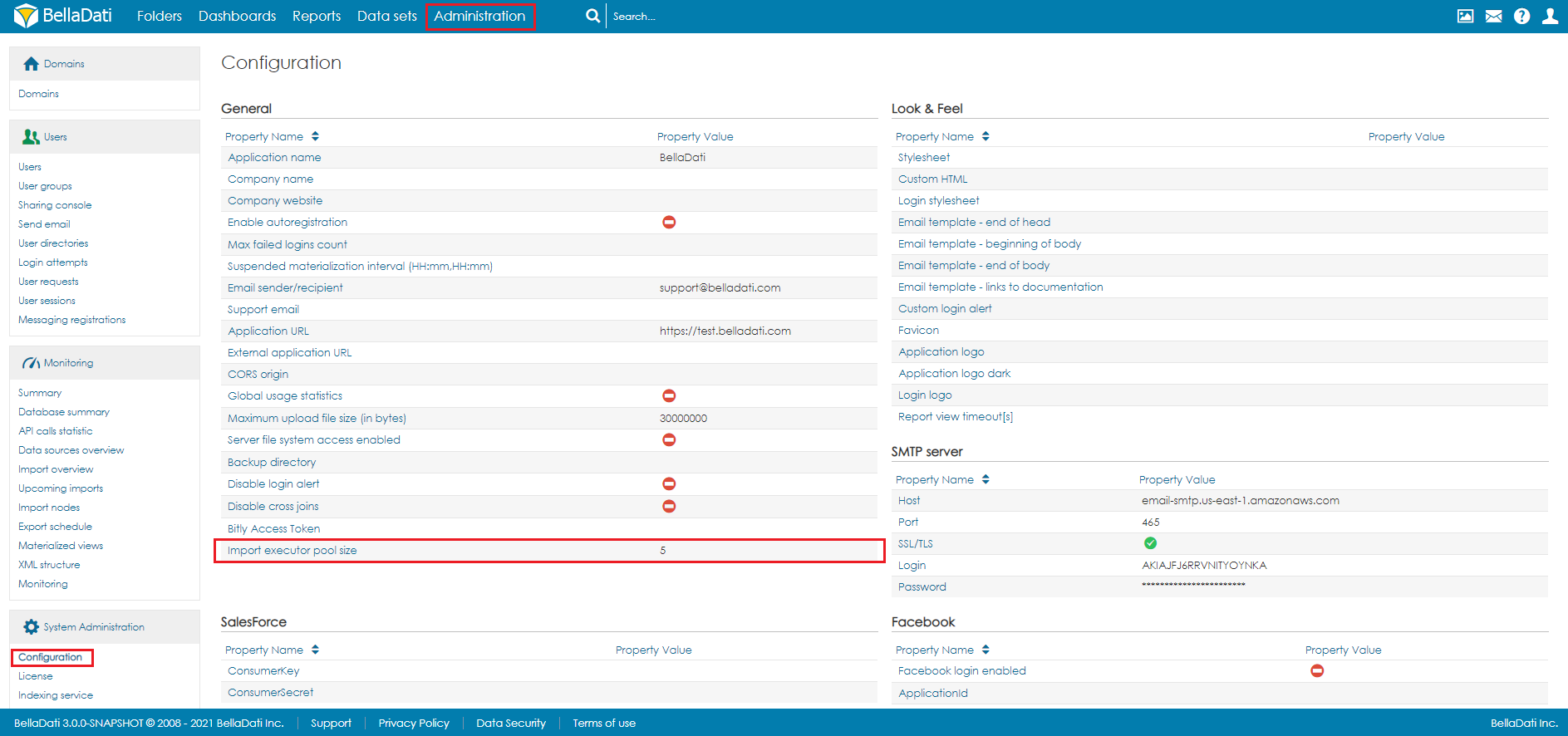
Limits for concurrent cube executions are available since BellaDati 2.9.18
Since the number of cubes could be large, there is a limit to the number of cubes that will be executed at the same time. By default, the number of concurrent cube executions is 5. To change it, open Configuration in Administration. The setting Import executor pool size defines this limit.
This setting is available for users with the role domain admin only
Tables
Tables are used for accessing Big Data Set data using API. Settings are same as in Cube settings. There is an additional option to set UID. This option will add a number of corresponding row and will disable aggregation. See documentation of how to obtain data using API here
Backup of Big Data Set
When using the XML backup of the big data set, the target data set and mapping in the cube are not stored. After restoring, they have to be set up again.
Overview
Content Tools