このチュートリアルに進む前に、rank()関数を十分参照することをお勧めします。
このチュートリアルでは、試験スコアがロードされたデータセットを活用します。
データセットには2つの列が含まれます:
- 生徒のID
- 生徒の点数
パーセンタイル(百分位数)
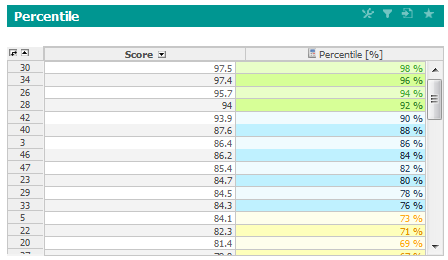
百分位数は、観測値の特定の割合がそれ以下になる変数の値です。例えば、20番目の百分位数は、観測の20%があたる値(スコア)です。
各生徒のスコアの横に百分位数を示す表を作成する必要があります。
生徒IDのドリルダウンと点数インジケータを使用して新しい表を作成します。
- 新しいインジケータを作成 – 百分位数
- 次の式をインジケータ設定に追加します。
単位にパーセンテージを設定し、適切な形式に関連付けます。
int records = aggregatePrevLevel(1){L_ID_COUNT}
int rank = rank() {M_SCORE}
double percentile = 1-(rank/records)
return percentile
- 行: 合計レコード(生徒)数を保存します。生徒のドリルダウンが使用されるため、1レベル上の集計が必要です。
- 行: 各レコードのランクを取得します。
行: ランクを百分位数に再計算します。例えば、100人の生徒のランクが5の場合、百分位数は: 1-(5/100) = 95%。
四分位数
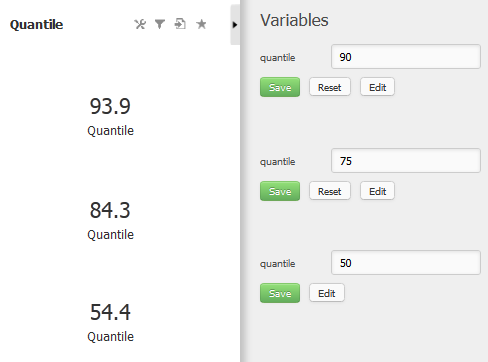
データのセットを等しい割合に分割する値です。例としては、中央値、四分位数、十分位数があります。
試験スコアの中央値を示すKPIラベルを作成する必要があります。
- 新しいKPIラベルを作成します。
- 新しいインジケータを作成 – 四分位
- 次の式をインジケータ設定に追加します。
- 観測された四分位を動的に変更できるように、四分位変数を作成します。
int records = L_ID_COUNT
double groups = 100/@quantile
int key = round(records-records/groups)
double median = 0
membersSum('L_ID'){
rank = rank(){M_SCORE}
if (rank == key){
median = M_SCORE
}
}
return median
- 最初の3行を使用して、提供された四分位数変数を変換し、スコアセット内の対応する位置を見つけます。
- 生徒IDのレベルに集計された各スコアのランクを取得します。
- 現在のランクが位置と等しい場合、点数を中央値変数に格納します。
次に
Overview
Content Tools