Die Seite mit den Importeinstellungen ermöglicht es Ihnen, ETL-Operationen (Extract-Transform-Load) zu steuern und die Struktur der zu importierenden Daten zu überprüfen. Die Hauptaufgabe besteht darin, die Zuordnung von tabellarischen Daten zu Attributen, Indikatoren und Datums-/Zeitdimensionen zu definieren.
Folgende Einstellungen und Aktionen sind möglich:
Die erste Zeile ist die Kopfzeile: Verwenden Sie die Texte in der ersten Zeile als Namen für die entsprechenden Spalten; nur für einfachen Text (Zwischenablage), CSV oder Excel.
Ausgeschlossene Zeilen: Ermöglicht es Ihnen, einige Zeilen am Anfang der importierten Datei auszuschließen (z.B. zusätzliche Informationen, keine Daten); nur für reinen Text (Zwischenablage), CSV oder Excel.
Kodierung: Wählen Sie die geeignete Kodierung für die Quelldatei aus (UTF-8, ISO-8859-1, Win-1250, Win-1252, Auto sind verfügbar); nur für reinen Text, CSV oder XML.
Trennzeichen: Automatische Erkennung (das häufigste Trennzeichen ist das Semikolon ";"), ansonsten wählen Sie ein Zeichen, das jede Spalte trennt (Komma, Tab, Semikolon, Leerzeichen, vertikale Leiste, benutzerdefiniert); nur für Klartext (Zwischenablage) und CSV.
Füllen Sie die leeren Zellen: Im Allgemeinen für den gesamten Import, oder diese Ersetzung kann für bestimmte Spalten einzeln durchgeführt werden.
Importvorlage anwenden: Siehe Kapitel "Vorlagen importieren" weiter unten.
Standardeinstellungen verwenden: Setzt alle Importeinstellungen auf die Standardeinstellungen zurück.
Neue Spalten holen: Ruft neue Spalten aus aktualisierter Datenquelle ab - wenn es eine bestehende Importvorlage gibt, existieren neu hinzugefügte Spalten aus dem Dataset nicht in der Vorlage aus dem vorherigen Import).
Weitere Funktionen sind:
Datenbereinigung und -transformation mit Hilfe des Transformationsskripts
Zuordnung importierter Spalten zu bestehenden Attributen oder Kennzeichen
Spalten umbenennen
Spaltenzusammenführung
Hinzufügen neuer Spalten
Vorschau der Änderungen
Die automatische Erkennung von Codierungen ist nicht immer zuverlässig. Wir empfehlen, in der Vorschau auf seltsame Zeichen zu achten.
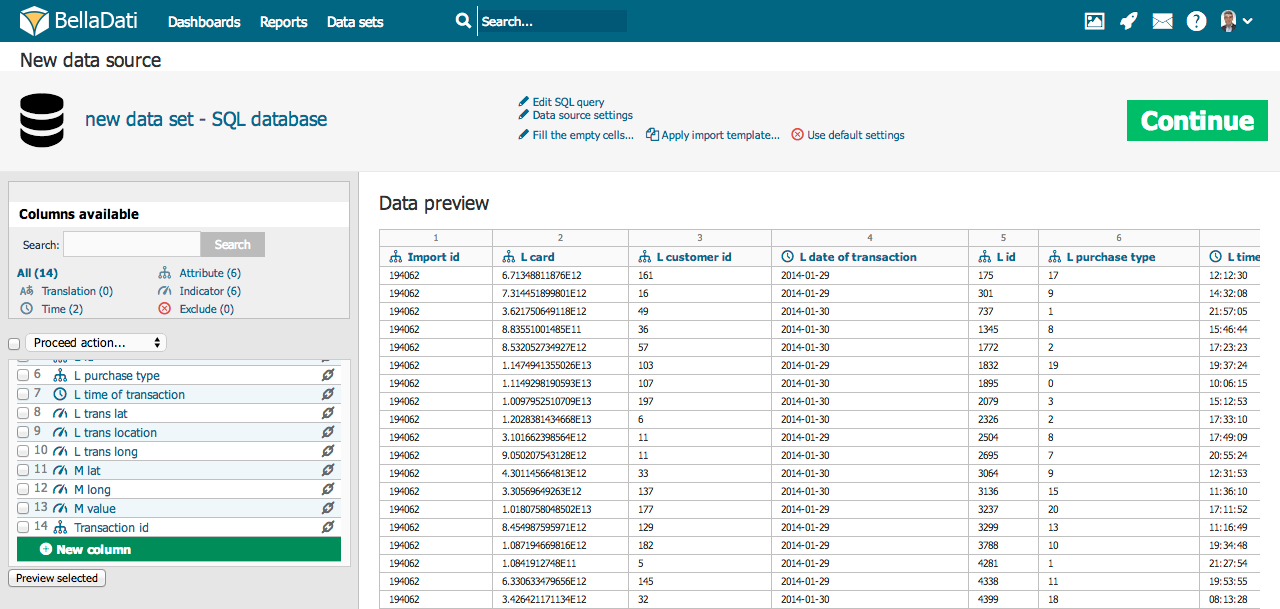
Die Verfügbarkeit der Anpassungen auf dem obigen Screenshot kann je nach importiertem Dateiformat variieren. Optionen für den manuellen Import sind angegeben, siehe Datenquellen für spezifische Informationen über automatisierte Importe.
Column Settings
ETL-Name - es ist der Name der Spalte, wie er mit den Quelldaten geliefert wird (z.B. SQL-Spaltenname, CSV-Headerzeilenspalte, etc.). Der ETL-Name ist von der Umbenennung der Spalte auf der Seite mit den Importeinstellungen nicht betroffen. Der Zweck der Speicherung des ETL-Namens ist einfach - BellaDati kann die eingehenden Daten leicht auf die vorhandenen Objekte (Attribut/Indikator) abbilden - z.B. wenn Sie die Reihenfolge der Spalten in Ihren Daten ändern, die Spaltennamen aber gleich bleiben, ordnet BellaDati die Spalte dem richtigen Objekt zu.
Wenn Sie den Typ einer bestimmten Spalte ändern möchten, klicken Sie auf den Namen der ausgewählten Spalte in der Liste der Spalten (auf der linken Seite des Importbildschirms). Es ist auch möglich, die Bedeutung mehrerer Spalten in nur einem Schritt auf einen Typ zu ändern - markieren Sie einfach ausgewählte Spalten, indem Sie auf die Kontrollkästchen neben ihnen klicken und dann ihre Bedeutung aus dem Menü oben auswählen.
Es gibt acht mögliche Bedeutungen von Spalten (Datentypen):
Datum/Uhrzeit (separat) - Zeitindex bestimmter Zeilen. Es kann in vielen verschiedenen Zeitformaten angezeigt werden (auch sprachabhängig - weitere Informationen finden Sie im entsprechenden Teil dieses Kapitels). Sie können mehrere Datums-/Uhrzeitspalten im Einzelimport auswählen.
Datum/Uhrzeit - Datumszeitindex bestimmter Zeilen. Es kann in vielen verschiedenen Datumsformaten angezeigt werden (auch sprachabhängig - weitere Informationen finden Sie im entsprechenden Teil dieses Kapitels). Sie können mehrere Datetime-Spalten im Einzelimport auswählen.
Langtext - definiert Langtext - Beschreibung. Dieser Spaltentyp sollte für Spalten verwendet werden, die Werte mit einer Länge von mehr als 220 Zeichen enthalten. Kann nicht in den Visualisierungen und Aggregationen verwendet werden. Geeignet für folgende Anwendungsfälle:
- Zeigen Sie Quelldaten in Spalten an, die Werte mit einer Länge von mehr als 220 Zeichen enthalten.
- In den KPI-Labels und -Tabellen werden Werte mit einer Länge von mehr als 220 Zeichen angezeigt - in diesem Fall sollten die Funktionen firstValue() & lastValue() verwendet werden.
Attribut - definiert Kategorien des Drill-Down-Pfades. Es handelt sich in der Regel um einen kurzen Text (z.B. Affiliate, Produkt, Kunde, Mitarbeiter, Abteilung etc.). Jede Attributspalte erzeugt genau ein Attribut im Dataset. Diese Attribute können in den Drill-Down-Pfaden frei kombiniert werden.
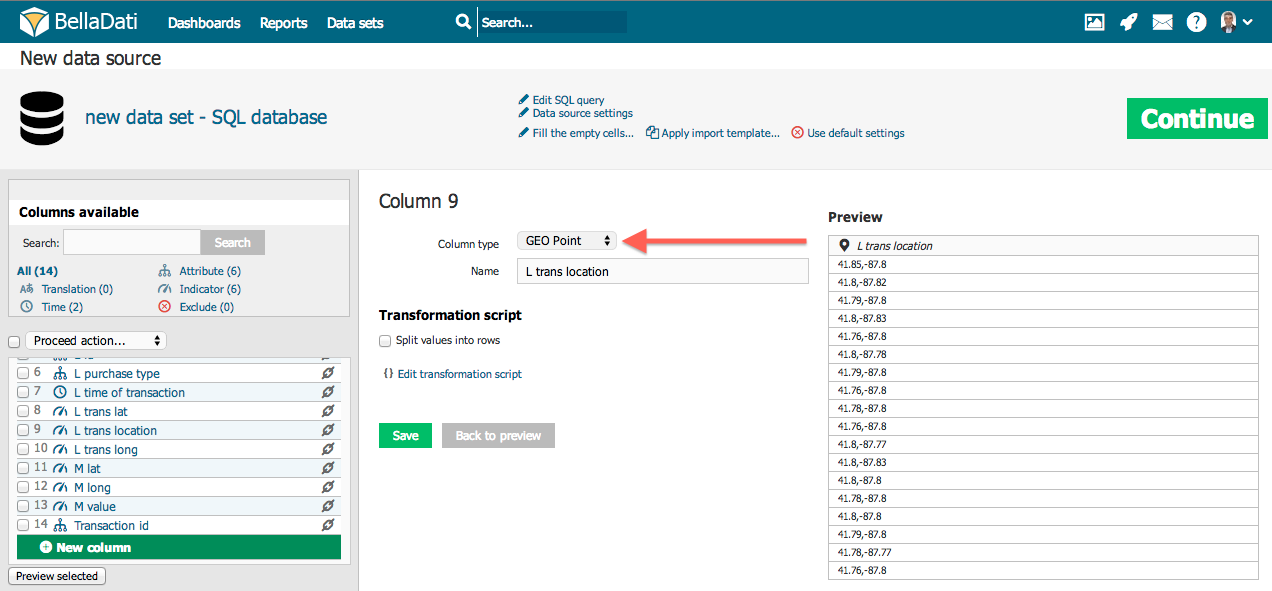
GEO Point - Sie können den Breitengrad/Längengrad auf den Attributtyp GEO Point abbilden. Dieses Attribut kann dann im Ansichtstyp Geokarte verwendet werden, um Daten an ihrer jeweiligen Position darzustellen.
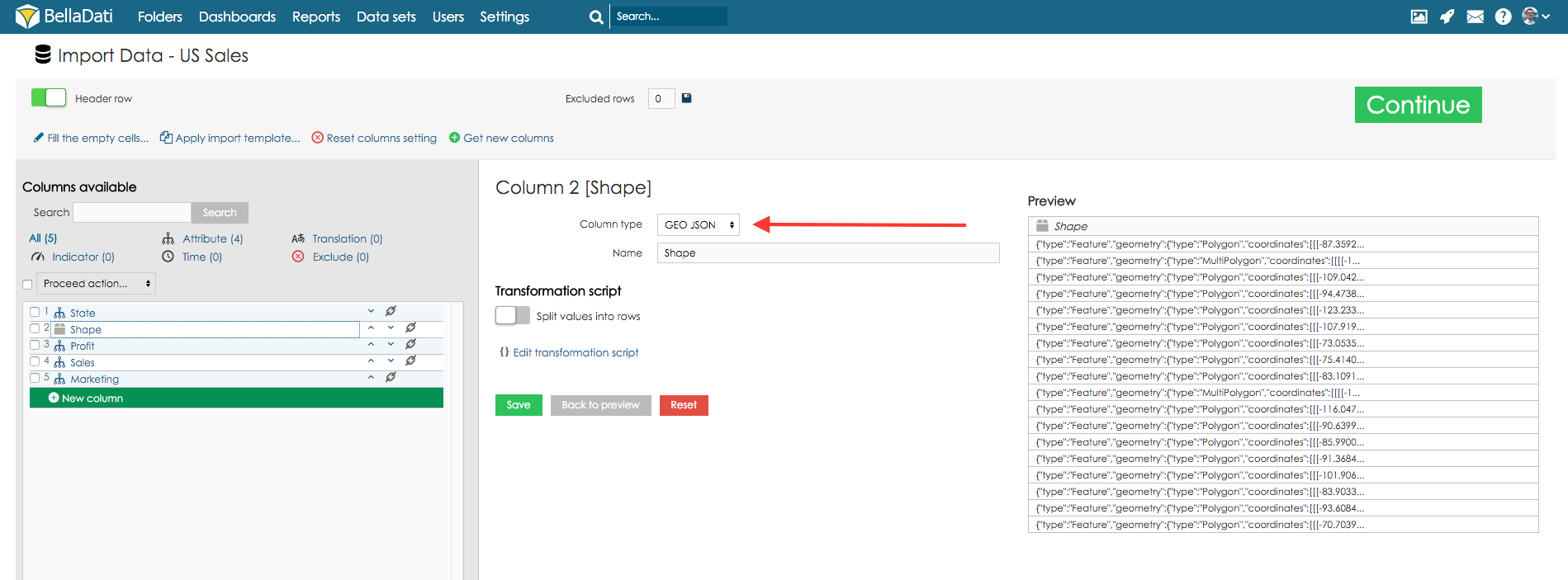
GEO JSON - Sie können die Form auf den Attributtyp GEO JSON abbilden. Dieses Attribut kann dann im Ansichtstyp Geokarte verwendet werden, um Daten an ihre bestimmte Position zu plotten, die als Form angezeigt wird.
Übersetzung - definiert die Sprachübersetzung einer anderen Spalte, die als Attribut identifiziert wird.
Indikator - Indikatoren sind in der Regel die numerischen Daten, die den Schwerpunkt des Interesses des Benutzers bilden.
Nicht importieren - diese Spalten werden überhaupt nicht importiert (nützlich, wenn die Spalte keine, ungültige oder unwichtige Daten enthält).
Datum/ Uhrzeit
Wenn Ihre Quelldaten Datetime-Werte enthalten, können Sie diese auf das Attribut Datum/ Uhrzeit abbilden. Diese einzelne Spalte enthält sowohl Datum als auch Uhrzeit, z.B. 5 Apr 2014 10:43:43:43 AM. Siehe folgendes Beispiel:
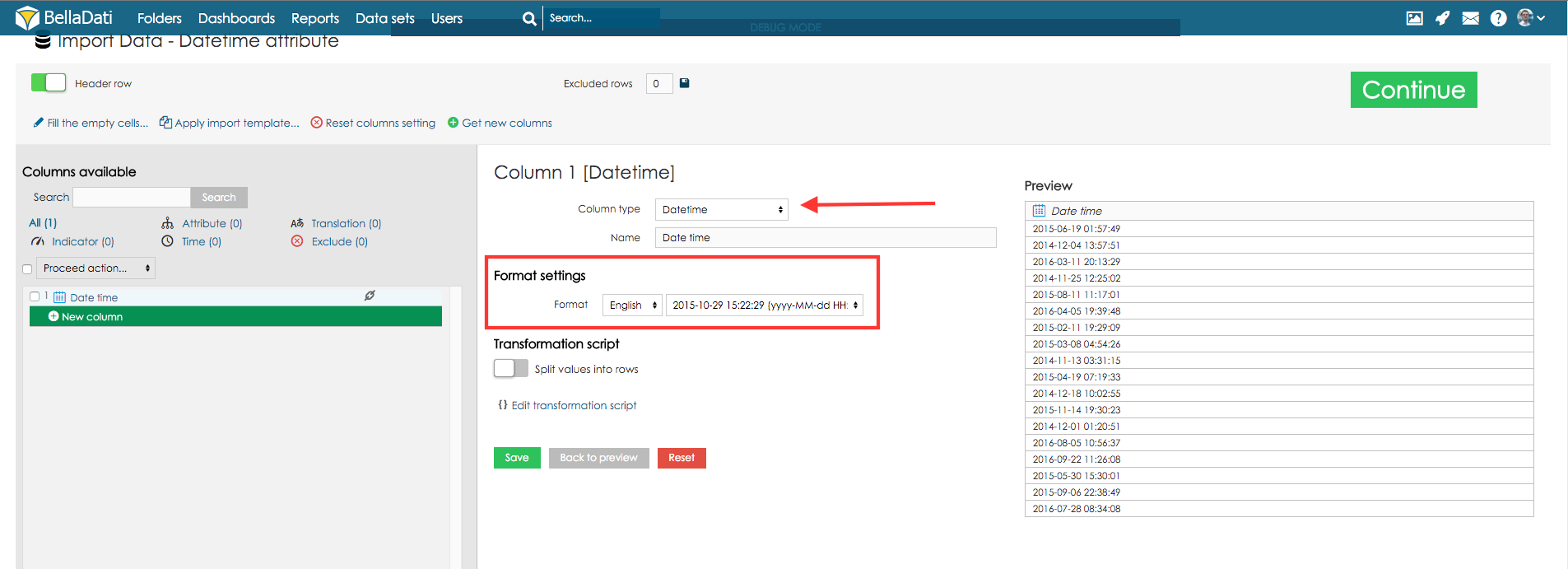
Datum/ Uhrzeit Format
Jede Spalte hat eine bestimmte Art von Format. Dieses Format sollte beim Import automatisch erkannt werden. Es ist jedoch möglich, dass Sie Ihre Zeitangaben in einem sehr spezifischen Format haben. In diesem Fall können Sie die Liste der verfügbaren Formate in verschiedenen Sprachen verwenden.
Wenn Sie nicht aus den verfügbaren Formaten wählen, können Sie auch Ihr eigenes, spezielles Format für Ihre Daten definieren. In diesem Fall sollten Sie Ihre Sprache aus der folgenden Liste auswählen und einen Code eingeben, der Ihr Datenformat entsprechend dieser Bedeutung beschreibt (beachten Sie, dass die Anzahl der Zeichen die Interpretation des Codes beeinflusst):
Code | Meaning | Number of characters in code |
|---|---|---|
y | Jahr | Zwei Zeichen (yy) stehen für die zweistellige Jahreszahl (89). Andernfalls wird der Code als vierstellige Jahreszahl (1989) interpretiert. |
M | Monat im Jahr | Drei oder mehr Zeichen (MMM) werden als Textdarstellung des Monats interpretiert (z.B. "Januar" oder "Jan"). In anderen Fällen werden Zeichen als Anzahl der Monate im Jahr interpretiert. (1-12). |
d | Tag im Monat | Die Anzahl der Zeichen (d) im Code sollte gleich der minimalen Anzahl von Stellen in den Quelldaten sein. Es ist immer ein numerisches Format. |
E | Tag in der Woche | Die Zeichenanzahl bestimmt, ob der Tag im vollen Namen (EEEE - "Montag") oder in der Abkürzung (EE - "Mo") angezeigt wird. |
| H | Stunde vom Tag | Die Anzahl der Zeichen (H) im Code sollte gleich der minimalen Anzahl von Ziffern in den Quelldaten sein. Es ist immer ein numerisches Format. |
| m | Minute in der Stunde | Die Anzahl der Zeichen (m) im Code sollte gleich der minimalen Anzahl der Stellen in den Quelldaten sein. Es ist immer ein numerisches Format. |
| s | Sekunde in der Minute | Die Anzahl der Zeichen (s) im Code sollte gleich der minimalen Anzahl von Ziffern in den Quelldaten sein. Es ist immer ein numerisches Format. |
Das Trennzeichen sollte gleich dem Trennzeichen in den Quelldaten (Leerzeichen, Punkt, Semikolon, etc.) sein. Wenn Ihre Quelldaten Zeit in getrennteren Spalten (Monate, Tage, Jahre) enthalten, ist es notwendig, diese Spalten zuerst zusammenzuführen (wie im vorherigen Teil dieses Kapitels beschrieben). Die nächste Tabelle zeigt eine Kombination aus Quelldaten und entsprechendem Timecode.
Quelldaten | Entsprechender Code |
|---|---|
09/15/10 | MM.dd.yy |
26/03/1984 | dd/MM/yyyy |
15.September 2010 | dd.MMMM yyyy |
15 Sep 10 | dd MMM yy |
Wed 15 09 10 | EE dd MM yy |
Sep 15, 2010 | MMM d, yyyy |
| 15:55:35.231 | HH:mm:ss.SSS |
| 28 October 2015 15:55 | dd MMMM yyyy HH:mm |
Datum/ Uhrzeit
Wenn Ihre Quelldaten Datums-/Uhrzeitwerte enthalten, können Sie diese den entsprechenden Datums- oder Zeitattributen zuordnen. Eine einzelne Spalte kann sowohl Datum als auch Uhrzeit enthalten, z.B. 5 Apr 2014 10:43:43:43 AM. In diesem Fall wird der Datumsteil, 5. April 2014, auf das Datumsattribut abgebildet, der Zeitteil, 10:43:43 AM auf das Zeitattribut. Siehe folgendes Beispiel:
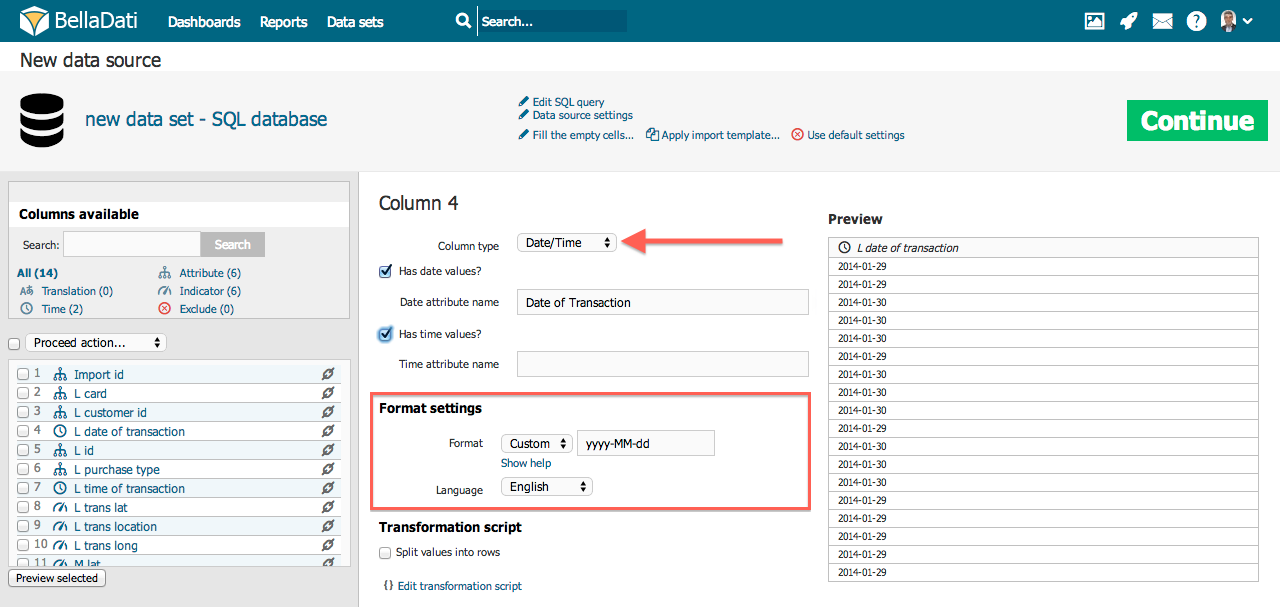
Die Definition des Datums-/Zeitformats ist die gleiche wie für die Spalte Datun/ Uhrzeit.
Übersetzung
Mit BellaDati können Sie Attributübersetzungen direkt importieren. Um die Attributübersetzung einzurichten, navigieren Sie zur Spalte mit der Sprachmetaphrase und:
Wählen Sie Übersetzung in Spaltentyp
Übersetzungssprache auswählen
Geben Sie den Index der Originalspalte an
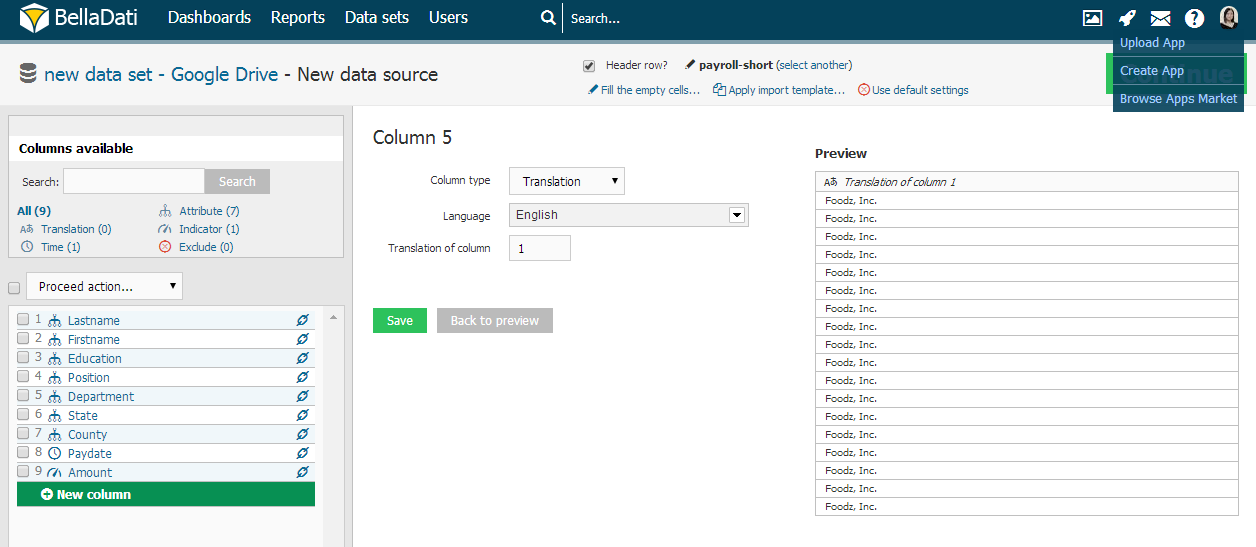
GEO-Punkt
Um den Längengrad auf das Attribut GEO Point abzubilden, müssen Sie den Breitengrad in einer Spalte im Format Breitengrad;Längengrad angeben, z.B. 43.56;99.32. Dezimaltrennzeichen ist . (Punkt). Du kannst es mit dem Transformationsskript tun, z.B. value(2) + ";" + value(1), falls der Längengrad in Spalte 1 und der Breitengrad in Spalte 2 gespeichert ist.
GEO JSON
Mit BellaDati können Sie GEO JSON direkt im Dataset verwenden. GEO JSON muss im Format wie folgt angegeben werden:
- {"geometry":{"coordinates":[[[38.792341,33.378686],[36.834062,32.312938],[35.719918,32.709192],[35.700798,32.716014],[35.836397,32.868123],[35.821101,33.277426],[38.792341,33.378686]]],"type":"Polygon"},"type":"Feature"}
- {"type": "FeatureCollection","features": [{ "type": "Feature","geometry": {"type": "Point", "coordinates": [102.0, 0.5]},"properties": {"prop0": "value0"}}]}
- { "type": "FeatureCollection","features": [{ "type": "Feature","geometry": {"type": "Point", "coordinates": [102.0, 0.5]},"properties": {"prop0": "value0"}},{ "type": "Feature","geometry": { "type": "LineString", "coordinates": [[102.0, 0.0], [103.0, 1.0], [104.0, 0.0], [105.0, 1.0]]},"properties": {"prop0": "value0","prop1": 0.0}},{ "type": "Feature","geometry": {"type": "Polygon","coordinates": [[ [100.0, 0.0], [101.0, 0.0], [101.0, 1.0],[100.0, 1.0], [100.0, 0.0] ]]},"properties": {"prop0": "value0","prop1": {"this": "that"}}}]}
- {"type":"Feature","geometry":{"type":"MultiPolygon","coordinates":[[[[120.715609,-10.239581],[138.668621,-7.320225],[102.498271,1.3987],[103.07684,0.561361],[103.838396,0.104542],[104.53949,-1.782372],[104.887893,-2.340425],[105.622111,-2.428844],[106.108593,-3.061777],[105.857446,-4.305525],[105.817655,-5.852356]]]]}}
Eigenschaften
Eigenschaften sind seit Version 2.9.1 verfügbar.
Für Attribute ist es möglich, deren Eigenschaften zu ändern:
Indexiert - Benutzer können die Indexierung jeder Spalte deaktivieren. Bitte beachten Sie, dass dies die Performance beeinträchtigen kann. Die Indexierung sollte für alle Spalten aktiviert werden, die für Drill-Downs und Aggregationen verwendet werden. Standardmäßig aktiviert.
Nicht nur leere Werte - durch Aktivieren dieser Option können Benutzer den Wert obligatorisch machen. Standardmäßig deaktiviert.
Füllen von leeren Zellen
Es ist üblich, dass importierte Daten leere Zellen enthalten. In der Regel ist es notwendig, diese leeren Zellen durch eigene Werte zu ersetzen (z.B. "0", "none", "N/A" etc.). Wenn Sie dies tun wollen, haben Sie zwei Möglichkeiten, wie Sie diese leeren Felder ausfüllen können:
global - füllt leere Zellen mit dem gewählten Wert in allen Spalten (befindet sich unter den Einstellungen der Batch-Spalte).
lokal - füllen Sie leere Zellen mit dem gewählten Wert in einer bestimmten Spalte (im Fenster mit den entsprechenden Spalteneinstellungen).
Die globale Änderung ist in der oberen blauen Zeile direkt unter den Kodierungseinstellungen verfügbar. Nach dem Anklicken geben Sie einfach den Wert ein, der in alle leeren Zellen Ihrer Daten eingetragen wird.
Lokale Änderungen sind nach Anklicken des Spaltennamens in der Liste möglich. Dort können Sie einen eigenen Wert für leere Zellen eingeben (aber nur für diese bestimmte Spalte). Sie können diese beiden Methoden einfach kombinieren - zum Beispiel können Sie alle leeren Zellen mit dem Wert "0" ausfüllen, aber eine bestimmte Attributspalte kann mit dem Wert "N/A" wieder gefüllt werden.
Spalten zusammenfügen
Die Funktion zum Zusammenführen von Spalten ermöglicht es, während des Importvorgangs Daten aus mehreren Quellspalten in eine Zielspalte zu laden.
Typische Anwendungsfälle sind:
Die Zeit ist in mehrere Spalten unterteilt (Tage, Monate und Jahre oder Zeit in verschiedenen Spalten).
Zwei Spalten, die eine Einheit darstellen (z.B. Vor- und Nachname einer Person)
Klicken Sie auf das Kettensymbol in der Spaltenliste, wählen Sie eine andere Spalte zum Zusammenführen und wählen Sie ein geeignetes Trennzeichen, das zwischen den Werten (Leerzeichen, Komma, Punkt, Semikolon, Rohr) hinzugefügt wird. Sie können auch zusammengeführte Spalten trennen.
Eine weitere Möglichkeit, Spalten zusammenzuführen und erweiterte Optionen einzurichten, besteht in der Verwendung von Transformationsskripten.
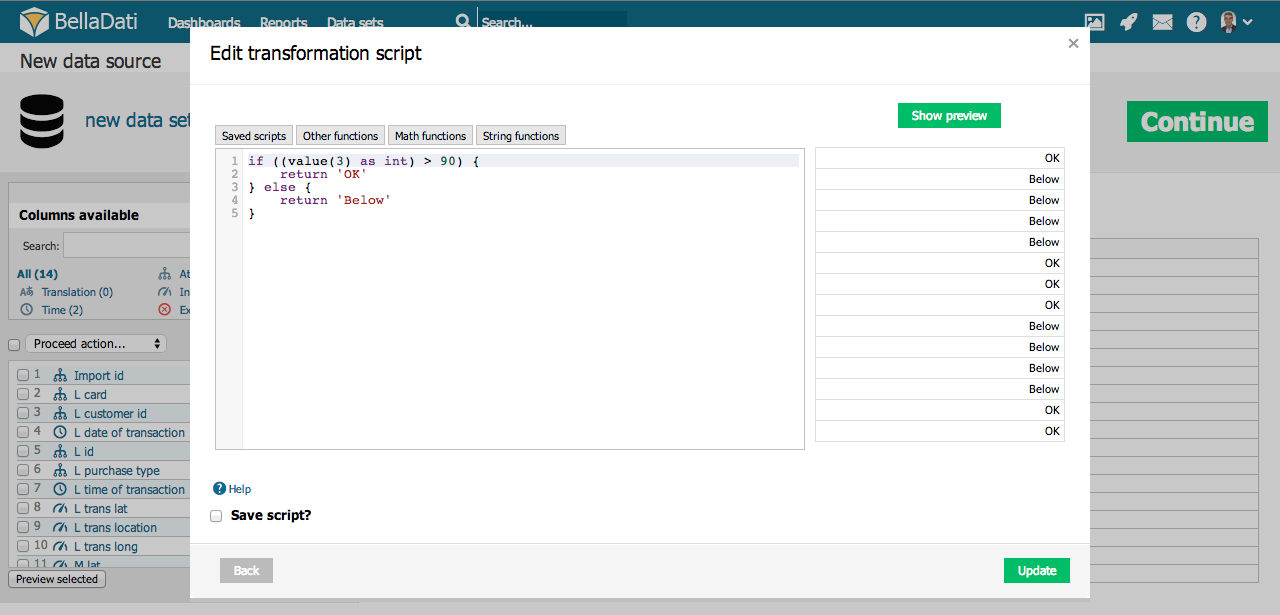
Transformationsskripte
Transformationsskripte ermöglichen erweiterte Datentransformationen während des Imports. Diese Skripte basieren auf der Syntax der Groovy-Programmiersprache.
Transformationsskripte ermöglichen Ihnen Folgendes:
Ändern Sie die im BellaDati Data Warehouse gespeicherten Werte entsprechend den definierten Funktionen und Bedingungen.
Erstellen Sie neue Spalten (Datum/Uhrzeit, Attribute, Kennzeichen) mit transformierten oder kombinierten Werten aus anderen Spalten. Werte in verschiedenen Zellen werden von 0 indiziert und in der Nähe von Spaltennamen im Importeinstellungsfenster angezeigt.
Führen Sie erweiterte Berechnungen in Datum/Uhrzeit durch (z.B. Zeitraum einer Aktion zwischen zwei Daten).
Grundlegende Skriptbefehle:
- value() - gibt den Istwert der aktuellen Zelle zurück
- value(index) - gibt den Wert der Zelle an der gewünschten (indizierten) Position in der aktuellen Zeile zurück.
- name() - gibt den Namen der Spalte zurück
- name(index) - gibt den Namen der Spalte an der gewünschten Position zurück
- format() - gibt den Wert des Formats in der aktuellen Spalte zurück (nur Zeit- und Indikatorspaltentypen
- actualDate() - gibt das aktuelle Datum im Format dd.MM.yyyyyyy zurück.
- actualDate('MM/dd/yyyy') - returns actual date in chosen format (e.g. MM/dd/yyyy)
- excludeRow() - schliept die Zeile
Diese Transformationen werden für jeden Import angewendet, einschließlich des geplanten automatischen Imports aus Datenquellen.
Weitere Informationen finden Sie im Leitfaden für Transformationsskripte.
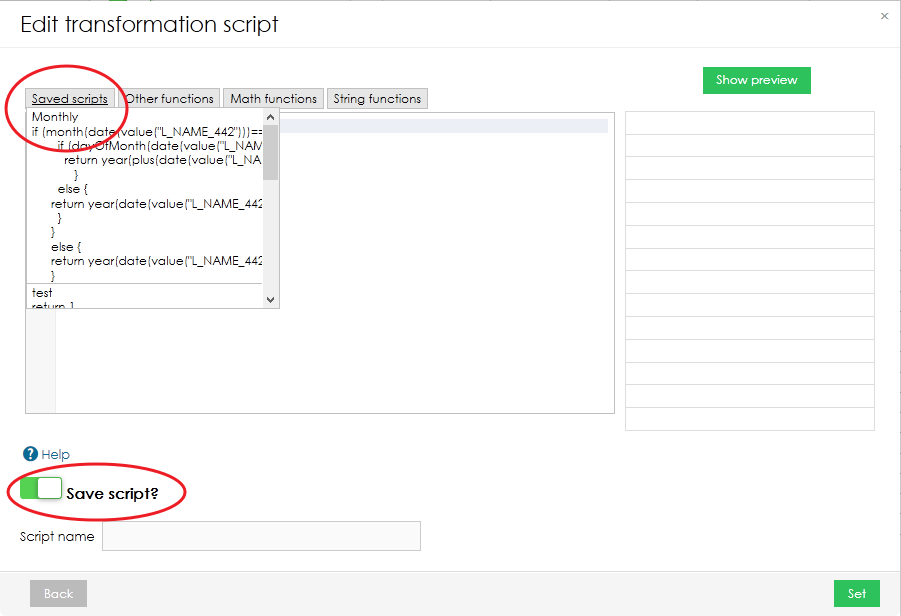
Wiederverwendung von Transformationsskripten
Wenn Sie wissen, dass Sie Ihr Skript in Zukunft wieder verwenden werden, können Sie es speichern, indem Sie den Schalter in der linken unteren Ecke wechseln. Ihre gespeicherten Skripte finden Sie im oberen Menü im Popup-Fenster "Transformationsskript bearbeiten".
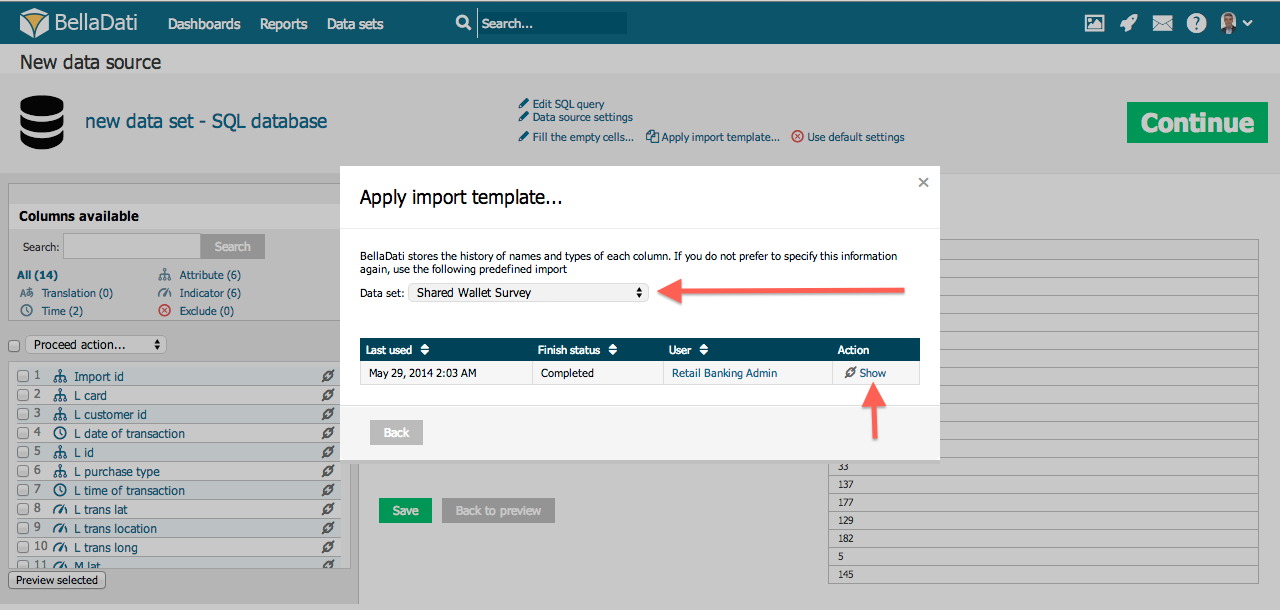
Vorlagen importieren
Mit dieser Funktion können Sie Importeinstellungen aus früheren Importen oder verschiedenen Datensätzen wiederverwenden. Sie ist verfügbar, indem Sie oben auf der Seite auf den Link "Vorlage importieren" klicken.
In dem Popup-Fenster können Sie:
- Datensatz auswählen
- Auswahl der diesem Datensatz zugeordneten Importvorlage nach Wunschdatum und Importstatus
- Details der Importvorlage anzeigen (Spalteneinstellungen)
- Importvorlagen sortieren
Durch das Anwenden der Vorlage werden alle aktuellen Importeinstellungen überschrieben.
Sie können aus allen vorhandenen Importeinstellungen wählen, die in allen Datensätzen verwendet werden, auf die Sie Zugriff haben. Diese Vorlagen werden automatisch erstellt, nachdem der Import erfolgreich abgeschlossen wurde.
Richtlinie zum Überschreiben von Daten
Wenn bereits Daten im Datensatz vorhanden sind, können Sie die folgenden Optionen wählen, was mit diesen Daten geschehen soll:
- Fügt Zeilen an den Datensatz an: Importierte Daten werden an bestehende angehängt (Standard).
- Alle Zeilen des Datensatzes löschen: Löscht alle Zeilen des Datensatzes (kann nur auf eine Datenquelle angewendet werden).
- Alle Zeilen basierend auf dem Datumsbereich löschen: Daten im ausgewählten Datumsbereich werden gelöscht.
- Löschen Sie Zeilen mit Daten, die mit der importierten Zeile identisch sind: Löscht alle vorhandenen Datensätze mit der gleichen Kombination von ausgewählten Attributen wie in den importierten Daten.
- Ersetzt Zeilen durch Daten, die mit importierten Zeilen identisch sind: ersetzt alle Datensätze mit der gleichen Kombination von ausgewählten Attributen wie in den importierten Daten.
Ersetzen Sie Zeilen durch Daten, die mit der importierten Zeile identisch sind.
Wenn Sie Daten durch Attribute ersetzen, ermöglicht Ihnen BellaDati folgendes:
wählen Sie Alle Attribute.
spezifische Attribute auswählen - der Importvorgang vergleicht die gewünschten Attribute und überschreibt die Zeile, wenn das aktuelle Attribut gleich dem bereits in der Datenbank gespeicherten Wert ist.
Zeilen mit Daten löschen, die mit der importierten Zeile identisch sind.
Wenn Sie Daten nach Attributen löschen, erlaubt Ihnen BellaDati dies:
wählen Sie Alle Attribute.
spezifische Attribute auswählen - der Importvorgang vergleicht die gewünschten Attribute und überschreibt die Zeile, wenn das aktuelle Attribut gleich dem bereits in der Datenbank gespeicherten Wert ist.
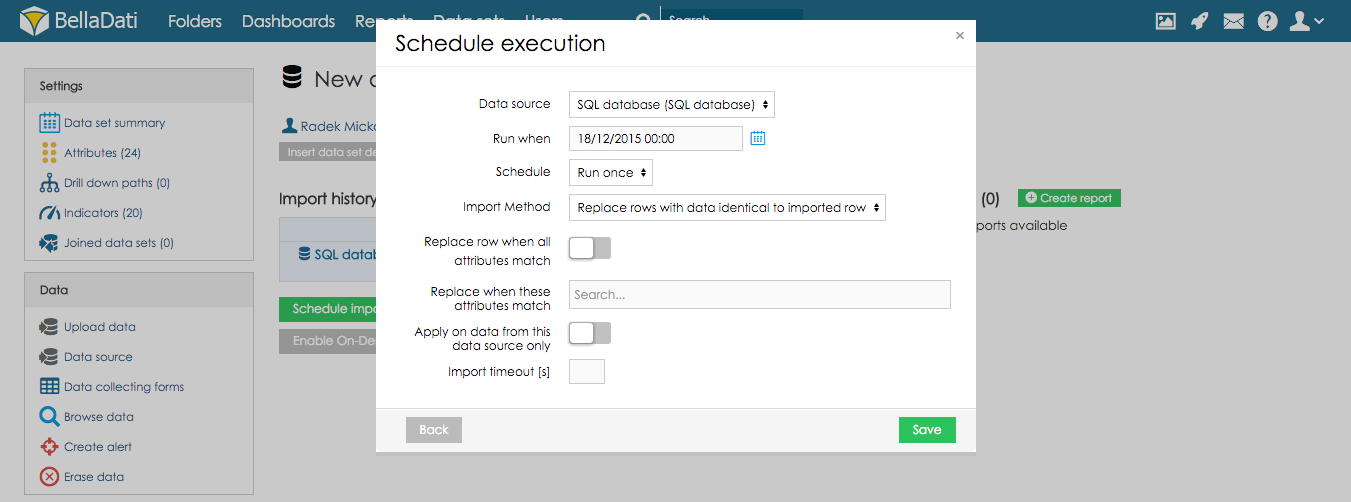
Diese Importmethode kann nur für die aus der ausgewählten Datenquelle importierten Daten angewendet werden.
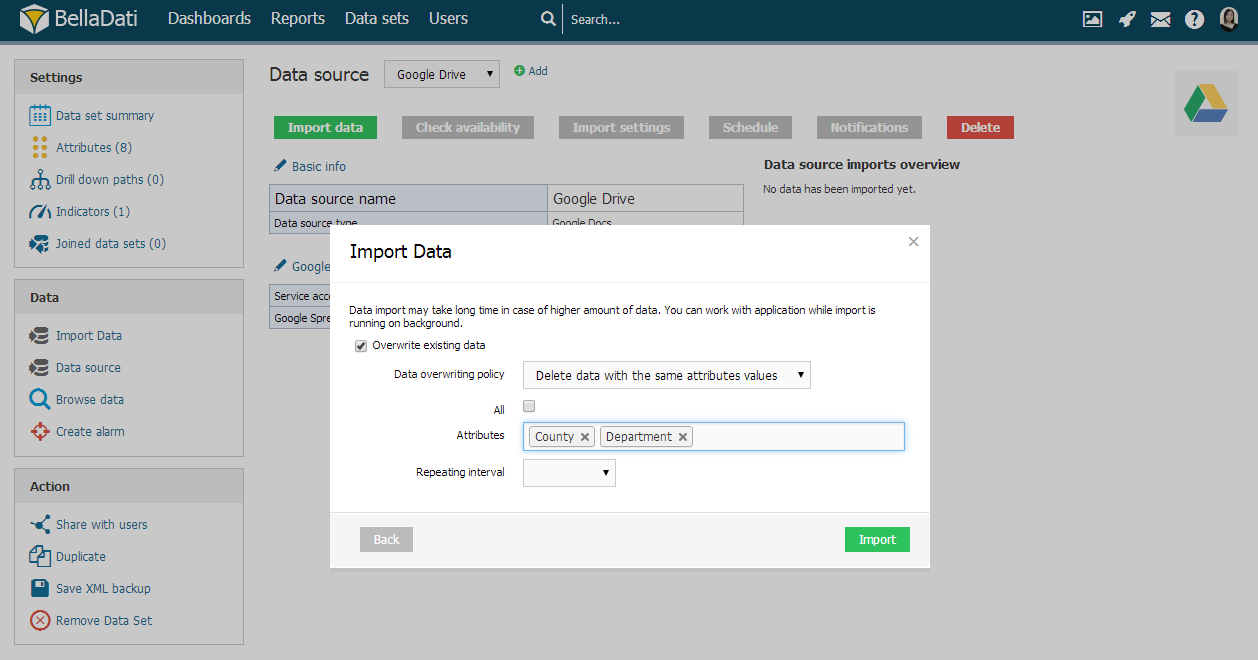
Diese Importmethode kann nur für die aus der ausgewählten Datenquelle importierten Daten angewendet werden.
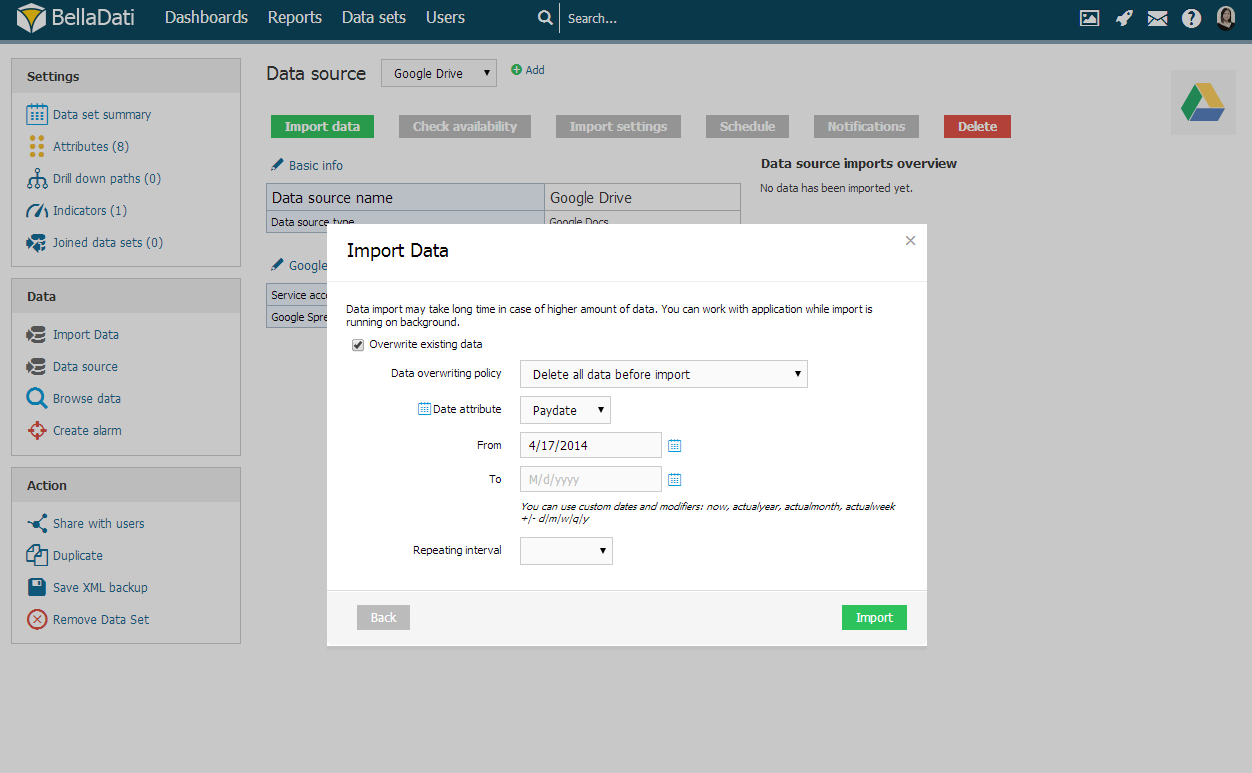
Alle Daten vor dem Import löschen
Wenn Sie alle Daten vor dem Import löschen, können Sie in BellaDati ein bestimmtes Zeitintervall auswählen. Einrichten von und bis, um das Löschen von Daten einzuschränken.
Verwenden Sie Kalendersymbole, um bequem die gewünschten Zeitintervalle auszuwählen.
Sie können benutzerdefinierte Daten und Modifikatoren verwenden: jetzt, aktuelles Jahr, aktueller Monat, aktuelle Woche +|- d|m|w|q|y.
Importfortschritt
Der Import von vielen Daten kann lange Zeit in Anspruch nehmen.
Die Daten werden asynchron importiert, so dass die BellaDati-Funktionen während des Imports weiterhin verfügbar sind. Der Benutzer kann auch während des Imports abgemeldet werden. Die Zusammenfassungsseite des Datensatzes zeigt den aktuellen Importfortschrittsbalken mit geschätzter Zeit und Prozentsatz.
Bevor der Import abgeschlossen ist, ist es möglich:
- Laufenden Import abbrechen: Alle Daten im Zusammenhang mit diesem Import werden aus dem BellaDati Data Warehouse gelöscht.
- Identität per E-Mail: Nach Abschluss des Imports erhalten Sie eine E-Mail.
Nächste Schritte
- Überprüfung der Importergebnisse nach dem Import
- Report erstellen
- Durchsuchen von Daten
- Transformationsskripting - detaillierte Anleitung
Overview
Content Tools