Stránka nastevení importu Vám umožňuje ovládať funkcie ETL (Extract-Transform-Load) a potvrdiť, štruktúru dát, podľa ktorej budú importované. Hlavným cieľom v nastaveniach importu je definovanie priradenia tabuľkových dát k atribútom, ukazovateľom a dimenziám času/ dátumu.
K dispozícii sú následné nastavenia:
- Prvý riadok je hlavička: Nastaví text v prvých riadkoch ako názov pre dané stĺpce; možnosť dostupná len pre Copy&Paste import, CSV alebo Excel
- Vylúčené riadky: Umožní Vám z importu vylúčiť stanovený počet riadkov rátaných od začiatku importovaného súboru (napríklad, dodatočné nedátove informácie); možnosť dostupná len pre Copy&Paste import, CSV alebo Excel
- Kódovanie: Vyberte vhodné kódovanie pre zdrojový súbor(UTF-8, ISO-8859-1, Win-1250, Win-1252, Auto); možnosť dostupná len pre Copy&Paste import, CSV alebo XML
- Oddelovač: Automatická detekcia (najčastejším býva bodkočiarka ";") alebo výber znamienka, ktoré oddeľuje jednotlivé stĺpce (čiarka, tab, bodkočiarka, medzerník, vertikála, definované uživateľom); možnosť dostupná len pre Copy&Paste import a CSV
- Vyplniť prázdne bunky: Všeobecne pre celý import, alebo pre jednotlivé stĺpce.
- Aplikovať vzor importu: Prejdite na kapitolu "vzory importu" nižšie.
- Použiť pôvodné nastavenia: Vykoná reset všetkých nastavení na ich pôvodné hodnoty.
Ďalšie funkcie sú:
- Čistenie dát a transformácia pomocou transformačných skriptov
- Pridelenie importovaných stĺpcov už existujúcim atribútom alebo ukazovateľom
- Premenovanie stĺpcov
- Spájanie stĺpcov
- Pridávanie nových stĺpcov
- Ukážka zmien
Automatické určenie kódovania, nie je vždy spoľahlivé. Odporúčame prezrieť náhľad a skontrolovať, či sa v ňom nenachádzajú nepožadované znaky.
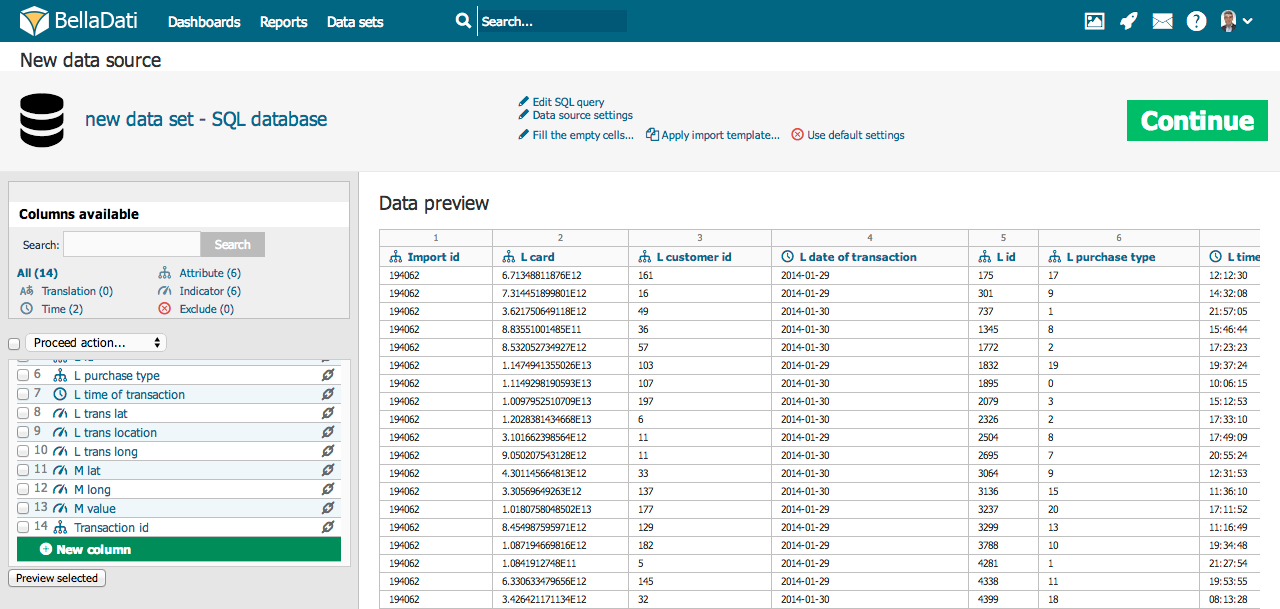
Dostupnosť nastavení zobrazených v obrázku vyššie sa môže líšiť v závislosti na formáte importovaného súboru. Vypísané nastavenia platia pre ručný import, pre informácie o automatizovaných importoch prejdite na zdroje dát.
Nastavenia stĺpcov
Ak chcete zmeniť typ daného stĺpca, kliknite na jeho meno v zozname stĺpcov (na ľavej strane okna). Taktiež je možné zmeniť typ viacerých stĺpcov zároveň - stačí vybrať požadované stĺpce pomocou checkboxov vedľa nich a vybrať cieľový typ z menu vyššie.
Existuje päť typov stĺpcov:
Čas/Dátum - časový index stĺpcov. Je možné ho zobraziť v množštve formátov (v závilosti na jazyku - pre viac informácií prejdite na relevantnú kapitolu na tejto stránke). V jednom importe je možné vybrať viacero stĺpcov pre čas/dátum.
Atribútu- Definuje kategórie pre preddefinované vetvenia. Zvyčajne sa jedná o krátky text (napr. mesto, štát, zákazník, divízia, produkt atď.). Každý stĺpec atribútu vytvorí len jeden atribút v skupine dát. Tieto atribúty je možné následne ľubovoľne kombinovať do preddefinovaných vetvení.
GEO bod - Môžete priradiť zemskú šírku/dĺžky jednotlivým GEO bodom, ktoré sú chápané ako typ atribútu. Tento atribút môže následne byť použitý v Reporte na zobrazenie konkrétnej lokácie priradených dát.
Preklad - Definuje preklad do jednotlivých jazykov pre stĺpec atribútu.
Ukazovateľ - Ukazovatele sú zvyčajne numerické dáta, ktoré sú hlavným bodom záujmu používateľa.
Neimportovať - Tieto stĺpce nebudú importované (vhodné v prípade, že stĺpec neobsahuje žiadne, nepodstatné alebo neplatné dáta).
Náhľad vybraných stĺpcov je možné zobraziť pomocou tlačítka "Zobraziť vybrané". Týmto spôsobom môžete získať lepší pohľad na Vaše dáta. V prípade, že Vaše dáta obsahujú priveľa stĺpcov, je možné ich vyhľadávať podľa názvu pomocou poľa na vyhľadávanie. Pod vyhľadávaním sú zobrazené štatistiky, ktoré zobrazujú počet jednotlivých typov stĺpcov.
Čas/dátum
Ak majú vaše zdrojové dáta hodnoty v čase alebo dátume, je možné ich priradiť do atribút Času alebo atribút Dátumu. Jeden stĺpec môže obsahovať aj čas aj dátum. napr. 5.4.2014 14:32:23. V tomto prípade bude dátum (5.4.2014) priradený k príslušnému atribútu dátumu a čas k atribútu času (14:32:23) - viz. obrázok nižšie.
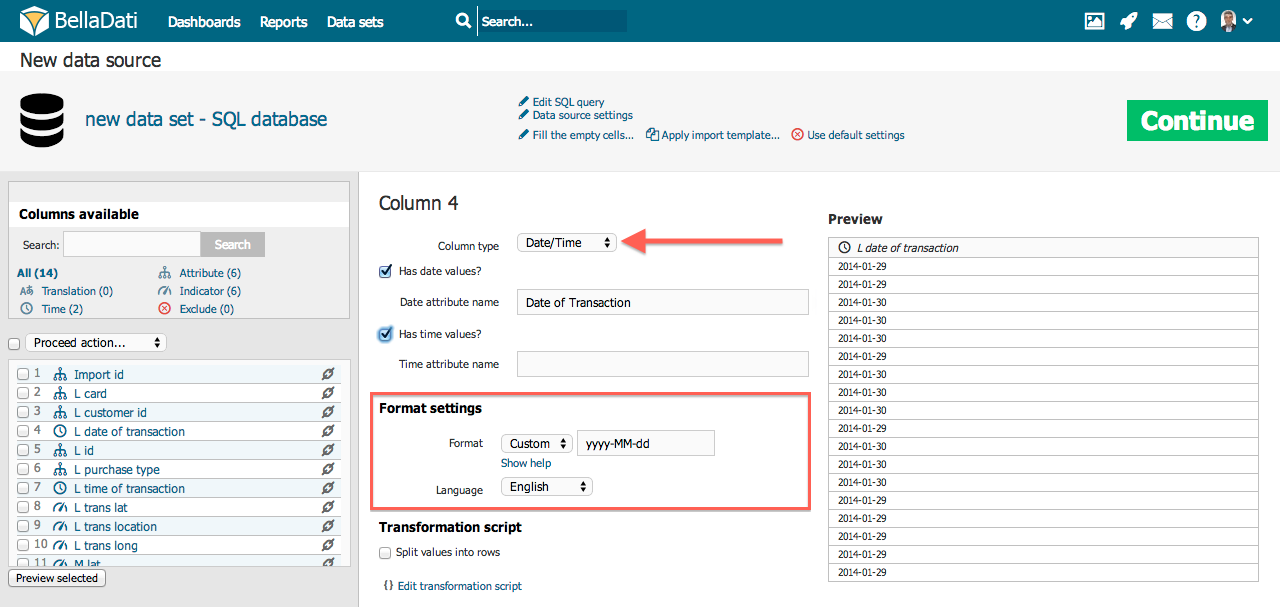
Formát dátumu a času
Každý časový stĺpec má vlastný formát. Tento formát by mal byť automatický identifikovaný počas importu. Avšak je možné, že máte dáta vo veľmi špecifickom formáte. V tomto prípade môžete použiť zoznam dostupných formátov v rozličných jazykoch alebo nastaviť svoj vlastný formát pomocou znakov zobrazených v nasledujúcej tabuľke (počet zadaných znakov ovplyvňuje spôsob akým bude kód chápaný):
Kód | Význam | Počet znakov v kóde |
|---|---|---|
y | Rok | Dva znaky (yy) predstavujú rok v dvoch číslach (89). V opačnom prípade je rok chápaný ako štvormiestne číslo (1989). |
M | Mesiac v roku | Tri alebo viac znakov (MMM) sú chápané ako textové označenie mesiaca (napr. Január alebo Jan). V opačnom prípade sú znaky chápané ako poradové čísla mesiaca v roku (1-12). |
d | Deň v mesiaci | Počet znakov (d) by mal byť rovnaký ako minimálny počet číslic v zdrojových dátach. Stále sa jedná o numerický formát. |
E | Deň v týždni | Počet znakov určuje, či bude mať deň zobrazený svoj plný názov (EEEE - "Pondelok") alebo len skratku (EE - "Po"). |
Znak oddeľovača by mal byť rovnaký ako ten, ktorý je v zdrojových dátach (medzera, bodka, čiarka, bodkočiarka. apod.). Ak Vaše zdrojové dáta obsahujú čas vo viacerých stĺpcov (jeden pre mesiac, deň, rok) je nevyhnutné tieto stĺpce najprv prepojiť (popísané v predchádzajúcej kapitole tejto časti). Nasledujúca tabuľka ukazuje niektoré kombinácie zdrojových dát a vhodných časových kódov.
Zdrojové dáta | Vhodný kód |
|---|---|
09/15/10 | MM.dd.yy |
26/03/1984 | dd/MM/yyyy |
15.September 2010 | dd.MMMM yyyy |
15 Sep 10 | dd MMM yy |
Str 15 09 10 | EE dd MM yy |
Sep 15, 2010 | MMM d, yyyy |
Preklad
BellaDati Vám umožňuje priamy import prekladu jednotlivých atribútov. Pre nastavenie prekladu prejdite na stĺpec s jazykovou metafrázou a:
- vyberte Preklad v type stĺpca
- vyberte jazyk prekladu
- určite index pôvodného stĺpca
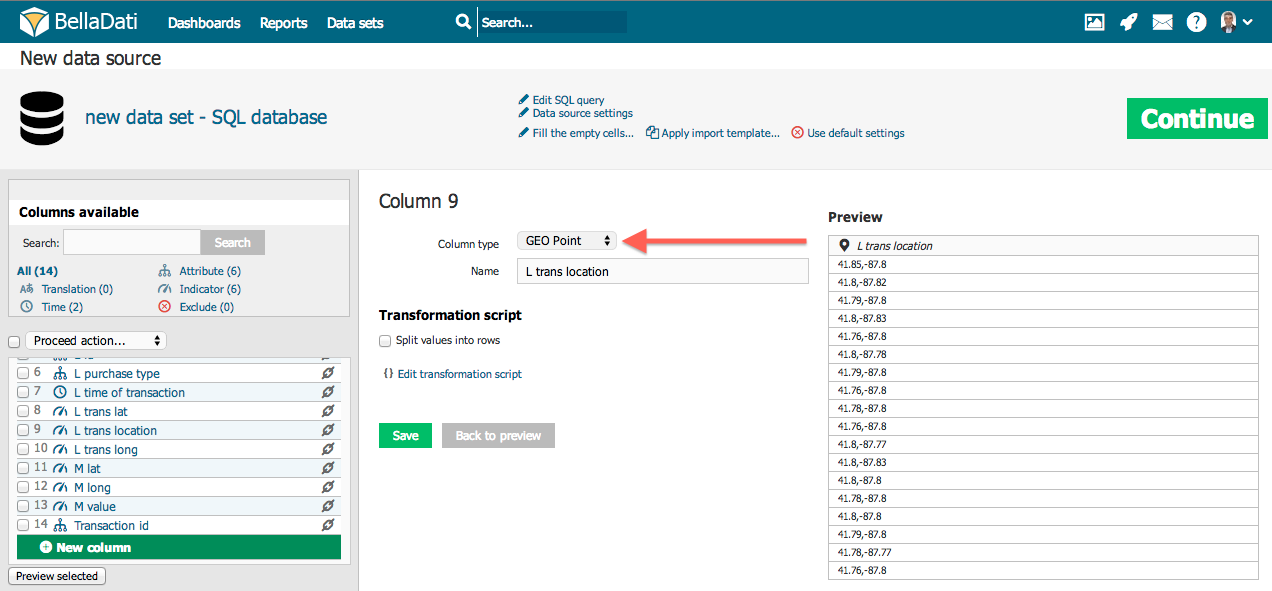
GEO bod
Pre priradenie zemskej šírky/dĺžka jednotlivým GEO atribútom, je nutné špecifikovať šírku/výšku v jednom stĺpci vo formáte šírka;dĺžka, napr. 99.32;43.56. Desatinný oddeľovač je . (bodka). V prípade, že sa dĺžka a šírka nachádzajú v rozdielnych stĺpcov je možné túto operáciu vykonať prostredníctvom transformačných skriptov, napr. value(1) + ";" value(2) (v prípade, že je šírka v stĺpci 1 a dĺžka v stĺpci 2).
Vyplnenie prázdnych buniek
Je bežné, že importované dáta obsahujú prázdne bunky. Zvyčajne je potrebné tieto prázdne bunky nahradiť vlastnými hodnotami (napr. "0", "žiadna", "N/A" a pod.). Túto operáciu je možné vykonať dvoma postupmi:
- globálne - vyplniť prázdne bunky vybranou hodnotou pre všetky stĺpce (dostupná na hornej lište nastavení). Stačí zadať požadovanú hodnotu a všetky prázdne bunky budú vyplnené
- lokálne - vyplniť prázdne bunky vybranou hodnotou len pre daný stĺpec (dostupná v nastaveniach vybraného stĺpca). Podobný postup ako pri globálnom nastavení - zadajte hodnotu, ktorá bude následne premietnutá do prázdnych buniek v danom stĺpci.
Je ľubovoľne možné kombinovať tieto dve metódy - napríklad vyplniť všetky prázdne bunky hodnotou "0" ale bunky v jednom konkrétnom atribúte môžete vyplniť hodnotou "N/A".
Spájanie stĺpcov
Funkcie spájania stĺpcov umožňuje nahrať dáta z viacerých zdrojových stĺpcov do jedného cieľového stĺpca, ktorý bude následne importovaný.
Typické prípady použitia sú:
- Čas je rozdelený do viacerých stĺpcov (dni, mesiace a roky v rozdielnych stĺpcoch)
- Dva stĺpce zastupujúce jednu entitu (meno a priezvisko jednej osoby)
Kliknite na ikonu reťaze v zozname stĺpcov, vyberte stĺpec, ktorý chcete spojiť a vhodný oddeľovač, ktorý bude pridaný medzi hodnoty (medzerník, čiarka, bodka atď.). Spojené stĺpce je následne možné rozdeliť.
Ďalším spôsobom ako spájať stĺpce sú transformačné skripty.
Transformačné skripty
Transformačné skripty umožňujú ransformation scripts allow advanced data transformations during import. These scripts are based on Groovy programming language syntax.
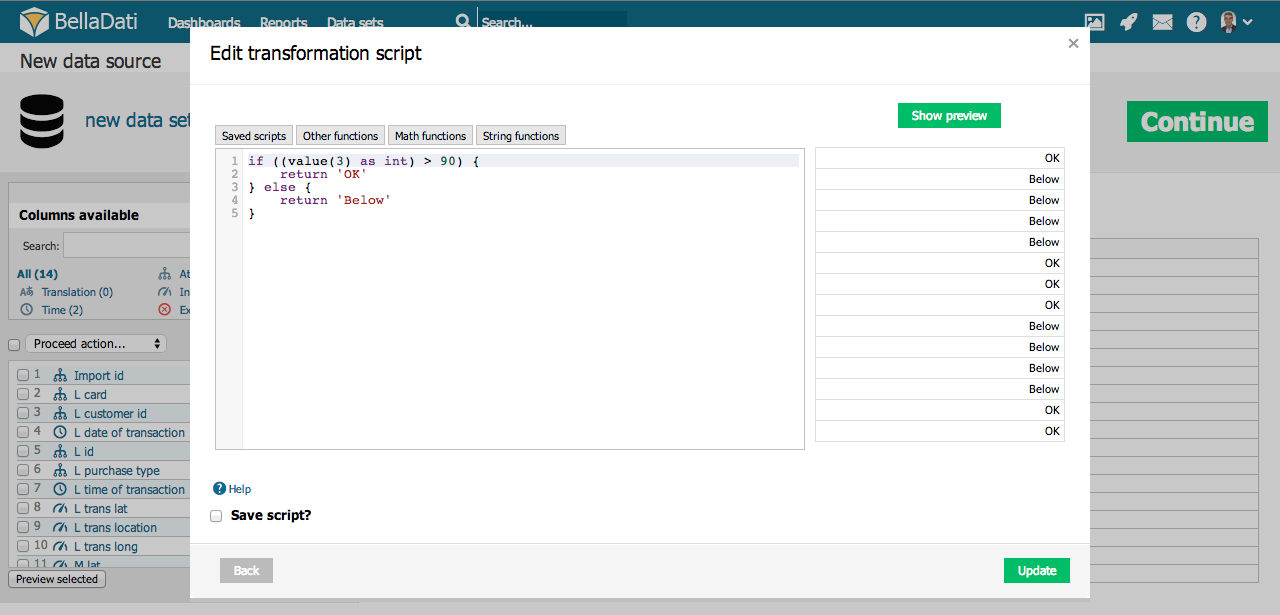
Transformačné skripty Vám umožnia:
- Modifikovať hodnoty uložené v dátovom sklade BellaDati podľa definovaných funkcií a podmienok.
- Vytvoriť nové stĺpce (dátum/čas, atribútu, ukazovatele) s transformovanými alebo kombinovanými hodnotami z ostatných stĺpcov. Hodnoty v iných bunkách sú indexované od nuly a zobrazené blízko názvov stĺpcov na stránke nastavení importu.
- Vykonať pokročilé výpočty v dátume/čase (napríklad periódu nejakej akcie vykonanej medzi dvoma dátumami).
Základné príkazy
- value() - vráti hodnotu aktuálne bunky
- value(index) - vráti hodnotu bunky v požadovanej (indexovanej) pozícii v danom riadku
- name() - vráti názov stĺpca
- name(index) - vráti názov stĺpca na požadovanej pozícii
- format() - vráti hodnotu formátu v aktuálnom stĺpci (iba pre časové a dátumové stĺpce)
- actualDate() - vráti hodnoty aktuálneho dátumu vo formáte dd.MM.yyyy
- actualDate('MM/dd/yyyy') - vráti aktuálny dátum vo vybranom formáte (napr. MM/dd/yyyy)
- excludeRow() - vynechá riadok
Tieto transformácie budú aplikované na každý import vrátane naplánovaných automatických importov zo Zdrojov dát.
Pre viac informácií navštívte sprievodcu transformačnými skriptami
Znovupoužitie transformačných skriptov
Previously defined transformation scripts can be invoked for your convenience. You can choose from any existing transformation scripts used in all data sets you have access to. Transformation script list is available after clicking on "Use existing script" link in column settings.
Vzory importu
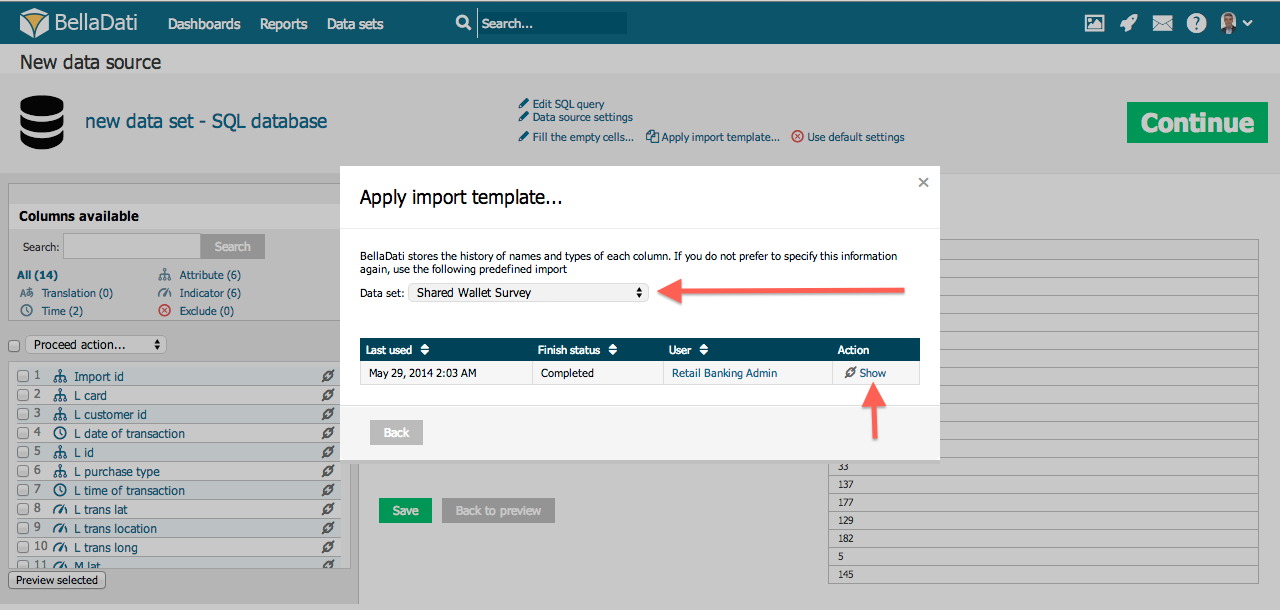
Táto funkcia Vám umožňuje znovupoužitie nastavení importu z predošlých importov alebo iných skupín dát. Je dostupná z odkazu "Aplikovať vzor importu" na hornej lište.
V nasledujúcom okne je možné:
- Vybrať skupinu dát
- Vybrať vzor importu pridelený tejto skupine dát podľa času a stavu importu
- Zobraziť detaily jednotlivých vzorov (nastavenia stĺpcov)
- Radiť jednotlivé vzory
Použite vzoru prepíše všetky doterajšie nastavenia
Môžete použiť všetky existujúce nastavenia importu vo všetkých skupinách dát, ku ktorým máte prístup. Tieto vzory sú vytvorené automaticky po každom úspešnom importe.
Nastavenie prepísania dát
V prípade, že sú v cieľovej skupine dát už prítomné nejaké dáta je možné použiť nasledujúce nastavenia upravujúce zaobchádzanie s týmito dátami:
- Bez prepisu: Importované dáta budú pridané k ostatným (pôvodné.
- Vymazať dáta s rovnakými hodnotami atribútov: Vymaže všetky existujúce záznamy, ktoré majú rovnakú kombináciu atribút ako importované dáta.
- Vymazať všetky dáta pred importom.
- Nahradiť riadky s identickými dátami.
Vymazať dáta s rovnakými hodnotami atribút
Pri takomto prepise Vám BellaDati umožňuje:
- Vybrať všetky atribúty
- Vybrať len určité atribúty - import porovná požadované atribúty a prepíše daný riadok ak je terajšia hodnota atribútu rovnaká ako tá uložená v databáze.
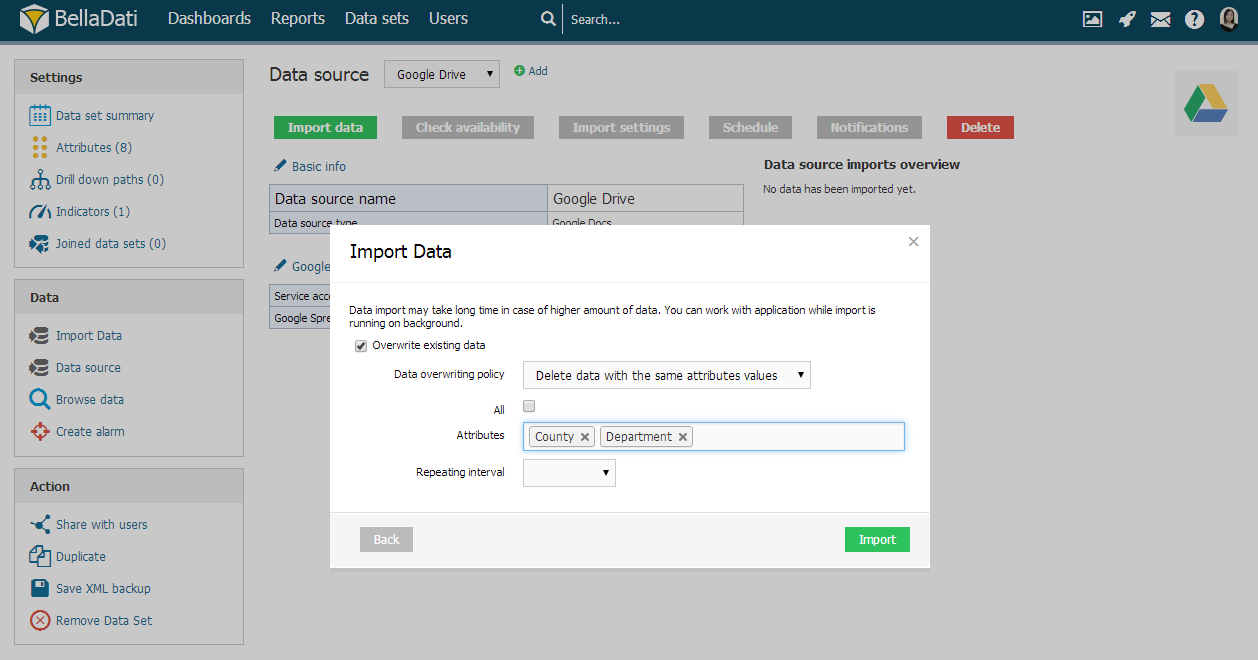
BellaDati Vám taktiež umožňuje aplikovať tieto nastavenia len pre dáta importované z vybraného zdroja dát:
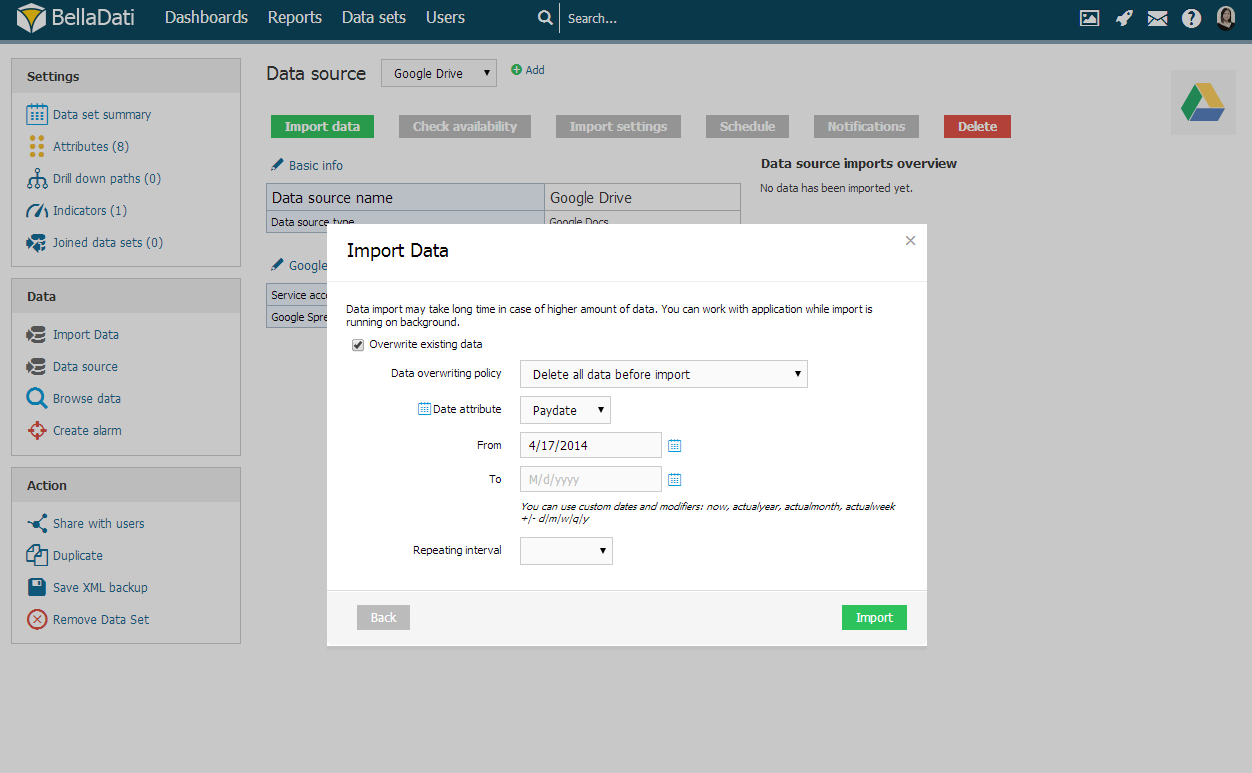
Vymazať všetky dáta
Pri mazaní všetkých dát pred importom Vám BellaDati umožňuje určite časový interval. Vyberte Od a Do pre určenie, ktoré dáta majú byť vymazané.
Pre komfortnejší výber požadovaných časových intervalov použite ikonky kalendár.
Môžete taktiež použite vlastné dátumy a premenné: now, actualyear, actualmonth, actualweek +|- d|m|w|q|y.
Postup importu
Import väčšieho množstvá dát môže trvať dlhšiu dobu.
Dáta sú importované asynchrónne, čo znamená, že ostatné funkcie BellaDati sú dostupné aj počas importu. Rovnako sa môžete počas importu aj odhlásiť.
Hlavná stránka danej skupiny dát ukazuje aktuálny stav importu s odhadovaným časom ukončenia a percentuálnym vyhodnotením.
Pred dokončením importu je možné:
- Zrušiť import: dáta z tohoto importu budú vymazané z dátového úložiska BellaDati.
- Upozorniť e-mailom: Po ukončení importu Vám bude zaslaný e-mail o tom, že bol import ukončený.
Kam ďalej
- Po importe prejdite na import results
- Create report
- Browsing data
- Transformation scripting - detailed guide
Overview
Content Tools