Partitionierung ist seit BellaDati 2.9 verfügbar.
Die Partitionierung ermöglicht es, Datasetdaten in Partitionen zu speichern, um die Leistung mit mehr Daten zu steigern.
Einrichten der Partitionierung
Bitte beachten Sie, dass die Partitionierungsfunktionalität in der Lizenz und in der Domäne aktiviert sein muss.
Nur der Domänenadministrator kann auf die Partitionierungseinstellungen zugreifen.
BellaDati muss PostgreSQL Version 9.4 oder neuer verwenden, wenn der Dataset lokalen Speicher verwendet.
Postgres Version 9.4 oder neuer ist erforderlich, wenn der Dataset einen Remote-Speicher verwendet.
Der Remote-Speicher kann eingerichtet werden, indem Sie die Partitionierung im Menü Einstellungen auf der Detailseite Dataset öffnen und auf die Schaltfläche Konfigurieren klicken.
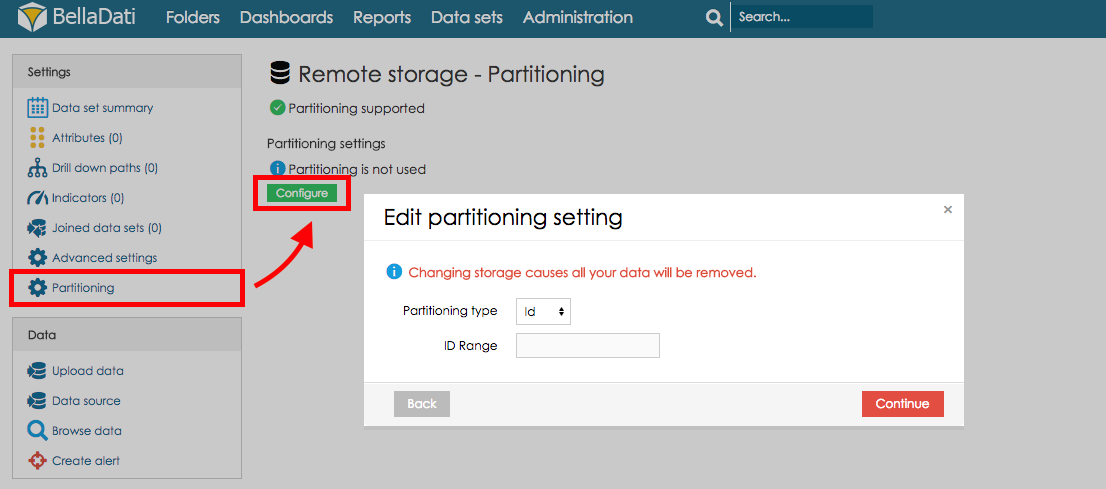
Das Einrichten oder Entfernen der Partitionierung entfernt alle Daten im Dataset. Attribute, Kennzeichen und alle anderen Einstellungen bleiben unverändert.
Im nächsten Schritt kann der Partitionierungstyp ausgewählt werden:
ID
By defining ID Range the data in this data set will be stored in partitions where each partition will contain number of records defined as the ID Range.
z.B: Durch das Setzen des ID-Bereichs auf 1000 und das Importieren von Daten mit 10 000 Datensätzen werden die Daten im Dataset in 10 Partitionen mit jeweils 1000 Datensätzen gespeichert.
Zeit
Wenn importierte Daten Zeitinformationen enthalten, die als Datum oder Datumsattribut gespeichert sind, können sie für die Partitionierung verwendet werden.
Attribute, die für die Partitionierung verwendet werden, müssen so angelegt werden, dass nicht nur leere Werte aktiviert sind.
Mit der Auswahl von Partitionierungsintervall legen Sie fest, wie die Daten in Partitionen platziert werden sollen.
z.B: Durch die Verwendung des jährlichen Partitionsintervalls und den Import von Daten für die Jahre 2006 - 2015 werden die Daten in 10 Partitionen gespeichert, die jeweils Datensätze für ein Jahr enthalten.
Overview
Content Tools