Pipelines in BellaDati ML Studio can be used to combine multiple projects into one larger workflow. They support triggering by data change, scheduling, manual execution, and parallel execution. Each pipeline can consist of one of more stages. And each stage can consist of one or more projects.
Creating new pipeline
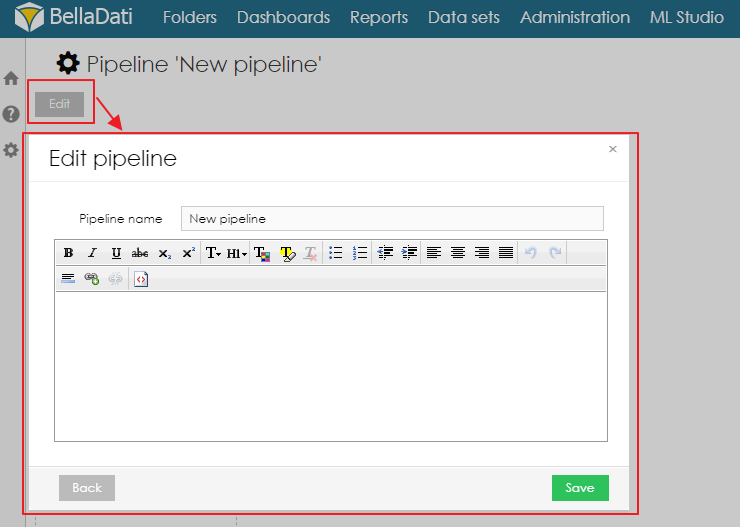
A new pipeline can be created from the ML Studio Welcome screen by clicking on button Create pipeline. A new empty pipeline without any staged in created. The user can change the name and description of the pipeline by clicking on button Edit.
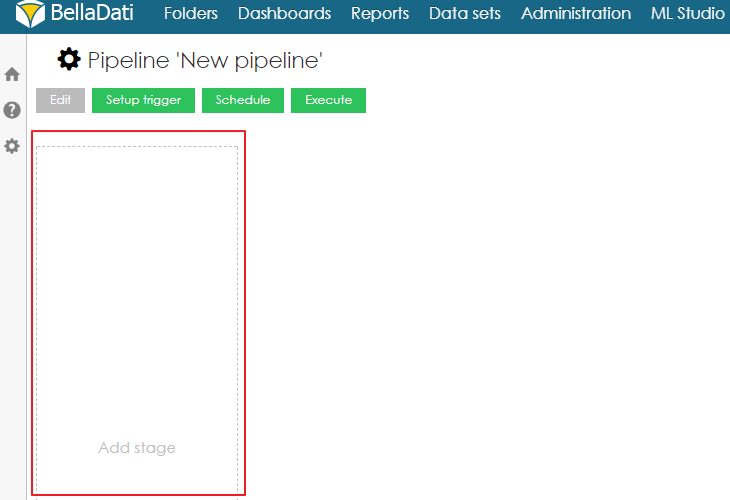
To be able to add projects to a pipeline, the user first needs to add a stage. A stage can be added by clicking on the empty space with label Add stage.
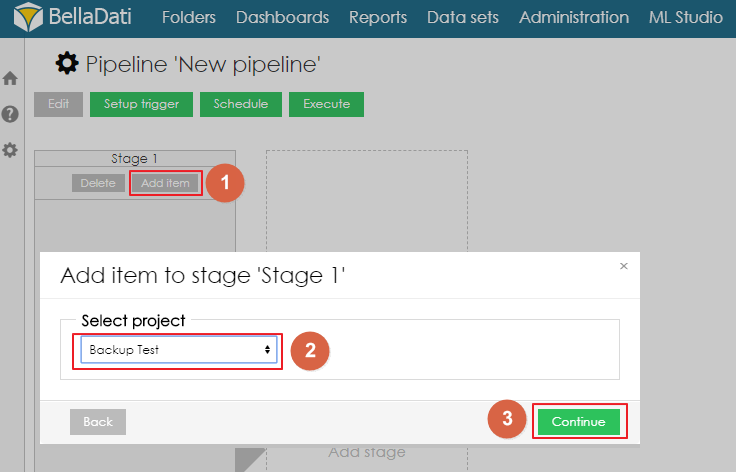
Each stage can have its own name and can contain one or more projects. Projects inside one stage can be executed sequentially or parallelly. Projects can be added to the stage by clicking on a button Add item. A pop-up window with a list of all available projects is displayed. After selecting the correct project, the user needs to click on Continue to add the project to the stage.
Each project added to a stage has following options:
- Parameters - When parameters are defined inside the project, their value can be changed directly from the pipeline. Users can, for example, select used data set.
- Runtime options
Continue on error? - Defines the behavior of the pipeline in case the execution of the project ends with an error. When this option is disabled (default state), the whole pipeline will end with an error. When enabled, the pipeline will continue with the execution of next project.
- Execute parallel? - Disabled by default. When disabled, each project is executed only after the execution of the previous one has been finished. When enabled, the project is run in the background and multiple projects can be run parallelly.
Timeout [s] - Defines the error timeout in seconds.
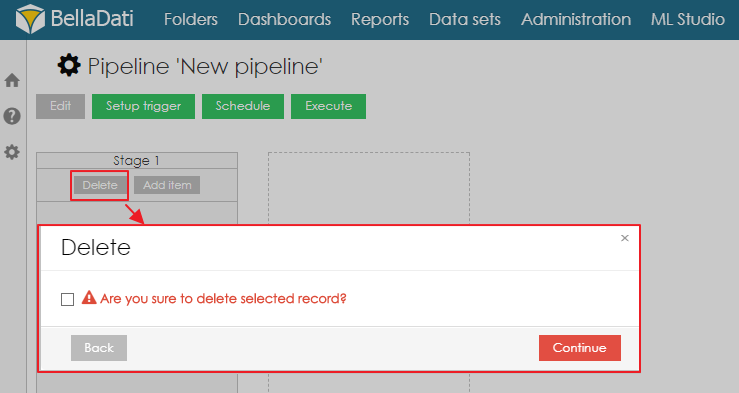
A stage can be also deleted by clicking on button Delete.
Executing pipeline
A pipeline can be executed three different ways.
- Trigger - Pipeline will be executed after a change in selected data set.
- Schedule - iPipelne will be executed at scheduled time.
- Manual execution - Pipeline will be executed immediately after clicking on the button Execute.
Deleting pipeline
Pipeline can be deleted from the Edit window.
Overview
Content Tools