Page History
...
| Sv translation | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Column Settings
Wenn Sie den Typ einer bestimmten Spalte ändern möchten, klicken Sie auf den Namen der ausgewählten Spalte in der Liste der Spalten (auf der linken Seite des Importbildschirms). Es ist auch möglich, die Bedeutung mehrerer Spalten in nur einem Schritt auf einen Typ zu ändern - markieren Sie einfach ausgewählte Spalten, indem Sie auf die Kontrollkästchen neben ihnen klicken und dann ihre Bedeutung aus dem Menü oben auswählen. Es gibt acht mögliche Bedeutungen von Spalten (Datentypen): Datum/Uhrzeit (separat) - Zeitindex bestimmter Zeilen. Es kann in vielen verschiedenen Zeitformaten angezeigt werden (auch sprachabhängig - weitere Informationen finden Sie im entsprechenden Teil dieses Kapitels). Sie können mehrere Datums-/Uhrzeitspalten im Einzelimport auswählen. Datum/Uhrzeit - Datumszeitindex bestimmter Zeilen. Es kann in vielen verschiedenen Datumsformaten angezeigt werden (auch sprachabhängig - weitere Informationen finden Sie im entsprechenden Teil dieses Kapitels). Sie können mehrere Datetime-Spalten im Einzelimport auswählen. Langtext - definiert Langtext - Beschreibung. Dieser Spaltentyp sollte für Spalten verwendet werden, die Werte mit einer Länge von mehr als 220 Zeichen enthalten. Kann nicht in den Visualisierungen und Aggregationen verwendet werden. Geeignet für folgende Anwendungsfälle:
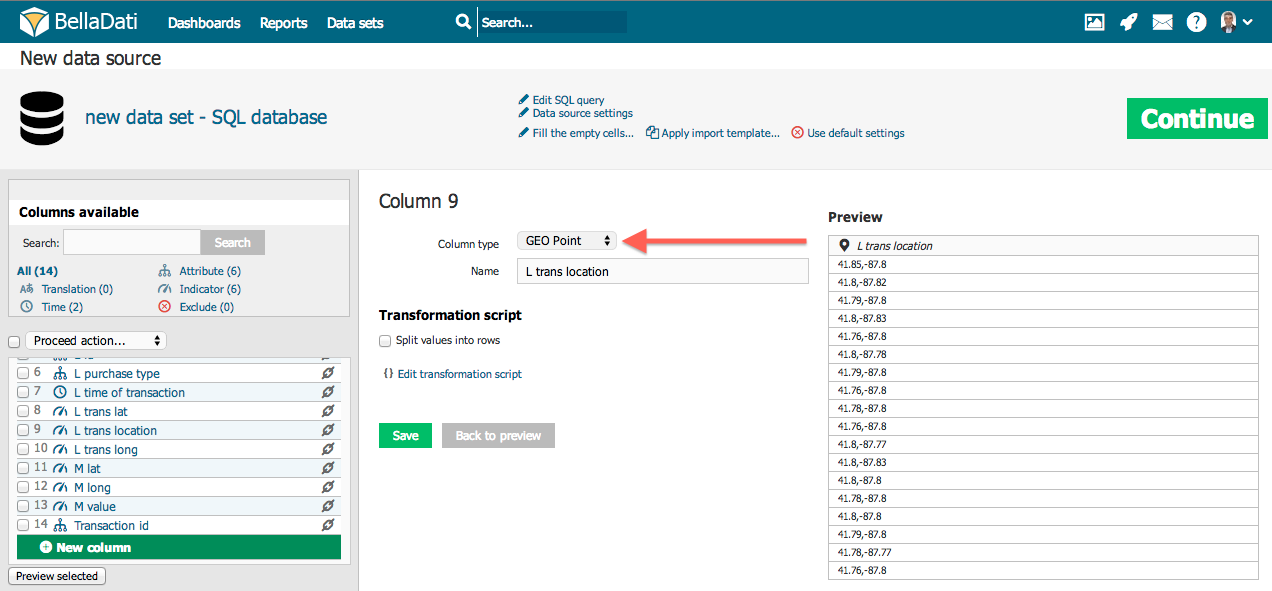
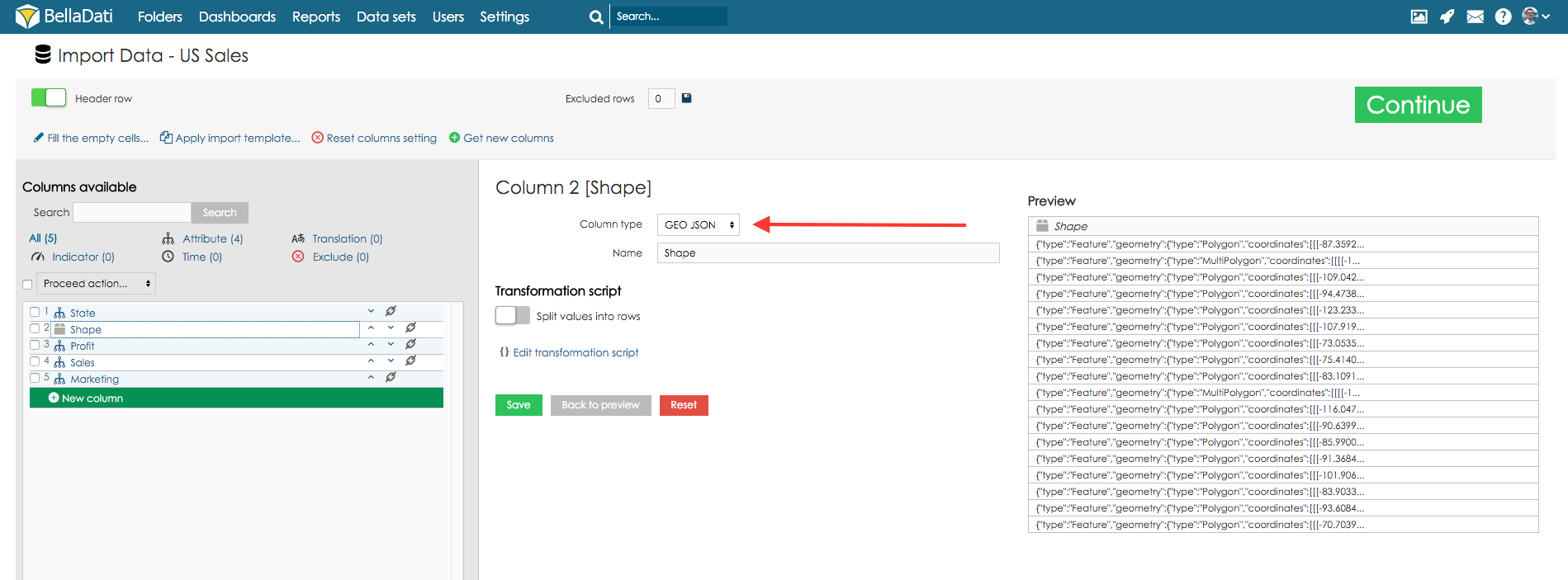
Attribut - definiert Kategorien des Drill-Down-Pfades. Es handelt sich in der Regel um einen kurzen Text (z.B. Affiliate, Produkt, Kunde, Mitarbeiter, Abteilung etc.). Jede Attributspalte erzeugt genau ein Attribut im DatensatzDataset. Diese Attribute können in den Drill-Down-Pfaden frei kombiniert werden. GEO Point - Sie können den Breitengrad/Längengrad auf den Attributtyp GEO Point abbilden. Dieses Attribut kann dann im Ansichtstyp Geokarte verwendet werden, um Daten an ihrer jeweiligen Position darzustellen. GEO JSON - Sie können die Form auf den Attributtyp GEO JSON abbilden. Dieses Attribut kann dann im Ansichtstyp Geokarte verwendet werden, um Daten an ihre bestimmte Position zu plotten, die als Form angezeigt wird. Übersetzung - definiert die Sprachübersetzung einer anderen Spalte, die als Attribut identifiziert wird. Indikator - Indikatoren sind in der Regel die numerischen Daten, die den Schwerpunkt des Interesses des Benutzers bilden. Nicht importieren - diese Spalten werden überhaupt nicht importiert (nützlich, wenn die Spalte keine, ungültige oder unwichtige Daten enthält). Datum/ UhrzeitWenn Ihre Quelldaten Datetime-Werte enthalten, können Sie diese auf das Attribut Datum/ Uhrzeit abbilden. Diese einzelne Spalte enthält sowohl Datum als auch Uhrzeit, z.B. 5 Apr 2014 10:43:43:43 AM. Siehe folgendes Beispiel:
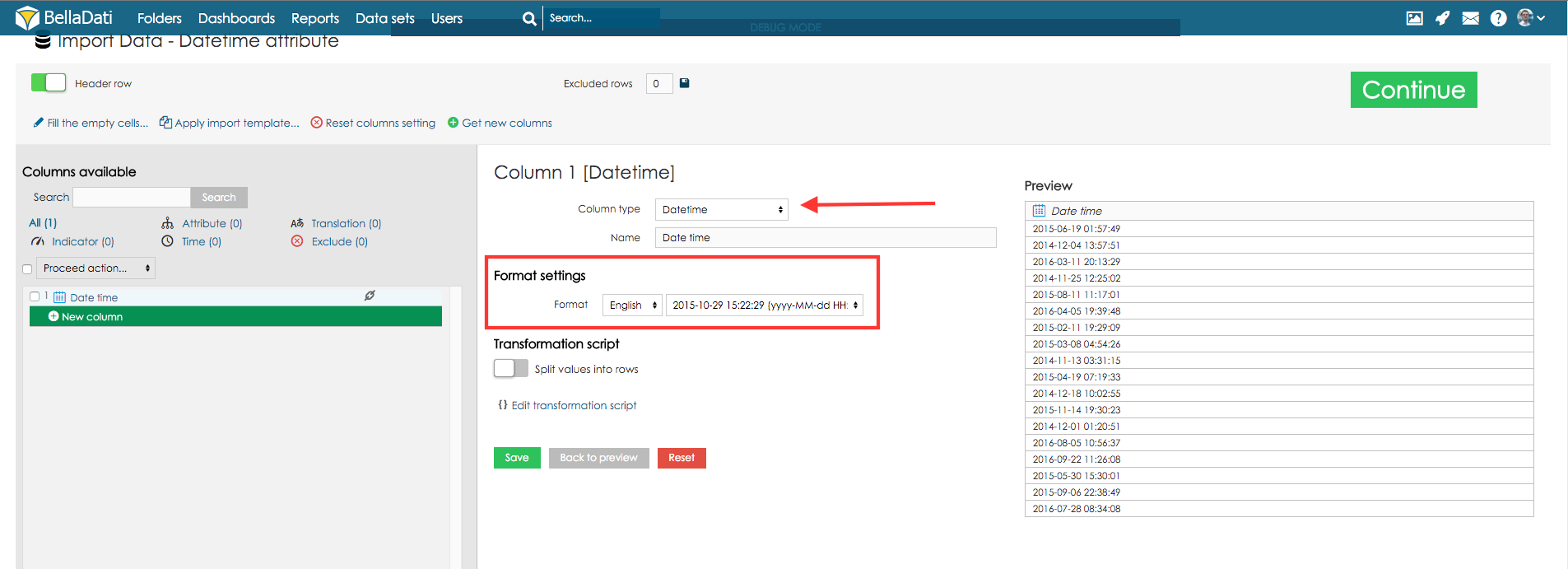
Datum/ Uhrzeit FormatJede Spalte hat eine bestimmte Art von Format. Dieses Format sollte beim Import automatisch erkannt werden. Es ist jedoch möglich, dass Sie Ihre Zeitangaben in einem sehr spezifischen Format haben. In diesem Fall können Sie die Liste der verfügbaren Formate in verschiedenen Sprachen verwenden. Wenn Sie nicht aus den verfügbaren Formaten wählen, können Sie auch Ihr eigenes, spezielles Format für Ihre Daten definieren. In diesem Fall sollten Sie Ihre Sprache aus der folgenden Liste auswählen und einen Code eingeben, der Ihr Datenformat entsprechend dieser Bedeutung beschreibt (beachten Sie, dass die Anzahl der Zeichen die Interpretation des Codes beeinflusst):
Das Trennzeichen sollte gleich dem Trennzeichen in den Quelldaten (Leerzeichen, Punkt, Semikolon, etc.) sein. Wenn Ihre Quelldaten Zeit in getrennteren Spalten (Monate, Tage, Jahre) enthalten, ist es notwendig, diese Spalten zuerst zusammenzuführen (wie im vorherigen Teil dieses Kapitels beschrieben). Die nächste Tabelle zeigt eine Kombination aus Quelldaten und entsprechendem Timecode.
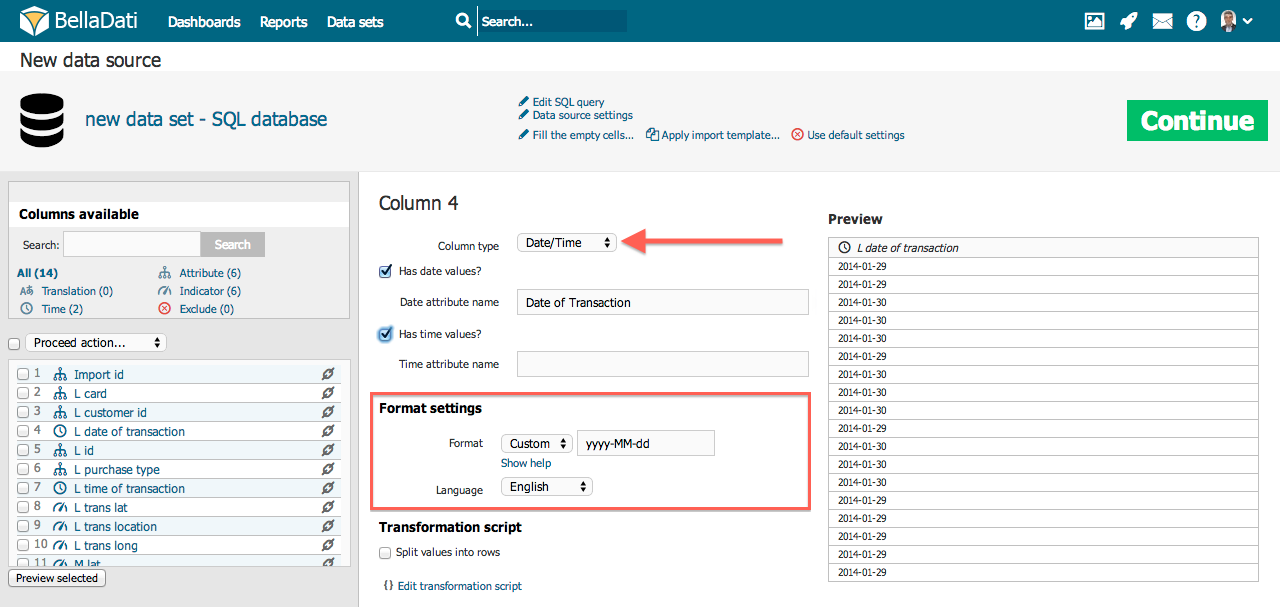
Datum/ UhrzeitWenn Ihre Quelldaten Datums-/Uhrzeitwerte enthalten, können Sie diese den entsprechenden Datums- oder Zeitattributen zuordnen. Eine einzelne Spalte kann sowohl Datum als auch Uhrzeit enthalten, z.B. 5 Apr 2014 10:43:43:43 AM. In diesem Fall wird der Datumsteil, 5. April 2014, auf das Datumsattribut abgebildet, der Zeitteil, 10:43:43 AM auf das Zeitattribut. Siehe folgendes Beispiel:
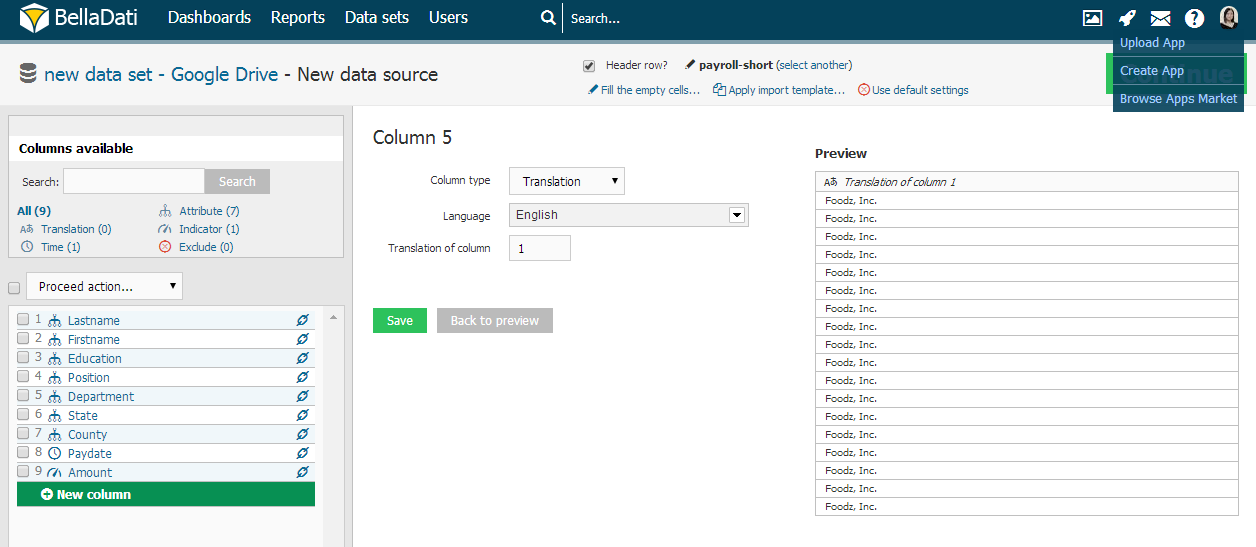
Die Definition des Datums-/Zeitformats ist die gleiche wie für die Spalte Datun/ Uhrzeit. ÜbersetzungMit BellaDati können Sie Attributübersetzungen direkt importieren. Um die Attributübersetzung einzurichten, navigieren Sie zur Spalte mit der Sprachmetaphrase und:
GEO-PunktUm den Längengrad auf das Attribut GEO Point abzubilden, müssen Sie den Breitengrad in einer Spalte im Format Breitengrad;Längengrad angeben, z.B. 43.56;99.32. Dezimaltrennzeichen ist . (Punkt). Du kannst es mit dem Transformationsskript tun, z.B. value(2) + ";" + value(1), falls der Längengrad in Spalte 1 und der Breitengrad in Spalte 2 gespeichert ist. |
| Note |
|---|
Eigenschaften sind seit Version 2.9.1 verfügbar. |
For attributes, it is possible to change their properties:
Indexiert - Benutzer können die Indexierung jeder Spalte deaktivieren. Bitte beachten Sie, dass dies die Performance beeinträchtigen kann. Die Indexierung sollte für alle Spalten aktiviert werden, die für Drill-Downs und Aggregationen verwendet werden. Standardmäßig aktiviert.
Nicht nur leere Werte - durch Aktivieren dieser Option können Benutzer den Wert obligatorisch machen. Standardmäßig deaktiviert.
Füllen von leeren Zellen
Es ist üblich, dass importierte Daten leere Zellen enthalten. In der Regel ist es notwendig, diese leeren Zellen durch eigene Werte zu ersetzen (z.B. "0", "none", "N/A" etc.). Wenn Sie dies tun wollen, haben Sie zwei Möglichkeiten, wie Sie diese leeren Felder ausfüllen können:
global - füllt leere Zellen mit dem gewählten Wert in allen Spalten (befindet sich unter den Einstellungen der Batch-Spalte).
lokal - füllen Sie leere Zellen mit dem gewählten Wert in einer bestimmten Spalte (im Fenster mit den entsprechenden Spalteneinstellungen).
Die globale Änderung ist in der oberen blauen Zeile direkt unter den Kodierungseinstellungen verfügbar. Nach dem Anklicken geben Sie einfach den Wert ein, der in alle leeren Zellen Ihrer Daten eingetragen wird.
Lokale Änderungen sind nach Anklicken des Spaltennamens in der Liste möglich. Dort können Sie einen eigenen Wert für leere Zellen eingeben (aber nur für diese bestimmte Spalte). Sie können diese beiden Methoden einfach kombinieren - zum Beispiel können Sie alle leeren Zellen mit dem Wert "0" ausfüllen, aber eine bestimmte Attributspalte kann mit dem Wert "N/A" wieder gefüllt werden.
Merging Columns
Die Funktion zum Zusammenführen von Spalten ermöglicht es, während des Importvorgangs Daten aus mehreren Quellspalten in eine Zielspalte zu laden.
Typische Anwendungsfälle sind:
Die Zeit ist in mehrere Spalten unterteilt (Tage, Monate und Jahre oder Zeit in verschiedenen Spalten).
Zwei Spalten, die eine Einheit darstellen (z.B. Vor- und Nachname einer Person)
Klicken Sie auf das Kettensymbol in der Spaltenliste, wählen Sie eine andere Spalte zum Zusammenführen und wählen Sie ein geeignetes Trennzeichen, das zwischen den Werten (Leerzeichen, Komma, Punkt, Semikolon, Rohr) hinzugefügt wird. Sie können auch zusammengeführte Spalten trennen.
Eine weitere Möglichkeit, Spalten zusammenzuführen und erweiterte Optionen einzurichten, besteht in der Verwendung von Transformationsskripten.
Transformationsskripte
Transformationsskripte ermöglichen erweiterte Datentransformationen während des Imports. Diese Skripte basieren auf der Syntax der Groovy-Programmiersprache.
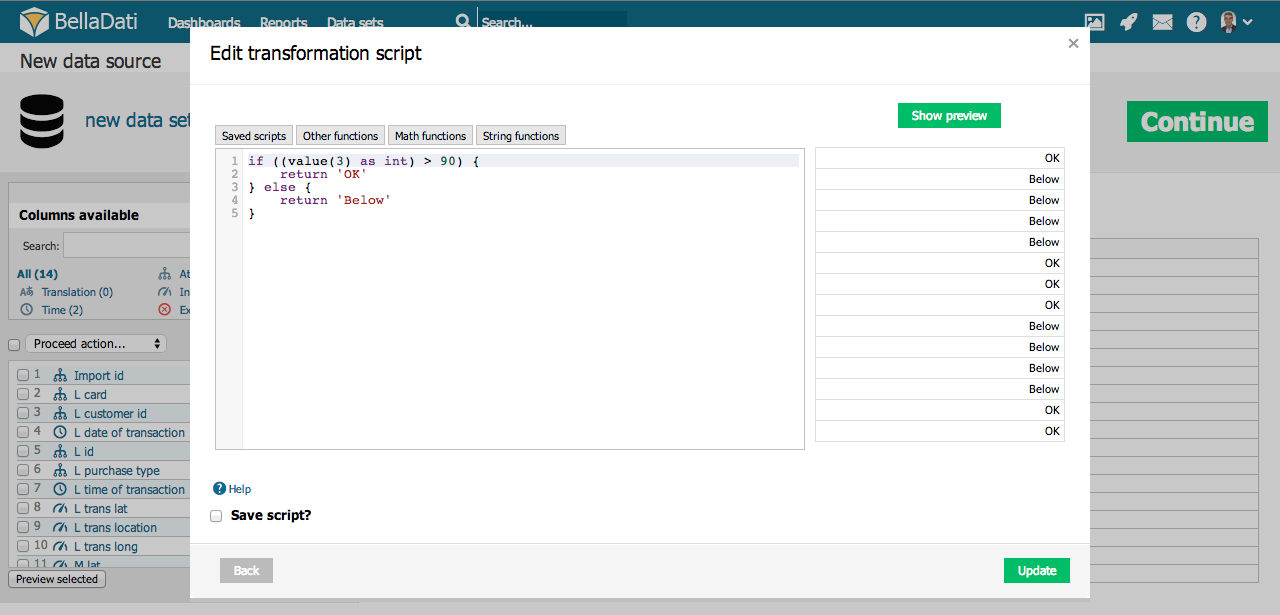
Transformationsskripte ermöglichen Ihnen Folgendes:
Ändern Sie die im BellaDati Data Warehouse gespeicherten Werte entsprechend den definierten Funktionen und Bedingungen.
Erstellen Sie neue Spalten (Datum/Uhrzeit, Attribute, Kennzeichen) mit transformierten oder kombinierten Werten aus anderen Spalten. Werte in verschiedenen Zellen werden von 0 indiziert und in der Nähe von Spaltennamen im Importeinstellungsfenster angezeigt.
Führen Sie erweiterte Berechnungen in Datum/Uhrzeit durch (z.B. Zeitraum einer Aktion zwischen zwei Daten).
Grundlegende Skriptbefehle:
- Wert() -gibt den Istwert der aktuellen Zelle zurück
- Wert(index) - gibt den Wert der Zelle an der gewünschten (indizierten) Position in der aktuellen Zeile zurück.
- Name() - gibt den Namen der Spalte zurück
- Name(index) - gibt den Namen der Spalte an der gewünschten Position zurück
- Format() - gibt den Wert des Formats in der aktuellen Spalte zurück (nur Zeit- und Indikatorspaltentypen
- AkutellesDatum() - gibt das aktuelle Datum im Format dd.MM.yyyyyyy zurück.
- AktuellesDatum('MM/dd/yyyy') - returns actual date in chosen format (e.g. MM/dd/yyyy)
- Zeilenausschließen() - schliept die Zeile
| Info |
|---|
Diese Transformationen werden für jeden Import angewendet, einschließlich des geplanten automatischen Imports aus Datenquellen. |
Go to Transformation scripting guide for more details.
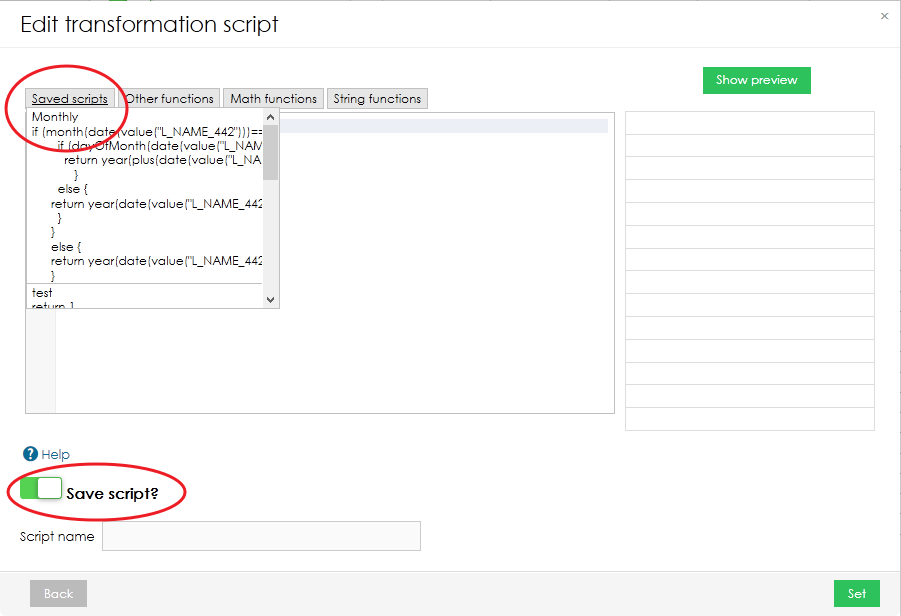
Reusing Transformation Scripts
If you know that you are going to use your script again in the future, you can save it by switching the toggle in bottom left corner. Your saved scripts can be found in the top menu in "Edit transformation script" pop-up window.
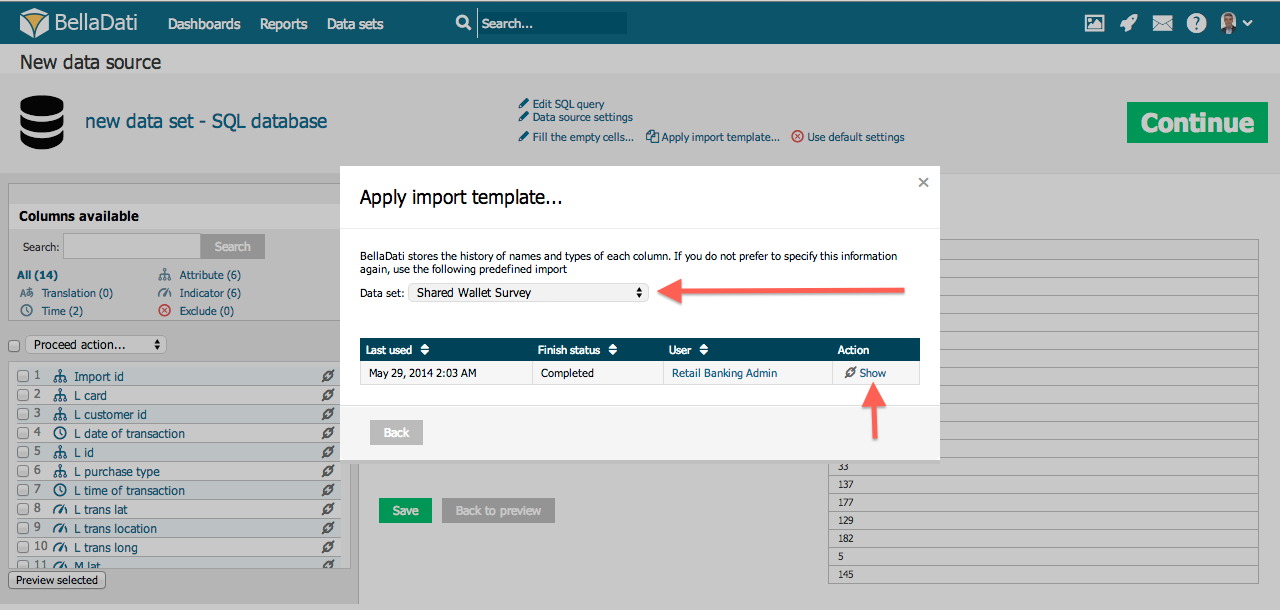
Import Templates
This function allows you to reuse import settings from previous imports or different data sets. It is available by clicking on "Apply import template" link on the top of the page.
In the popup, you can:
- Select data set
- Select import template assigned to this data set according requested date and import status
- Display import template details (column settings)
- Sort import templates
| Note |
|---|
Applying the template will overwrite all current import settings. |
You can choose from any existing import settings used in all data sets you have access to. These templates are created automatically after the import has been successfully finished.
Data Overwriting Policy
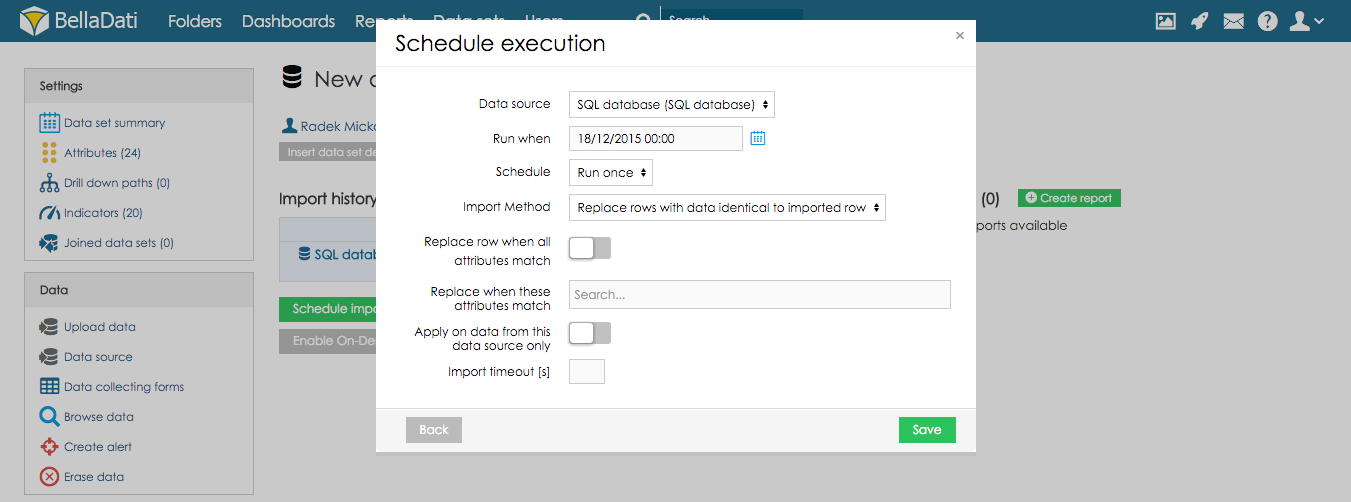
When there are already existing data in the data set, you can choose the following options what to do with these data:
- Append rows to data set: Imported data will be appended to existing (default).
- Delete all rows in the data set: Deletes all rows in the data set (can be applied only to one data source).
- Delete all rows based on date range: data in selected date range will be deleted
- Delete rows with data identical to imported row: Deletes all existing records with the same combination of selected attributes as in the imported data.
- Replace rows with data identical to imported row: replaces all records with the same combination of selected attributes as in the imported data.
Replace rows with data identical to imported row
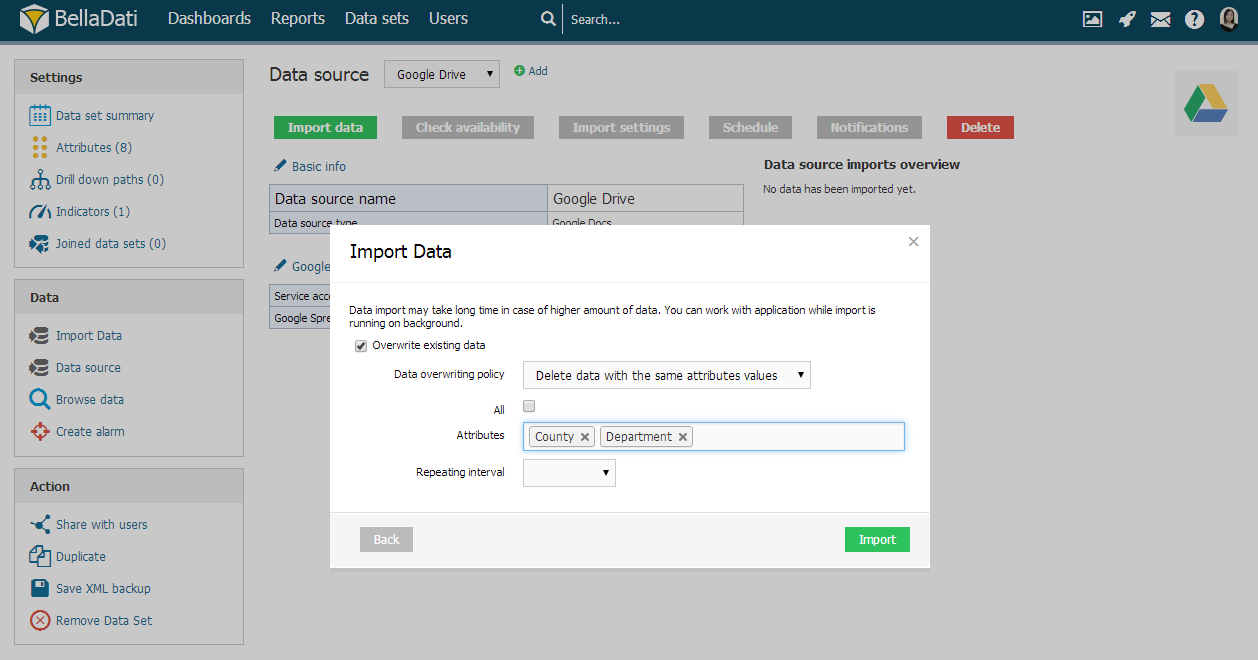
When replacing data according attributes, BellaDati allows you to:
- select All attributes.
- select specific attributes - the import procedure will compare desired attributes and will overwrite the row if the current attribute is equal to the value already stored in the database.
Delete rows with data identical to imported row
When deleting data according attributes, BellaDati allows you to:
- select All attributes.
- select specific attributes - the import procedure will compare desired attributes and will overwrite the row if the current attribute is equal to the value already stored in the database.
This import method can be applied only for the data imported from selected data source.
This import method can be applied only for the data imported from selected data source.
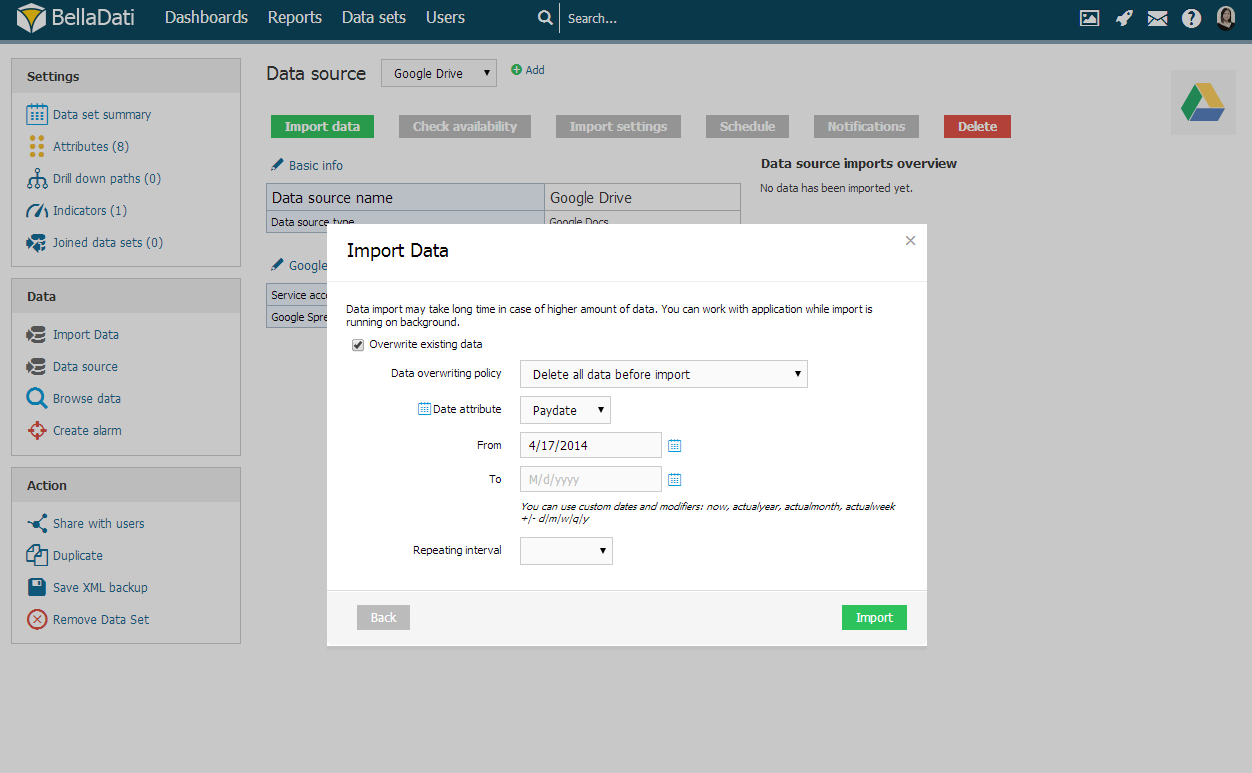
Delete all data before import
When deleting all data before import, BellaDati allows you to select specific time interval. Setup From and To to restrict data erasing.
| Tip |
|---|
Use calendar icons to comfortably select desired time intervals. |
| Info |
|---|
You can use custom dates and modifiers: now, actualyear, actualmonth, actualweek +|- d|m|w|q|y. |
Import Progress
| Note |
|---|
Import of lot of data may take a long time to complete. |
Data are being imported asynchronously, therefore BellaDati functions are still available during import. The user can be logged out during the import too.
Data set summary page shows actual import progress bar with estimated time and percentage.
Before import finishes, you are able to:
- Cancel running import: All data related to this import will be erased from BellaDati data warehouse.
- Nofity by e-mail: An e-mail will be send to you after the import has been finished.
Next Steps
- Check the import results after the import
- Create report
- Browsing data
- Transformation scripting - detailed guide
Overview
Content Tools