Page History
| Sv translation | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Column Settings
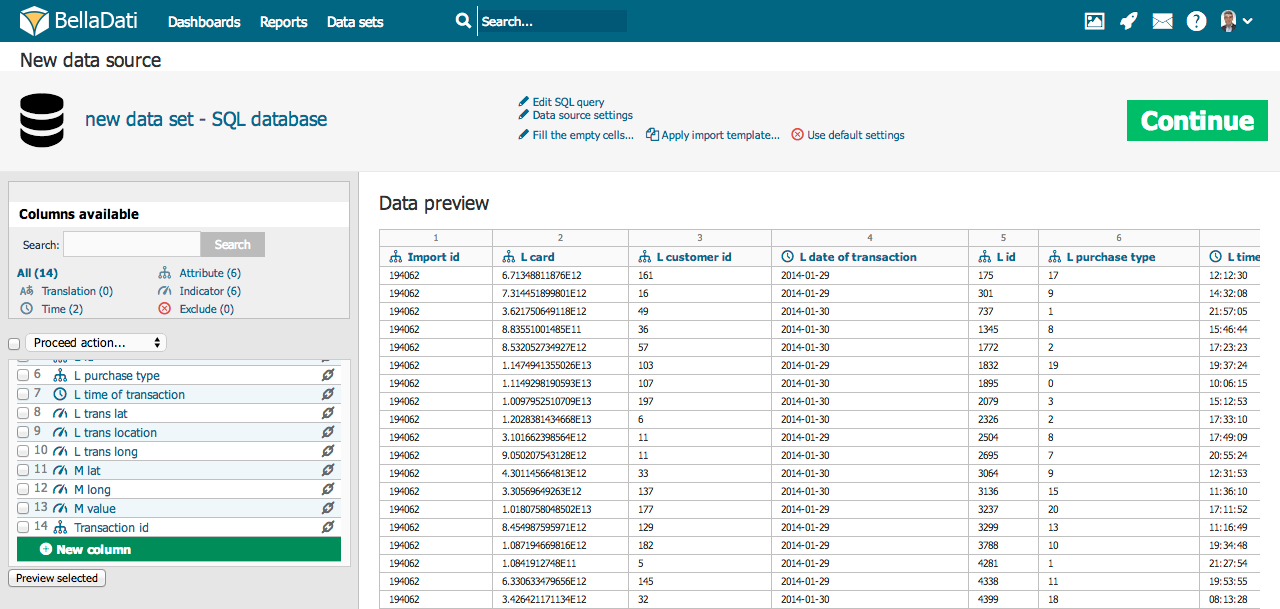
If you want to change the type of particular column, click on the name of the selected column in the list of columns (in the left side of the import screen). It's also possible to change meaning of more columns to one type in just ne step - just mark selected columns by clicking in the checkboxes next to them and then select their meaning from menu above. There are eight possible meanings of columns (data types): Date/Time (Separate) - time index of particular rows. It can be displayed in a lot of different time formats (also depending on language - for more information see the related part of this chapter). You can choose multiple date/time columns in single import. Datetime - datetime index of particular rows. It can be displayed in a lot of different datetime formats (also depending on language - for more information see the related part of this chapter). You can choose multiple datetime columns in single import. Milliseconds are also supported by datetime. Long text - defines long text - description. This column type should be used for columns which contain values with length longer than 220 characters. Cannot be used in the visualisations and aggregations. Suitable for following use cases:
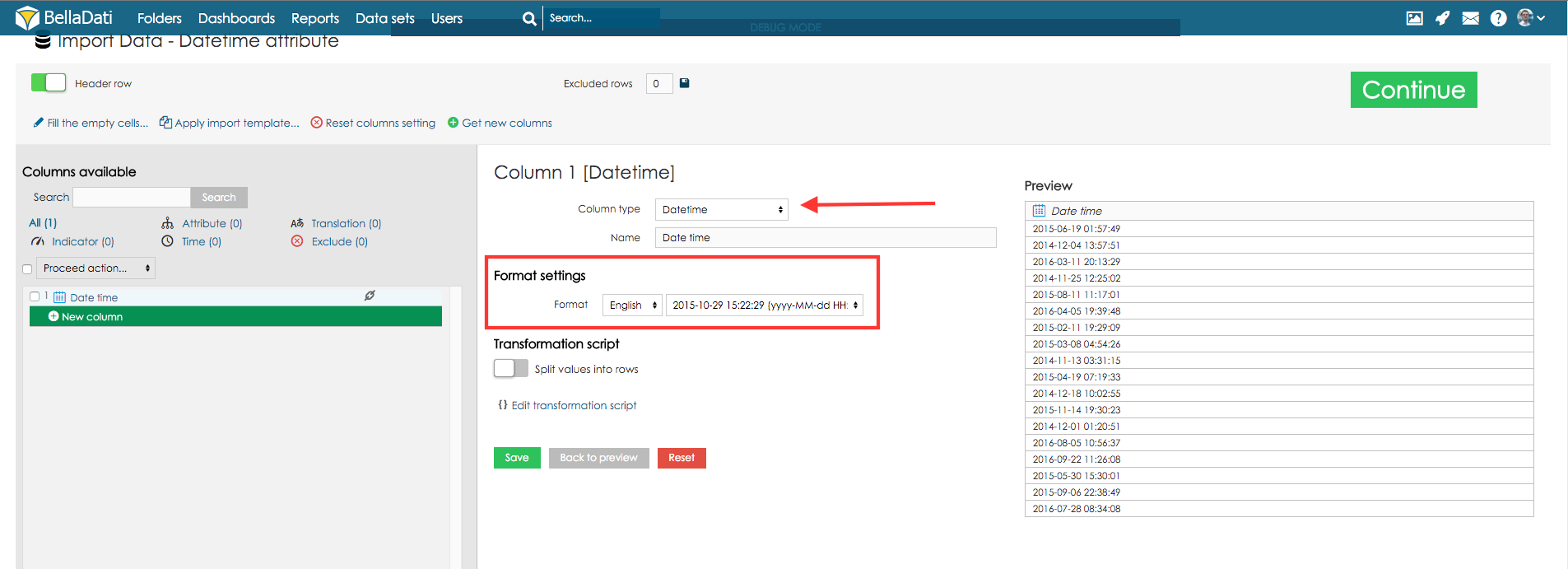
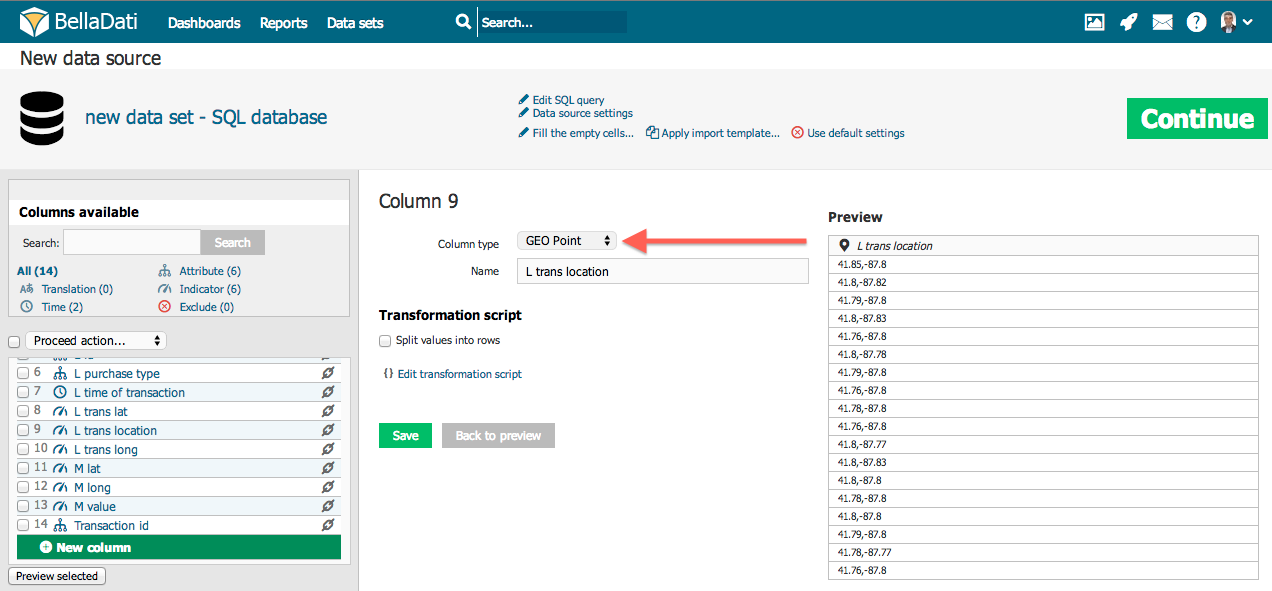
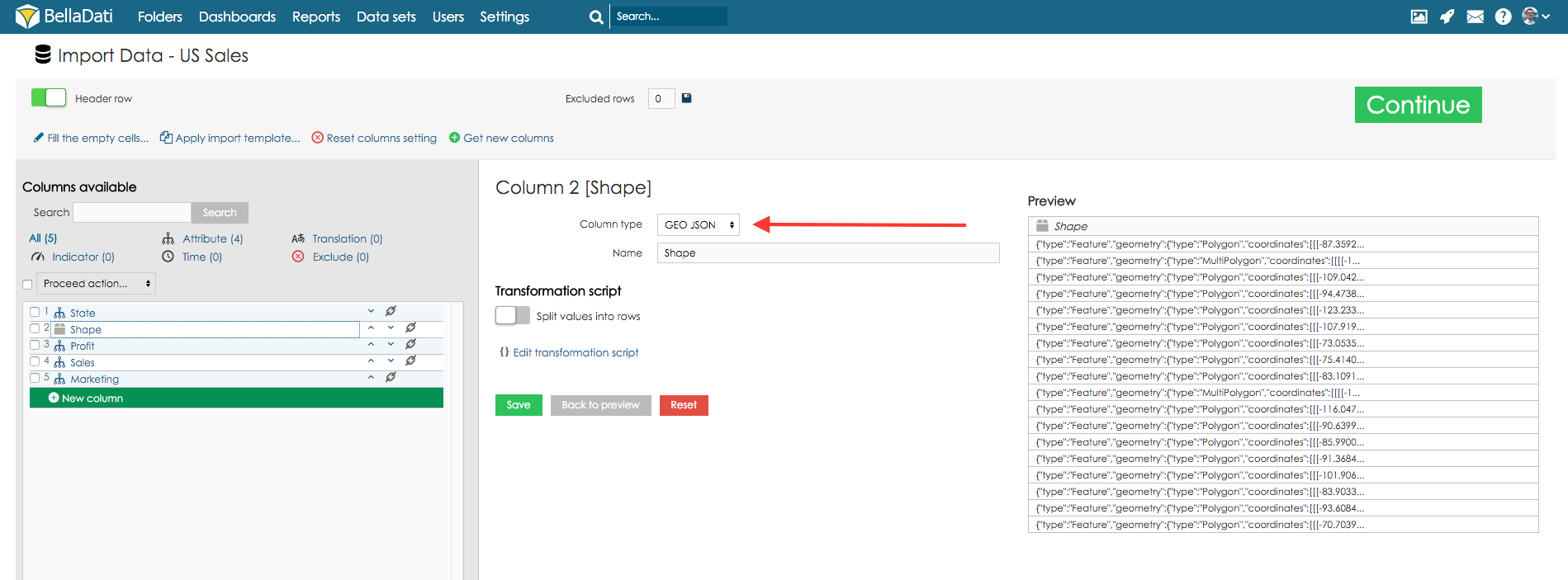
Attribute - defines categories of the drill-down path. It's usually a short text (e.g. affiliate, product, customer, employee, division etc.). Every attribute column creates exactly one attribute in the data set. Those attributes can be freely combined in the drill-down paths. GEO Point - you can map the latitude/longitude onto the GEO point attribute type. This attribute can be then used in Geo Map view type to plot data into its particular location. GEO JSON - you can map shape onto the GEO JSON attribute type. This attribute can be then used in Geo Map view type to plot data into its particular location displayed as shape. Translation - defines language translation of other column identified as Attribute Indicator - indicators are usually the numeric data, which are the main point of the user's interest. Don't import - these columns won't be imported at all (it's useful if column contains no, invalid or unimportant data). Preview of marked columns may be displayed by clicking on the "Preview selected" button. In this way you can gen a better view into you data and their meaning settings. If your data contain too much columns, you can use a search label above the column list to find appropriate column a check its settings. Under this searching field is displayed statistics, which shows number of particular types of columns. DatetimeIf your source data contains Datetime values, you can map them to Datetime attribute. This single column will contain both, date and time, e.g. 5 Apr 2014 10:43:43 AM. See the following example:
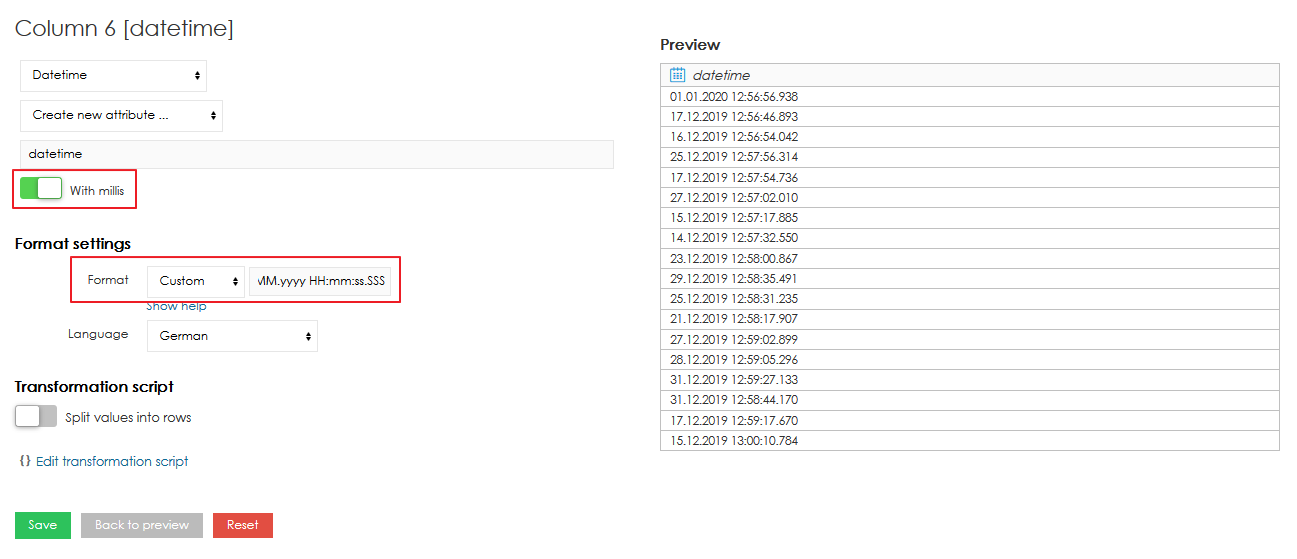
Datetime attribute also supports values with milliseconds. To use the milliseconds, option "" has to be enabled and correct datetime format has to be used ("SSS" for milliseconds, see below).
Datetime FormatEvery time column has a specific type of format. This format should be automatically detected during import. However it's possible, that you have your time data in some very specific format. In this case you can use the list of available format in different languages. If you don't choose from available formats, you can also define your own specific custom format for your data. In this case, you should choose your language from the list below and enter a code, which describes your data format according to these meanings (note, that the number of characters influences the interpretation of the code):
Separator character should be equal to separator character contained in source data (space, dot, semicolon, etc.). If your source data contains time in more separated columns (months, days, years), it's necessary to merge those columns first (described in previous part of this chapter). Next table shows some combination of source data and appropriate time code.
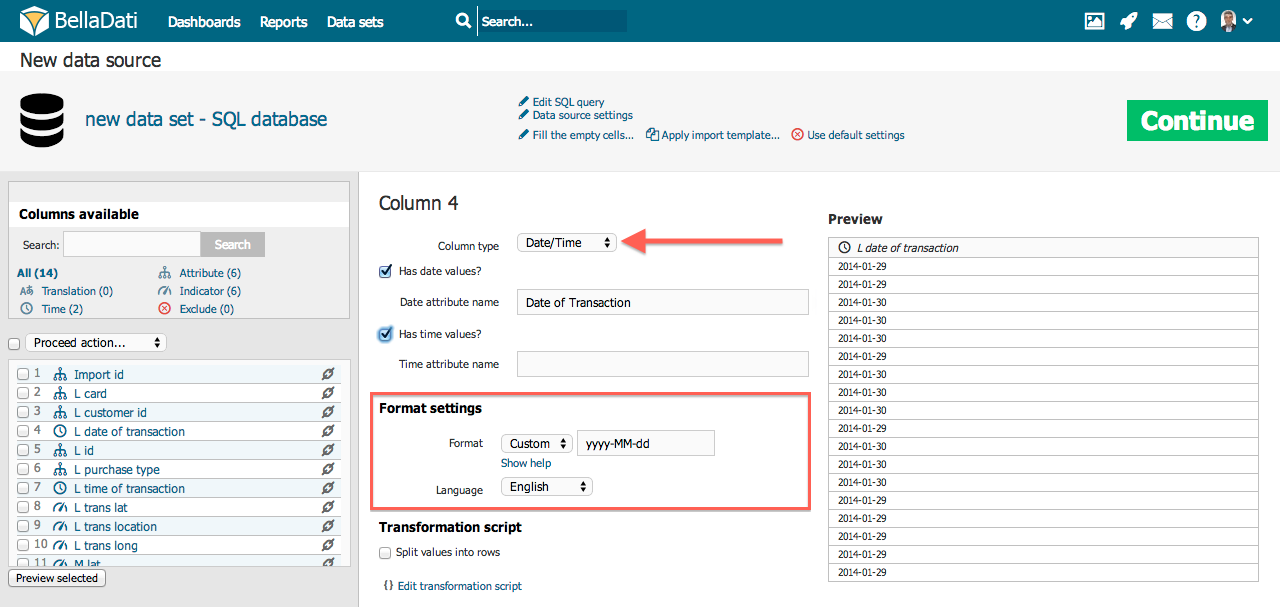
Date/TimeIf your source data contains date/time values, you can map them to the appropriate Date Attributes or Time Attributes. Single column can contain both, date and time, e.g. 5 Apr 2014 10:43:43 AM. In this case, the date part, 5 Apr 2014 will be mapped to date attribute, the time part, 10:43:43 AM to time attribute. See the following example:
Definition of Date/Time format is the same as for the Datetime column. TranslationBellaDati allows you to directly import Attribute translations. In order to set up Attribute translation navigate to column with language metaphrase and:
GEO PointIn order to map the longitude/latitude onto the GEO Point attribute, you have to specify the latitude/longitude in single column in format latitude;longitude, e.g. 43.56;99.32. Decimal separator is . (dot). You can do it using the transformation script, e.g. value(2) + ";" + value(1) in case the longitude is stored in column 1 and latitude in column 2. |
| Note |
|---|
Properties are available since version 2.9.1 |
For attributes, it is possible to change their properties:
Filling of Empty Cells
It's usual that imported data contains empty cells. It's usually necessary to replace this empty cells with own values (e.g. "0", "none", "N/A" etc.). If you want to do this, you have two possibilities, how to fill in these empty cells:
- globally - fill empty cells with chosen value in all columns (located below batch column settings)
- locally - fill empty cells with chosen value in particular column (located in the window of particular column settings)
Global changing is available in the top blue line directly under encoding settings. After clicking just type the value, which will be entered in all empty cells in your data.
Local changing is available after clicking on column name in the list. There you can enter your own value for empty cells (but only for this particular column). You can easily combine these two methods - for example you can fill in all the empty cells with "0" value, but one particular attribute column can be refilled with "N/A" value.
Merging Columns
Column merging function enables to load data from more source columns to one target column during import process.
Typical use cases are:
- Time is separated in more columns (days, months and years or time in different columns)
- Two columns representing one entity (e.g. first name and surname of one person)
Click the chain icon in the columns list, choose another column to merge with and select appropriate separator which will be added between values (space, comma, dot, semicolon, pipe). You can disconnect merged columns too.
Another way to merge columns and set up more advanced options is by transformation scripts.
Transformation Scripts
Transformation scripts allow advanced data transformations during import. These scripts are based on Groovy programming language syntax.
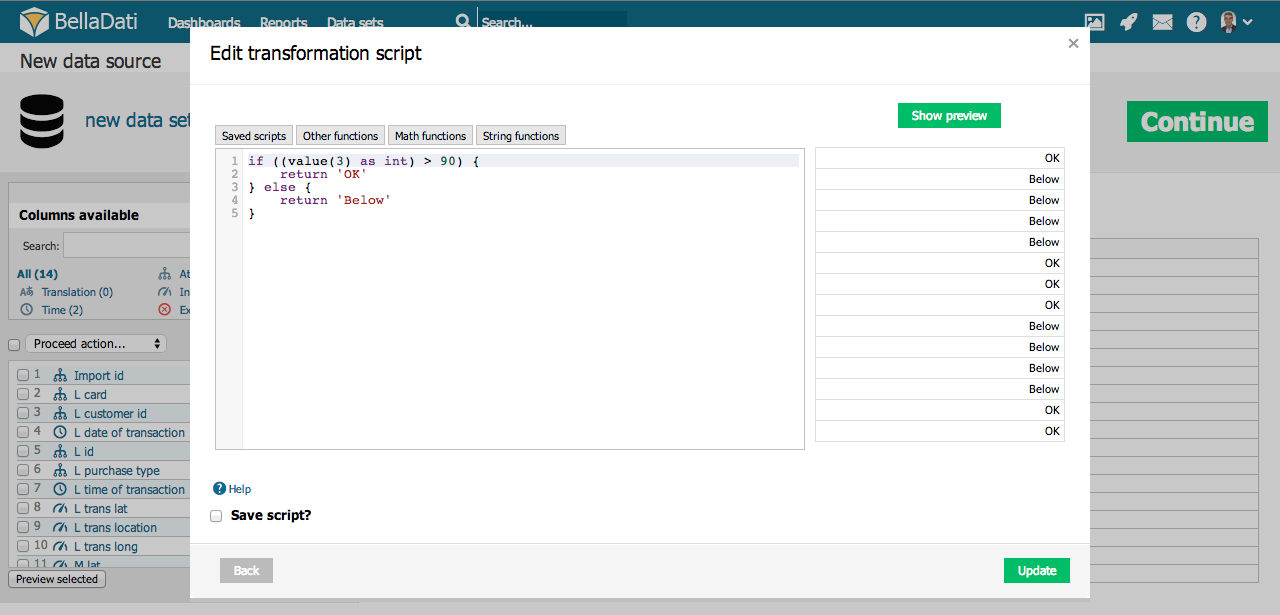
Transformation scripts allows you the following:
- Modify values stored in BellaDati data warehouse according defined functions and conditions.
- Create new columns (date/time, attributes, indicators) with transformed or combined values from other columns. Values in different cells are indexed from 0 and displayed near column names within import settings screen.
- Perform advanced calculations in date/time (eg. period of some action undertaken between two dates).
Basic script commands:
- value() - returns actual value of the current cell
- value(index) - returns value of cell on desired (indexed) position in the actual row
- name() - returns name of the column
- name(index) - returns name of the column at desired position
- format() - returns value of the format in actual column (only time and indicator column types)
- actualDate() - returns actual date in dd.MM.yyyy format
- actualDate('MM/dd/yyyy') - returns actual date in chosen format (e.g. MM/dd/yyyy)
- excludeRow() - excludes the row
| Info |
|---|
These transformations are applied for each import including scheduled automatic imports from Data Sources. |
Go to Transformation scripting guide for more details.
Reusing Transformation Scripts
If you know that you are going to use your script again in the future, you can save it by switching the toggle in bottom left corner. Your saved scripts can be found in the top menu in "Edit transformation script" pop-up window.
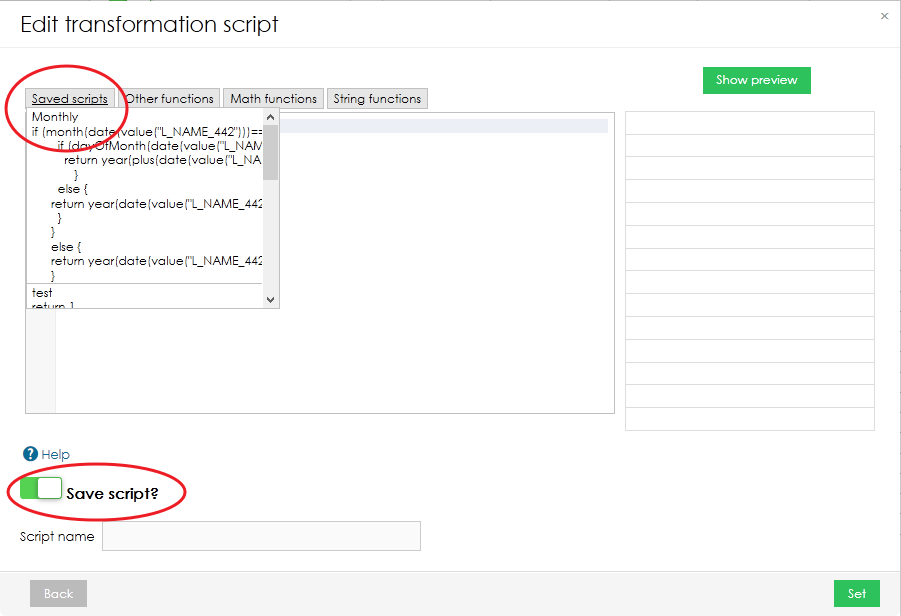
Import Templates
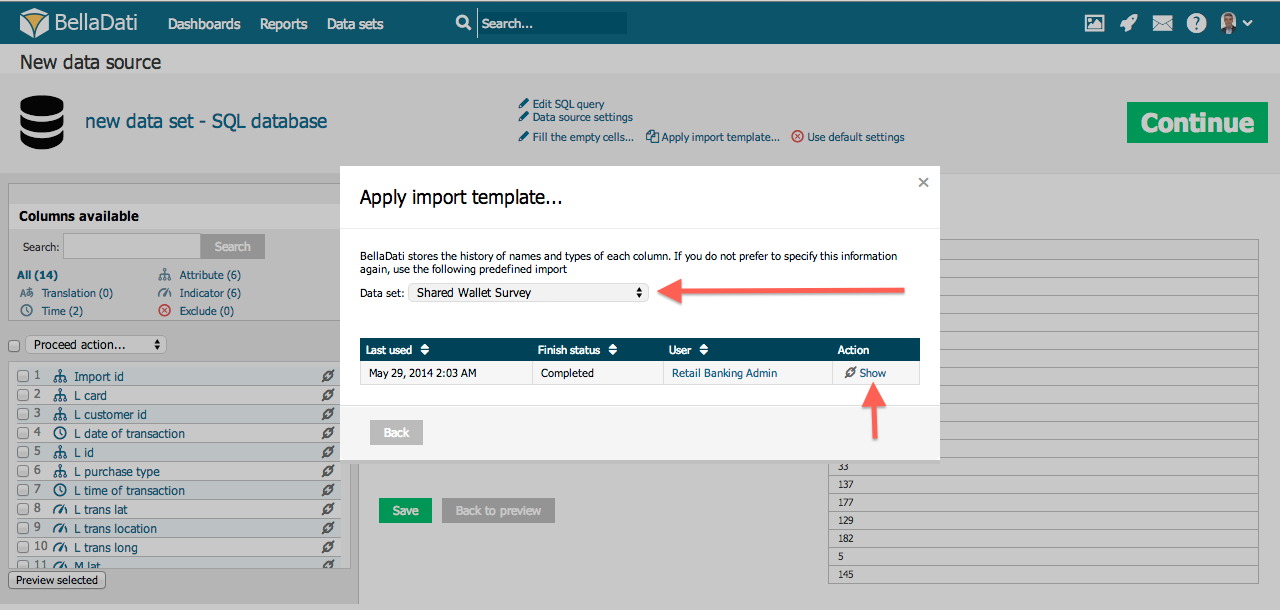
This function allows you to reuse import settings from previous imports or different data sets. It is available by clicking on "Apply import template" link on the top of the page.
In the popup, you can:
- Select data set
- Select import template assigned to this data set according requested date and import status
- Display import template details (column settings)
- Sort import templates
| Note |
|---|
Applying the template will overwrite all current import settings. |
You can choose from any existing import settings used in all data sets you have access to. These templates are created automatically after the import has been successfully finished.
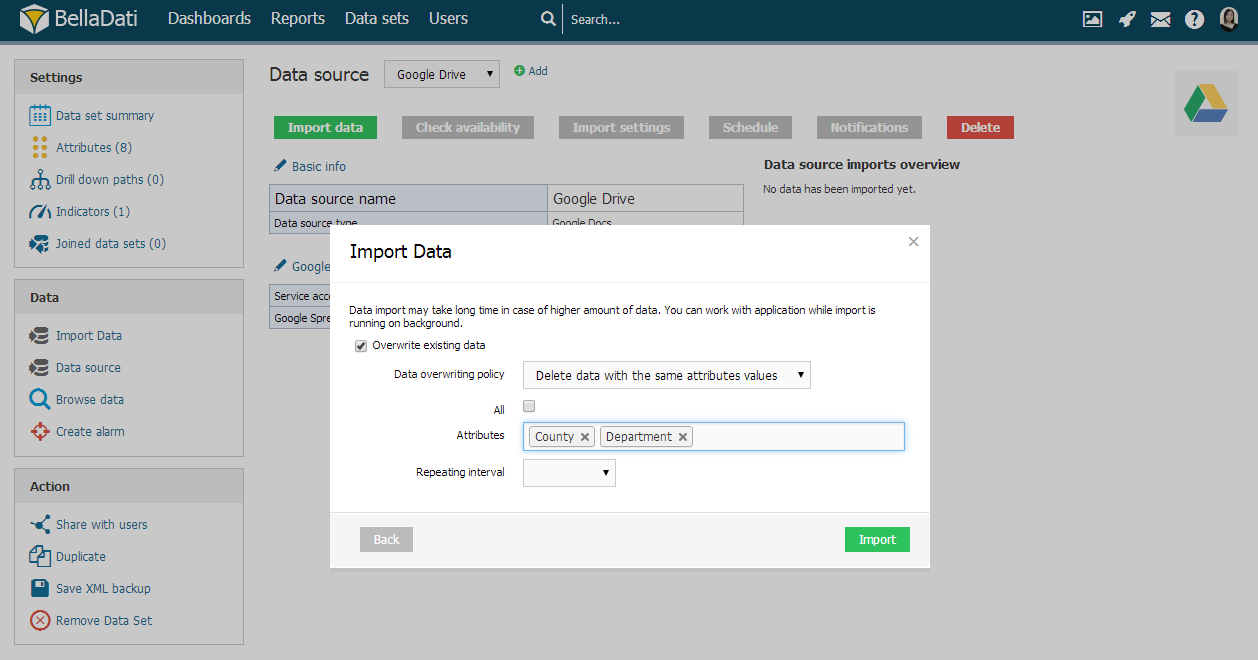
Data Overwriting Policy
When there are already existing data in the data set, you can choose the following options what to do with these data:
- Append rows to data set: Imported data will be appended to existing (default).
- Delete all rows in the data set: Deletes all rows in the data set (can be applied only to one data source).
- Delete all rows based on date range: data in selected date range will be deleted
- Delete rows with data identical to imported row: Deletes all existing records with the same combination of selected attributes as in the imported data.
- Replace rows with data identical to imported row: Replaces all records with the same combination of selected attributes as in the imported data.
- Update rows with data identical to imported row: Updates all existing records with the same combination of selected attributes as in the imported data.
Replace rows with data identical to imported row
When replacing data according to attributes, BellaDati allows you to:
- select All attributes.
- select specific attributes - the import procedure will compare desired attributes and will overwrite the row if the current attribute is equal to the value already stored in the database.
Update rows with data identical to imported row
When updating data according to attributes, BellaDati allows you to:
- select specific attributes - the import procedure will compare desired attributes and will update the row if the current attribute is equal to the value already stored in the database.
Delete rows with data identical to imported row
When deleting data according attributes, BellaDati allows you to:
- select All attributes.
- select specific attributes - the import procedure will compare desired attributes and will overwrite the row if the current attribute is equal to the value already stored in the database.
This import method can be applied only for the data imported from the selected data source.
This import method can be applied only for the data imported from selected data source.
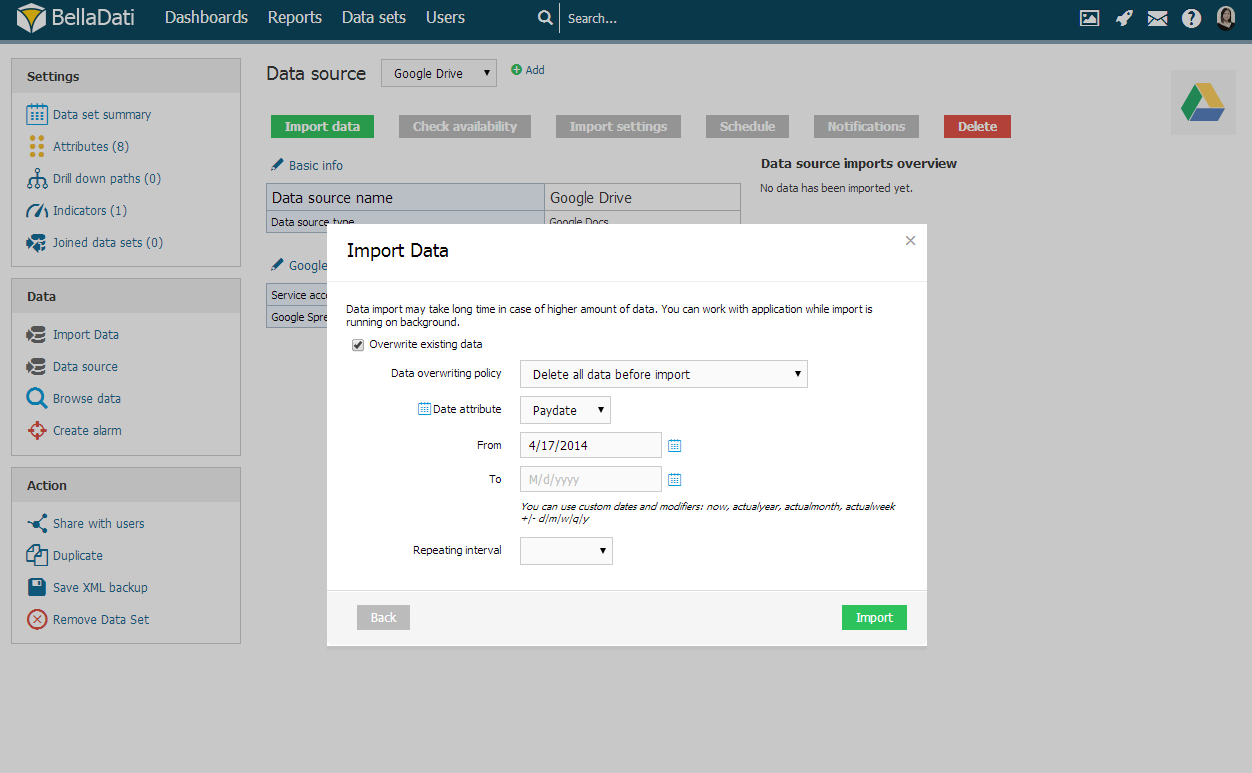
Delete all data before import
When deleting all data before import, BellaDati allows you to select specific time interval. Setup From and To to restrict data erasing.
| Tip |
|---|
Use calendar icons to comfortably select desired time intervals. |
| Info |
|---|
You can use custom dates and modifiers: now, actualyear, actualmonth, actualweek +|- d|m|w|q|y. |
Import Progress
| Note |
|---|
Import of lot of data may take a long time to complete. |
Data are being imported asynchronously, therefore BellaDati functions are still available during import. The user can be logged out during the import too.
Data set summary page shows actual import progress bar with estimated time and percentage.
Before import finishes, you are able to:
- Cancel running import: All data related to this import will be erased from BellaDati data warehouse.
- Nofity by e-mail: An e-mail will be send to you after the import has been finished.
Next Steps
- Check the import results after the import
- Create report
- Browsing data
- Transformation scripting - detailed guide
...
| Sv translation | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
列設定
特定の列のタイプを変更する場合は、列のリスト(インポート画面の左側)で選択した列の名前をクリックします。次のステップで、複数の列の意味を1つのタイプに変更することもできます - 選択した列の横にあるチェックボックスをクリックしてマークし、上のメニューから意味を選択します。 列には次の8つの意味があります(データ型): 日付/時刻 (個別) – 特定の行の時刻インデックス。様々な時間形式で表示できます(言語にも依存します - 詳細については、この章の関連部分を参照してください)。 1回のインポートで複数の日付/時刻列を選択できます。 日時 – 特定の行の日時インデックス。様々な日時形式で表示できます(言語にも依存します - 詳細については、この章の関連部分を参照してください)。1回のインポートで複数の日時列を選択できます。ミリセカンドも日時でサポートされています。 ロングテキスト – ロングテキストを定義。この列タイプは、長さが220文字を超える値を含む列に使用する必要があります。視覚化および集計では使用できません。次のユースケースに適しています:
属性 – ドリルダウンパスのカテゴリを定義します。通常、短いテキスト(例: アフィリエイト、製品、顧客、従業員、部門など)です。すべての属性列は、データセットに1つの属性を作成します。これらの属性は、ドリルダウンパスで自由に組み合わせることができます。 Geoポイント – 緯度/経度をGeoポイント属性タイプにマッピングできます。その後、この属性をGeo Mapビュータイプで使用して、特定の場所にデータをプロットできます。 GeoJSON – Geo JSON属性タイプに形状をマッピングできます。その後、この属性をGeo Mapビュータイプで使用して、形状として表示される特定の場所にデータをプロットできます。 翻訳 – 属性として識別される他の列の言語翻訳を定義します。 インジケータ – インジケータは通常、数値データであり、ユーザーの関心の主要なポイントです。 インポートしない – これらの列はまったくインポートされません(列に含まれない、無効、重要でないデータを含む場合に役立ちます)。 「選択したプレビュー」ボタンをクリックすると、マークされた列のプレビューを表示できます。このようにして、データとその意味設定をより適切に表示できます。データに含まれる列が多すぎる場合は、列リストの上にある検索ラベルを使用して適切な列を見つけ、その設定を確認できます。この検索フィールドの下には、特定の種類の列の数を示す統計が表示されます。 日付時刻ソースデータに日付時刻の値が含まれている場合は、それらを日付時刻属性にマップできます。この単一の列には、日付と時刻の両方が含まれます。例: 2014年4月5日午前10時43分43秒 次の例を参照してください:
日時属性はミリセカンドの値もサポートします。ミリセカンドを使用するには、「With millis」オプションを有効にし、正しい日時形式を使用する必要があります(ミリセカンドの場合は「SSS」、以下を参照)。
日付時刻フォーマット各列には特定の形式のタイプがあります。この形式は、インポート中に自動的に検出されます。ただし、時間データが非常に特殊な形式である可能性があります。この場合、様々な言語で利用可能な形式のリストを使用できます。 利用可能な形式から選択しない場合は、データ用に独自のカスタム形式を定義することもできます。この場合、以下のリストから言語を選択し、これらの意味に従ってデータ形式を説明するコードを入力する必要があります(文字数はコードの解釈に影響することに注意してください):
区切り文字は、ソースデータに含まれる区切り文字と等しくなければなりません(スペース、ドット、セミコロンなど)。ソースデータにさらに区切られた列に時間が含まれている場合(月、日、年)、最初にそれらの列をマージする必要があります(この章の前の部分で説明)。次の表は、ソースデータと適切なタイムコードの組み合わせを示しています。
日付/時刻ソースデータに日付/時刻値が含まれている場合、それらを適切な日付属性または時刻属性にマップできます。単一の列には、日付と時刻の両方を含めることができます。 例: 5 Apr 2014 10:43:43 AM(2014年4月5日午前10時43分43秒) この場合、5 Apr 2014(2014年4月5日)の日付部分は日付属性にマップされ、時間部分の10:43:43 AM(午前10時43分43秒)は時間属性にマップされます。次の例を参照してください:
日付/時刻形式の定義は、日付時刻列と同じです。 翻訳BellaDatiでは、属性の翻訳を直接インポートできます。属性の翻訳を設定するには、言語のメタフレーズを含む列に移動し、次のことを行います:
Geoポイント経度/緯度をGEOポイント属性にマッピングするには、緯度/経度を「緯度;経度」の形式で単一の列に指定する必要があります。例: 43.56;99.32。小数点区切り文字は.(ドット)です 。変換スクリプトを使用して実行できます。 例: 経度が列1に、緯度が列2に格納されている場合、value(2) + ";" + value(1)。 |
| Note |
|---|
プロパティはバージョン2.9.1以降で使用可能です。 |
属性については、プロパティを変更できます:
インデックス付き - ユーザーは各列のインデックス作成を無効にできます。これはパフォーマンスに影響する可能性があることに注意してください。ドリルダウンと集計に使用されるすべての列でインデックスを有効にする必要があります。デフォルトでは有効になっています。
空のセルの補充
通常、インポートされたデータには空のセルが含まれます。通常、この空のセルを独自の値("0"、"none"、"N/A"など)に置き換える必要があります。これを行う場合、これらの空のセルに入力する方法の2つの可能性があります:
グローバル– すべての列で空のセルに選択した値を入力します(バッチ列設定の下にあります)
ローカル– 特定の列で選択した値で空のセルを埋めます(特定の列設定ウィンドウにあります)
グローバル変更は、エンコード設定のすぐ下にある青い一番上の行で利用できます。クリックした後、値を入力するだけで、データのすべての空のセルに入力されます。
ローカル変更は、リスト内の列名をクリックで利用可能です。そこで、空のセルに独自の値を入力できます(ただし、この特定の列に対してのみ)。これらの2つの方法を簡単に組み合わせることができます - 例えば、すべての空のセルに「0」値を入力できますが、1つの特定の属性列に「N / A」値を再入力できます。
列のマージ
列のマージ機能により、インポートプロセス中に、より多くのソース列から1つのターゲット列にデータをロードできます。
典型的な使用例は次の通りです:
時間は複数の列に区切られる(日、月、年、時刻を異なる列に)
1つのエンティティを表す2つの列(1人の名と姓など)
列リストのチェーンアイコンをクリックし、マージする別の列を選択し、値の間に追加される適切なセパレーターを選択します(スペース、コンマ、ドット、セミコロン、パイプ)。マージされた列を切断することもできます。
列をマージしてより高度なオプションを設定する別の方法は、変換スクリプトを使用することです。
変換スクリプト
変換スクリプトにより、インポート中に高度なデータ変換が可能になります。これらのスクリプトは、Groovyプログラミング言語の構文に基づいています。
変換スクリプトを使用すると、次のことができます:
定義された機能と条件に従って、BellaDatiデータウェアハウスに保存されている値を変更します。
他の列の値を変換または結合して、新しい列を作成します(日付/時刻、属性、インジケータ)。異なるセルの値には0からインデックスが付けられ、インポート設定画面内の列名の近くに表示されます。
日付/時刻で高度な計算を実行します(例: 2つの日付の間に行われた何らかのアクションの期間)。
基本的なスクリプトコマンド:
value() – 現在のセルの実際の値を返します
value(index) – 実際の行の目的の(インデックス付き)位置のセルの値を返します
name() – 列の名前を返します
name(index) – 目的の位置にある列の名前を返します
format() – 実際の列の形式の値を返します(時間とインジケータ列タイプのみ)
actualDate() – 実際の日付をdd.MM.yyyy形式で返します
actualDate('MM/dd/yyyy') – 選択した形式で実際の日付を返します(例: MM/dd/yyyy)
excludeRow() – 行を除外します
| Info |
|---|
これらの変換は、Data Sourcesからのスケジュールされた自動インポートを含む各インポートに適用されます。 |
詳細については、変換スクリプトガイドを参照してください。
変換スクリプトの再利用
今後スクリプトを再び使用する予定がある場合は、左下隅のトグルを切り替えることでスクリプトを保存できます。保存したスクリプトは、「変換スクリプトの編集」ポップアップウィンドウのトップメニューにあります。
テンプレートのインポート
この機能により、以前のインポートや異なるデータセットからインポート設定を再利用できます。ページの上部にある[テンプレートのインポート]リンクをクリックして使用できます。
ポップアップでは、次のことができます:
データセットの選択
要求された日付とインポートステータスに従って、このデータセットに割り当てられたインポートテンプレートを選択します
インポートテンプレートの詳細を表示(列設定)
インポートテンプレートの並べ替え
| Note |
|---|
テンプレートを適用すると、現在のすべてのインポート設定が上書きされます。 |
アクセスできるすべてのデータセットで使用されている既存のインポート設定から選択できます。これらのテンプレートは、インポートが正常に終了すると自動的に作成されます。
データの上書きポリシー
データセットに既存のデータがある場合、これらのデータをどう処理するかを次のオプションから選択できます:
データセットに行を追加: インポートされたデータは既存のデータに追加されます(デフォルト)。
データセットのすべての行を削除: データセットのすべての行を削除します(1つのデータソースにのみに適用可)。
- 日付範囲に基づいてすべての行を削除: 選択された日付範囲のデータが削除されます。
インポートされた行と同一データの行を削除: インポートされたデータと同じ選択された属性の組み合わせを持つすべての既存のレコードを削除します。
インポートされた行と同一データで行を置き換え: インポートされたデータと同じ選択された属性の組み合わせですべてのレコードを置換します。
インポートされた行と同一データで行を置き換え
属性に従ってデータを置換する場合、BellaDatiでは次のことができます:
すべての属性の選択
特定の属性を選択 – インポート手順は、目的の属性を比較し、現在の属性がデータベースに既に保存されている値と等しい場合、行を上書きします。
インポートされた行と同一データの行を削除
属性に従ってデータを削除する場合、BellaDatiでは次のことができます:
すべての属性の選択
特定の属性を選択 - インポート手順は、目的の属性を比較し、現在の属性がデータベースに既に保存されている値と等しい場合、行を上書きします。
このインポート方法は、選択したデータソースからインポートされたデータにのみ適用できます。
このインポート方法は、選択したデータソースからインポートされたデータにのみ適用できます。
インポート前にすべてのデータを削除
インポート前にすべてのデータを削除する場合、BellaDatiでは特定の時間間隔を選択できます。データの消去を制限するには、FromおよびToを設定します。
| Tip |
|---|
カレンダーアイコンを使用して、目的の時間間隔を快適に選択します。 |
| Info |
|---|
カスタムの日付と修飾子を使用できます: now、actualyear、actualmonth、actualweek +|- d|m|w|q|y。 |
インポートの進行状況
| Note |
|---|
大量のデータのインポートが完了するまでに時間がかかる場合があります。 |
データは非同期にインポートされているため、インポート中もBellaDati機能を使用できます。ユーザーはインポート中にログアウトすることもできます。
データセットの概要ページには、実際のインポートの進行状況バーと推定時間と割合が表示されます。
インポートが完了する前に、次のことができます:
- 実行中のインポートをキャンセル: このインポートに関連するすべてのデータは、BellaDatiデータウェアハウスから消去されます。
メールによる通知: インポートが完了すると、電子メールが送信されます。
次に
| Sv translation | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Column Settings
Wenn Sie den Typ einer bestimmten Spalte ändern möchten, klicken Sie auf den Namen der ausgewählten Spalte in der Liste der Spalten (auf der linken Seite des Importbildschirms). Es ist auch möglich, die Bedeutung mehrerer Spalten in nur einem Schritt auf einen Typ zu ändern - markieren Sie einfach ausgewählte Spalten, indem Sie auf die Kontrollkästchen neben ihnen klicken und dann ihre Bedeutung aus dem Menü oben auswählen. Es gibt acht mögliche Bedeutungen von Spalten (Datentypen): Datum/Uhrzeit (separat) - Zeitindex bestimmter Zeilen. Es kann in vielen verschiedenen Zeitformaten angezeigt werden (auch sprachabhängig - weitere Informationen finden Sie im entsprechenden Teil dieses Kapitels). Sie können mehrere Datums-/Uhrzeitspalten im Einzelimport auswählen. Datum/Uhrzeit - Datumszeitindex bestimmter Zeilen. Es kann in vielen verschiedenen Datumsformaten angezeigt werden (auch sprachabhängig - weitere Informationen finden Sie im entsprechenden Teil dieses Kapitels). Sie können mehrere Datetime-Spalten im Einzelimport auswählen. Langtext - definiert Langtext - Beschreibung. Dieser Spaltentyp sollte für Spalten verwendet werden, die Werte mit einer Länge von mehr als 220 Zeichen enthalten. Kann nicht in den Visualisierungen und Aggregationen verwendet werden. Geeignet für folgende Anwendungsfälle:
Attribut - definiert Kategorien des Drill-Down-Pfades. Es handelt sich in der Regel um einen kurzen Text (z.B. Affiliate, Produkt, Kunde, Mitarbeiter, Abteilung etc.). Jede Attributspalte erzeugt genau ein Attribut im Dataset. Diese Attribute können in den Drill-Down-Pfaden frei kombiniert werden. GEO Point - Sie können den Breitengrad/Längengrad auf den Attributtyp GEO Point abbilden. Dieses Attribut kann dann im Ansichtstyp Geokarte verwendet werden, um Daten an ihrer jeweiligen Position darzustellen. GEO JSON - Sie können die Form auf den Attributtyp GEO JSON abbilden. Dieses Attribut kann dann im Ansichtstyp Geokarte verwendet werden, um Daten an ihre bestimmte Position zu plotten, die als Form angezeigt wird. Übersetzung - definiert die Sprachübersetzung einer anderen Spalte, die als Attribut identifiziert wird. Indikator - Indikatoren sind in der Regel die numerischen Daten, die den Schwerpunkt des Interesses des Benutzers bilden. Nicht importieren - diese Spalten werden überhaupt nicht importiert (nützlich, wenn die Spalte keine, ungültige oder unwichtige Daten enthält). Datum/ UhrzeitWenn Ihre Quelldaten Datetime-Werte enthalten, können Sie diese auf das Attribut Datum/ Uhrzeit abbilden. Diese einzelne Spalte enthält sowohl Datum als auch Uhrzeit, z.B. 5 Apr 2014 10:43:43:43 AM. Siehe folgendes Beispiel:
Datum/ Uhrzeit FormatJede Spalte hat eine bestimmte Art von Format. Dieses Format sollte beim Import automatisch erkannt werden. Es ist jedoch möglich, dass Sie Ihre Zeitangaben in einem sehr spezifischen Format haben. In diesem Fall können Sie die Liste der verfügbaren Formate in verschiedenen Sprachen verwenden. Wenn Sie nicht aus den verfügbaren Formaten wählen, können Sie auch Ihr eigenes, spezielles Format für Ihre Daten definieren. In diesem Fall sollten Sie Ihre Sprache aus der folgenden Liste auswählen und einen Code eingeben, der Ihr Datenformat entsprechend dieser Bedeutung beschreibt (beachten Sie, dass die Anzahl der Zeichen die Interpretation des Codes beeinflusst):
Das Trennzeichen sollte gleich dem Trennzeichen in den Quelldaten (Leerzeichen, Punkt, Semikolon, etc.) sein. Wenn Ihre Quelldaten Zeit in getrennteren Spalten (Monate, Tage, Jahre) enthalten, ist es notwendig, diese Spalten zuerst zusammenzuführen (wie im vorherigen Teil dieses Kapitels beschrieben). Die nächste Tabelle zeigt eine Kombination aus Quelldaten und entsprechendem Timecode.
Datum/ UhrzeitWenn Ihre Quelldaten Datums-/Uhrzeitwerte enthalten, können Sie diese den entsprechenden Datums- oder Zeitattributen zuordnen. Eine einzelne Spalte kann sowohl Datum als auch Uhrzeit enthalten, z.B. 5 Apr 2014 10:43:43:43 AM. In diesem Fall wird der Datumsteil, 5. April 2014, auf das Datumsattribut abgebildet, der Zeitteil, 10:43:43 AM auf das Zeitattribut. Siehe folgendes Beispiel:
Die Definition des Datums-/Zeitformats ist die gleiche wie für die Spalte Datun/ Uhrzeit. ÜbersetzungMit BellaDati können Sie Attributübersetzungen direkt importieren. Um die Attributübersetzung einzurichten, navigieren Sie zur Spalte mit der Sprachmetaphrase und:
GEO-PunktUm den Längengrad auf das Attribut GEO Point abzubilden, müssen Sie den Breitengrad in einer Spalte im Format Breitengrad;Längengrad angeben, z.B. 43.56;99.32. Dezimaltrennzeichen ist . (Punkt). Du kannst es mit dem Transformationsskript tun, z.B. value(2) + ";" + value(1), falls der Längengrad in Spalte 1 und der Breitengrad in Spalte 2 gespeichert ist. |
| Note |
|---|
Eigenschaften sind seit Version 2.9.1 verfügbar. |
Für Attribute ist es möglich, deren Eigenschaften zu ändern:
Indexiert - Benutzer können die Indexierung jeder Spalte deaktivieren. Bitte beachten Sie, dass dies die Performance beeinträchtigen kann. Die Indexierung sollte für alle Spalten aktiviert werden, die für Drill-Downs und Aggregationen verwendet werden. Standardmäßig aktiviert.
Nicht nur leere Werte - durch Aktivieren dieser Option können Benutzer den Wert obligatorisch machen. Standardmäßig deaktiviert.
Füllen von leeren Zellen
Es ist üblich, dass importierte Daten leere Zellen enthalten. In der Regel ist es notwendig, diese leeren Zellen durch eigene Werte zu ersetzen (z.B. "0", "none", "N/A" etc.). Wenn Sie dies tun wollen, haben Sie zwei Möglichkeiten, wie Sie diese leeren Felder ausfüllen können:
global - füllt leere Zellen mit dem gewählten Wert in allen Spalten (befindet sich unter den Einstellungen der Batch-Spalte).
lokal - füllen Sie leere Zellen mit dem gewählten Wert in einer bestimmten Spalte (im Fenster mit den entsprechenden Spalteneinstellungen).
Die globale Änderung ist in der oberen blauen Zeile direkt unter den Kodierungseinstellungen verfügbar. Nach dem Anklicken geben Sie einfach den Wert ein, der in alle leeren Zellen Ihrer Daten eingetragen wird.
Lokale Änderungen sind nach Anklicken des Spaltennamens in der Liste möglich. Dort können Sie einen eigenen Wert für leere Zellen eingeben (aber nur für diese bestimmte Spalte). Sie können diese beiden Methoden einfach kombinieren - zum Beispiel können Sie alle leeren Zellen mit dem Wert "0" ausfüllen, aber eine bestimmte Attributspalte kann mit dem Wert "N/A" wieder gefüllt werden.
Spalten zusammenfügen
Die Funktion zum Zusammenführen von Spalten ermöglicht es, während des Importvorgangs Daten aus mehreren Quellspalten in eine Zielspalte zu laden.
Typische Anwendungsfälle sind:
Die Zeit ist in mehrere Spalten unterteilt (Tage, Monate und Jahre oder Zeit in verschiedenen Spalten).
Zwei Spalten, die eine Einheit darstellen (z.B. Vor- und Nachname einer Person)
Klicken Sie auf das Kettensymbol in der Spaltenliste, wählen Sie eine andere Spalte zum Zusammenführen und wählen Sie ein geeignetes Trennzeichen, das zwischen den Werten (Leerzeichen, Komma, Punkt, Semikolon, Rohr) hinzugefügt wird. Sie können auch zusammengeführte Spalten trennen.
Eine weitere Möglichkeit, Spalten zusammenzuführen und erweiterte Optionen einzurichten, besteht in der Verwendung von Transformationsskripten.
Transformationsskripte
Transformationsskripte ermöglichen erweiterte Datentransformationen während des Imports. Diese Skripte basieren auf der Syntax der Groovy-Programmiersprache.
Transformationsskripte ermöglichen Ihnen Folgendes:
Ändern Sie die im BellaDati Data Warehouse gespeicherten Werte entsprechend den definierten Funktionen und Bedingungen.
Erstellen Sie neue Spalten (Datum/Uhrzeit, Attribute, Kennzeichen) mit transformierten oder kombinierten Werten aus anderen Spalten. Werte in verschiedenen Zellen werden von 0 indiziert und in der Nähe von Spaltennamen im Importeinstellungsfenster angezeigt.
Führen Sie erweiterte Berechnungen in Datum/Uhrzeit durch (z.B. Zeitraum einer Aktion zwischen zwei Daten).
Grundlegende Skriptbefehle:
- value() - gibt den Istwert der aktuellen Zelle zurück
- value(index) - gibt den Wert der Zelle an der gewünschten (indizierten) Position in der aktuellen Zeile zurück.
- name() - gibt den Namen der Spalte zurück
- name(index) - gibt den Namen der Spalte an der gewünschten Position zurück
- format() - gibt den Wert des Formats in der aktuellen Spalte zurück (nur Zeit- und Indikatorspaltentypen
- actualDate() - gibt das aktuelle Datum im Format dd.MM.yyyyyyy zurück.
- actualDate('MM/dd/yyyy') - returns actual date in chosen format (e.g. MM/dd/yyyy)
- excludeRow() - schliept die Zeile
| Info |
|---|
Diese Transformationen werden für jeden Import angewendet, einschließlich des geplanten automatischen Imports aus Datenquellen. |
Weitere Informationen finden Sie im Leitfaden für Transformationsskripte.
Wiederverwendung von Transformationsskripten
Wenn Sie wissen, dass Sie Ihr Skript in Zukunft wieder verwenden werden, können Sie es speichern, indem Sie den Schalter in der linken unteren Ecke wechseln. Ihre gespeicherten Skripte finden Sie im oberen Menü im Popup-Fenster "Transformationsskript bearbeiten".
Vorlagen importieren
Mit dieser Funktion können Sie Importeinstellungen aus früheren Importen oder verschiedenen Datensätzen wiederverwenden. Sie ist verfügbar, indem Sie oben auf der Seite auf den Link "Vorlage importieren" klicken.
In dem Popup-Fenster können Sie:
- Datensatz auswählen
- Auswahl der diesem Datensatz zugeordneten Importvorlage nach Wunschdatum und Importstatus
- Details der Importvorlage anzeigen (Spalteneinstellungen)
- Importvorlagen sortieren
| Note |
|---|
Durch das Anwenden der Vorlage werden alle aktuellen Importeinstellungen überschrieben. |
Sie können aus allen vorhandenen Importeinstellungen wählen, die in allen Datensätzen verwendet werden, auf die Sie Zugriff haben. Diese Vorlagen werden automatisch erstellt, nachdem der Import erfolgreich abgeschlossen wurde.
Richtlinie zum Überschreiben von Daten
Wenn bereits Daten im Datensatz vorhanden sind, können Sie die folgenden Optionen wählen, was mit diesen Daten geschehen soll:
- Fügt Zeilen an den Datensatz an: Importierte Daten werden an bestehende angehängt (Standard).
- Alle Zeilen des Datensatzes löschen: Löscht alle Zeilen des Datensatzes (kann nur auf eine Datenquelle angewendet werden).
- Alle Zeilen basierend auf dem Datumsbereich löschen: Daten im ausgewählten Datumsbereich werden gelöscht.
- Löschen Sie Zeilen mit Daten, die mit der importierten Zeile identisch sind: Löscht alle vorhandenen Datensätze mit der gleichen Kombination von ausgewählten Attributen wie in den importierten Daten.
- Ersetzt Zeilen durch Daten, die mit importierten Zeilen identisch sind: ersetzt alle Datensätze mit der gleichen Kombination von ausgewählten Attributen wie in den importierten Daten.
Ersetzen Sie Zeilen durch Daten, die mit der importierten Zeile identisch sind.
Wenn Sie Daten durch Attribute ersetzen, ermöglicht Ihnen BellaDati folgendes:
wählen Sie Alle Attribute.
spezifische Attribute auswählen - der Importvorgang vergleicht die gewünschten Attribute und überschreibt die Zeile, wenn das aktuelle Attribut gleich dem bereits in der Datenbank gespeicherten Wert ist.
Zeilen mit Daten löschen, die mit der importierten Zeile identisch sind.
Wenn Sie Daten nach Attributen löschen, erlaubt Ihnen BellaDati dies:
wählen Sie Alle Attribute.
spezifische Attribute auswählen - der Importvorgang vergleicht die gewünschten Attribute und überschreibt die Zeile, wenn das aktuelle Attribut gleich dem bereits in der Datenbank gespeicherten Wert ist.
Diese Importmethode kann nur für die aus der ausgewählten Datenquelle importierten Daten angewendet werden.
Diese Importmethode kann nur für die aus der ausgewählten Datenquelle importierten Daten angewendet werden.
Alle Daten vor dem Import löschen
Wenn Sie alle Daten vor dem Import löschen, können Sie in BellaDati ein bestimmtes Zeitintervall auswählen. Einrichten von und bis, um das Löschen von Daten einzuschränken.
| Tip |
|---|
Verwenden Sie Kalendersymbole, um bequem die gewünschten Zeitintervalle auszuwählen. |
| Info |
|---|
Sie können benutzerdefinierte Daten und Modifikatoren verwenden: jetzt, aktuelles Jahr, aktueller Monat, aktuelle Woche +|- d|m|w|q|y. |
Importfortschritt
| Note |
|---|
Der Import von vielen Daten kann lange Zeit in Anspruch nehmen. |
Die Daten werden asynchron importiert, so dass die BellaDati-Funktionen während des Imports weiterhin verfügbar sind. Der Benutzer kann auch während des Imports abgemeldet werden. Die Zusammenfassungsseite des Datensatzes zeigt den aktuellen Importfortschrittsbalken mit geschätzter Zeit und Prozentsatz.
Bevor der Import abgeschlossen ist, ist es möglich:
- Laufenden Import abbrechen: Alle Daten im Zusammenhang mit diesem Import werden aus dem BellaDati Data Warehouse gelöscht.
- Identität per E-Mail: Nach Abschluss des Imports erhalten Sie eine E-Mail.
Nächste Schritte
- Überprüfung der Importergebnisse nach dem Import
- Report erstellen
- Durchsuchen von Daten
- Transformationsskripting - detaillierte Anleitung
Overview
Content Tools