Page History
| Sv translation | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||
Big Data Sets are special types of data sets that can be used to store a very large amount of data and build pre-calculated cubes. The main differences between standard data sets and big data sets are:
Creating Big Data Set
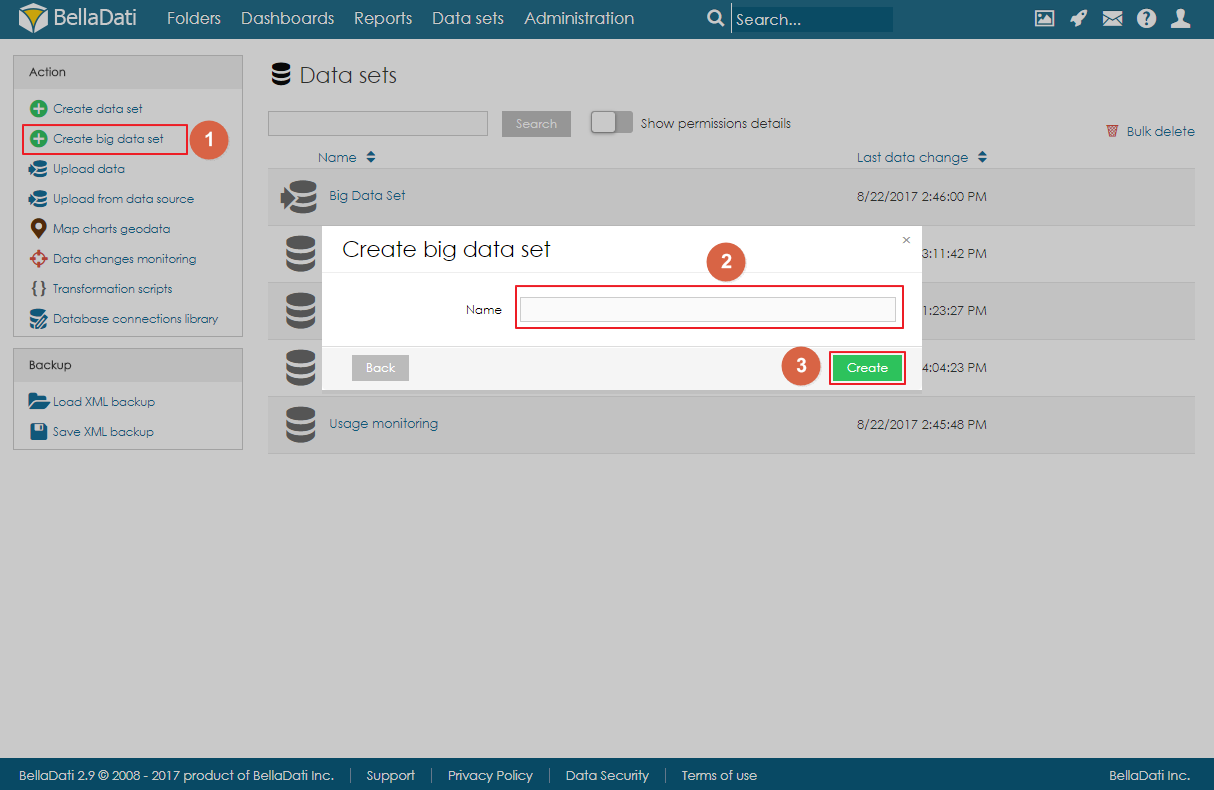
Big Data Set can be created by clicking on the link Create big data set in the Action menu on the Data Sets page, filling in the name of the big data set, and clicking on Create.
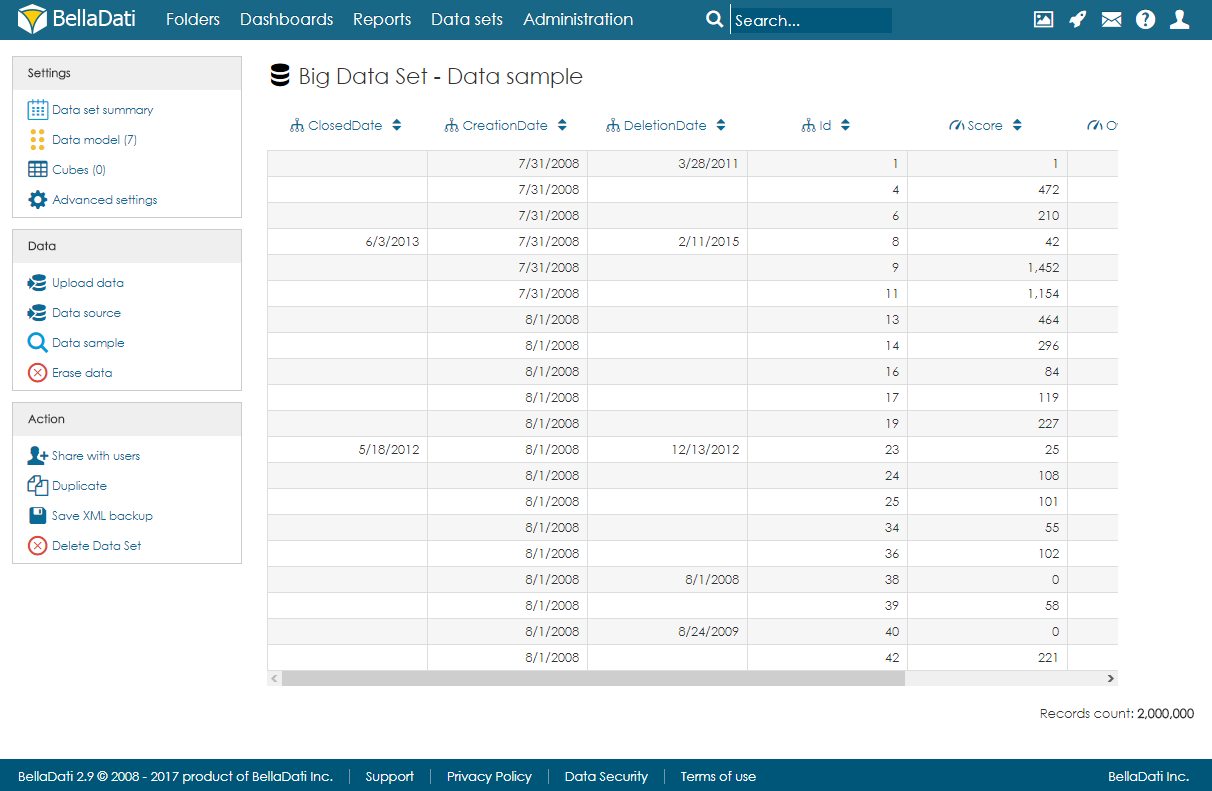
Big Data Set summary pageThe landing page (summary page) is very similar to the standard data set summary page. There are a left navigation menu and the main area with basic information about the data set:
Actions
Importing DataData can be imported to a big data set the same way as to standard data set. Users can either import data from a file or from a data source. However, the big data set is not using standard indicators and attributes, but instead, each column is defined as an object. These objects can have various data types:
After import, users can open the data sample page to see a randomly selected part of the data.
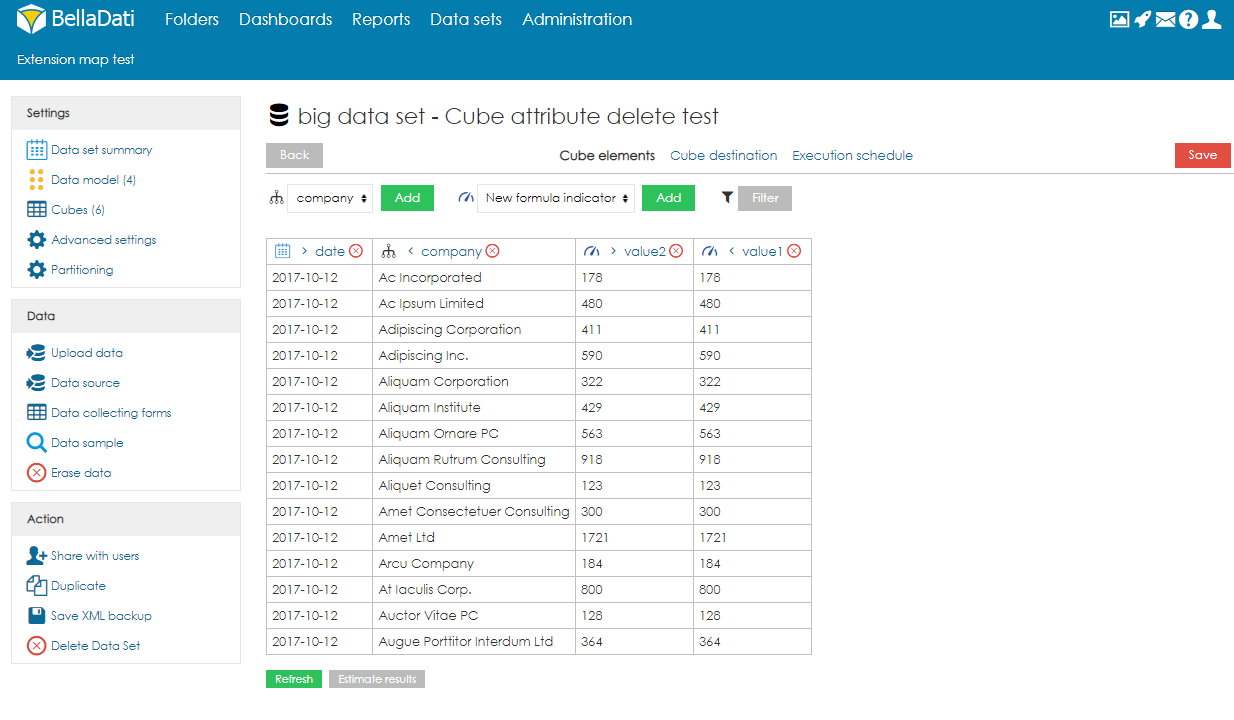
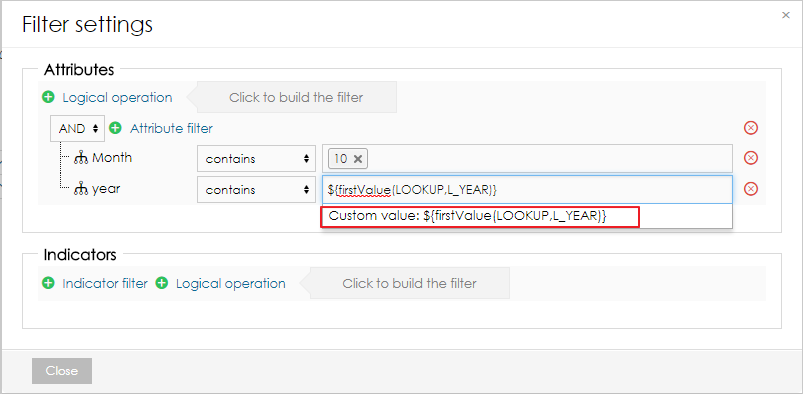
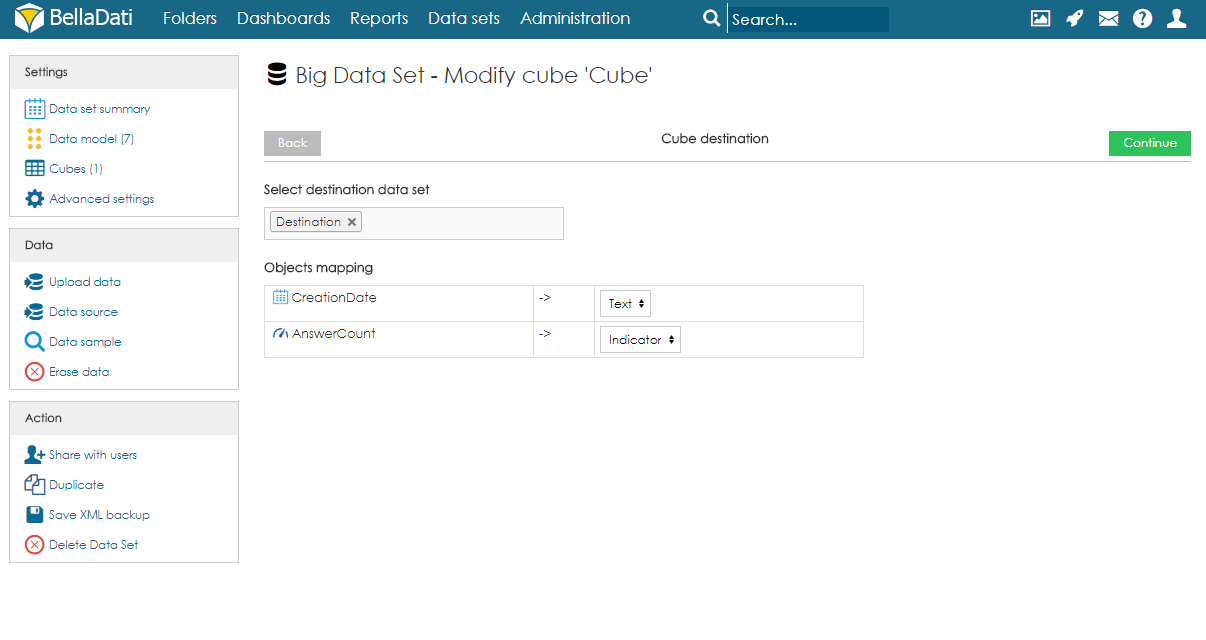
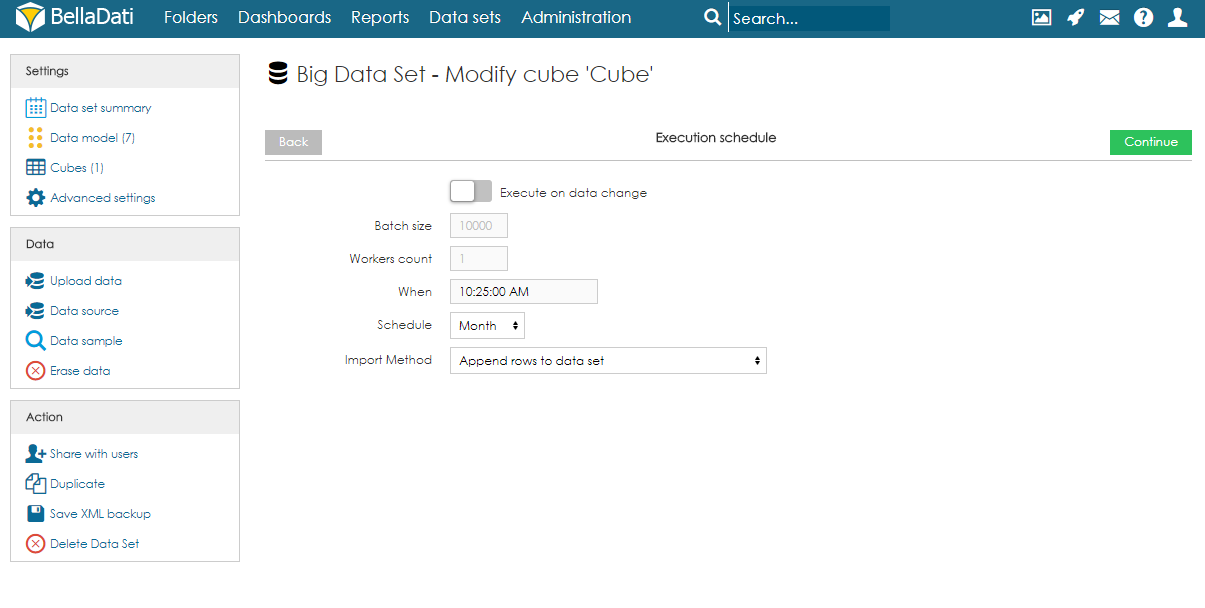
Managing ObjectsObjects (columns) can be created automatically during the import, or they can be defined on the data model page. When adding a new object, users can specify its name, data type, indexation, and whether it can contain empty values or not. Please note that GEO point, GEO JSON, long text, boolean and numeric cannot be indexed. Objects can also be edited and deleted by clicking on the row. CubesCube is a data table that contains aggregated data from the big data set. Users can define the aggregation and also limit the data by applying filters. Data from the cube can then be imported to a data set. Each big data set can have more than one cube, and each cube can have different settings. Creating CubeTo create a cube, users need to follow these steps:
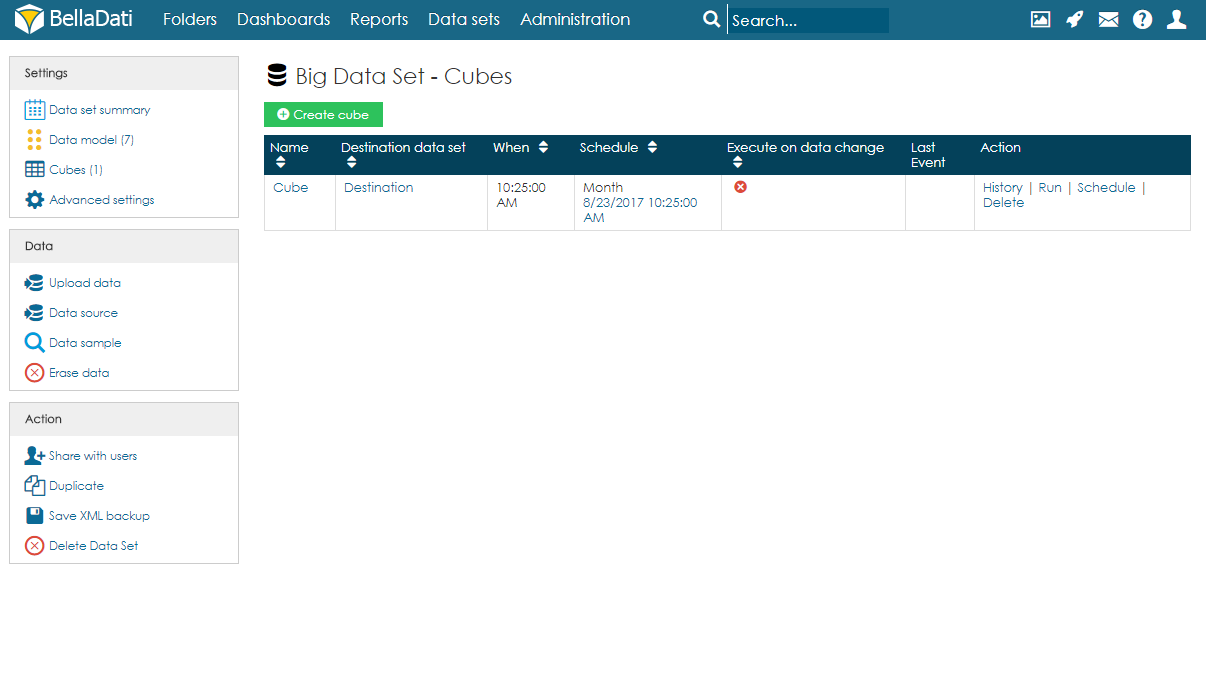
Cubes summaryOn the Cubes page, users can see a table with all cubes associated with the big data set. For each cube, information about the schedule and last event are available. Users can also edit the cube by clicking anywhere on the row or on the name of the cube. Several actions are also available for each cube:
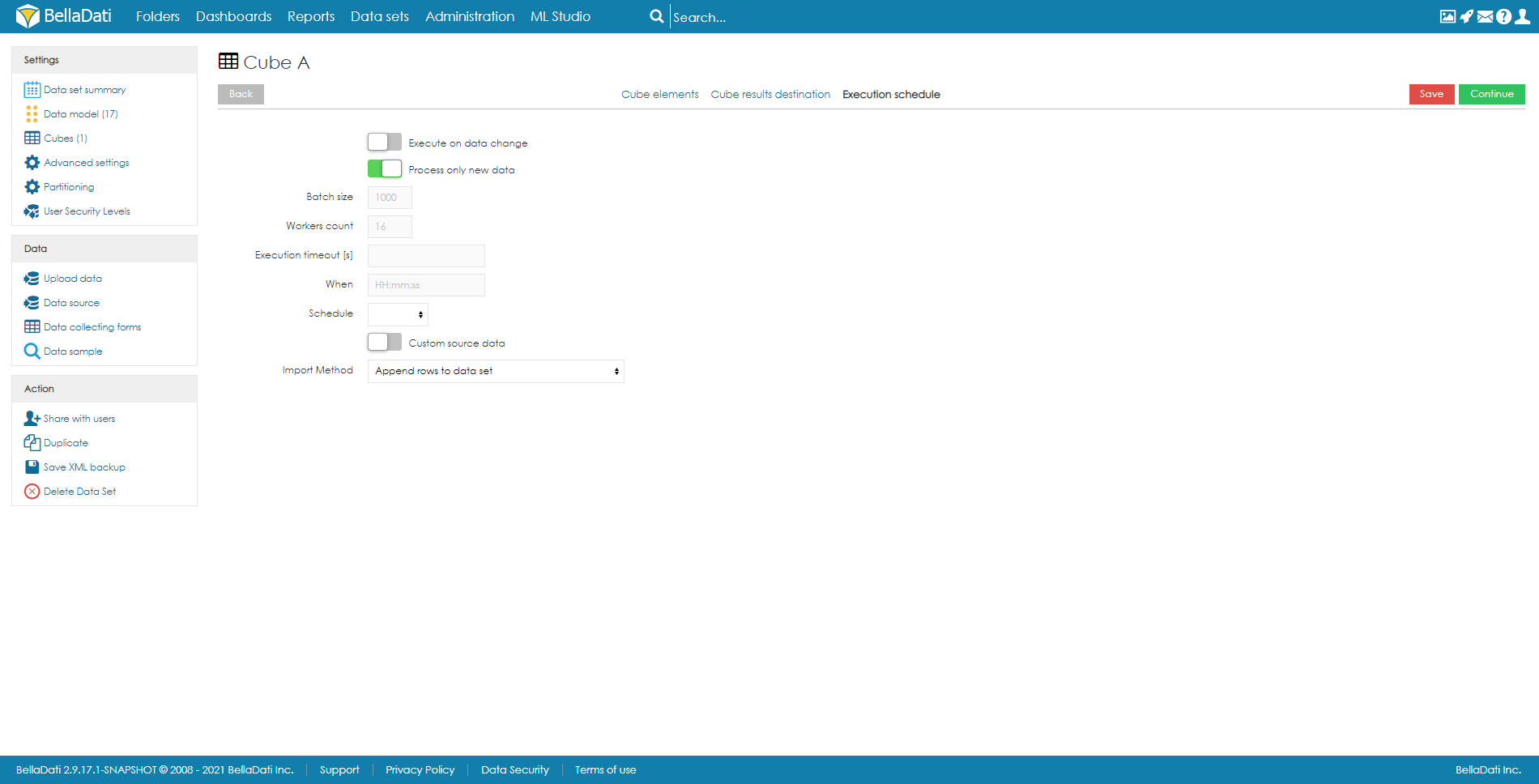
Cube executionAs mentioned above, execution can be run manually, on data change, or by schedule.
Users can also cancel the next scheduled execution by clicking on the date in the column Schedule and confirming the cancellation. Please note this will only cancel the execution and it won't delete it. After running the execution manually, the schedule will be restored. To delete the scheduled execution completely, users have to edit the cube and delete the Execution schedule.
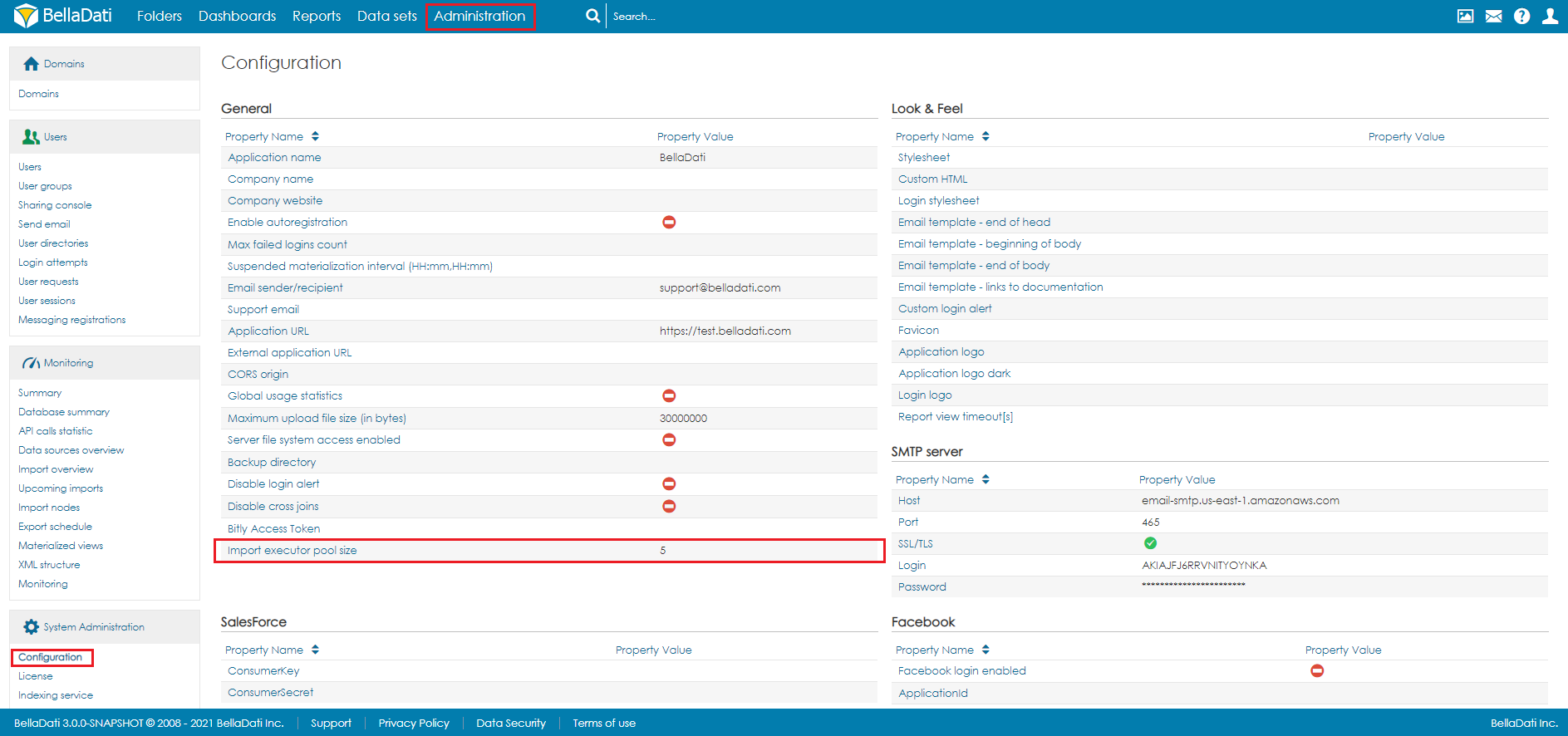
Since the number of cubes could be large, there is a limit to the number of cubes that will be executed at the same time. By default, the number of concurrent cube executions is 5. To change it, open Configuration in Administration. The setting Import executor pool size defines this limit.
TablesTables are used for accessing Big Data Set data using API. Settings are same as in Cube settings. There is an additional option to set UID. This option will add a number of corresponding row and will disable aggregation. See documentation of how to obtain data using API here Backup of Big Data SetWhen using When using the XML backup of the big data set, the target data set and mapping in the cube are not stored. After restoring, they have to be set up again. |
...
| Sv translation | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||
ビッグデータセットは、非常に大量のデータを保存し、事前に計算されたキューブを構築するために使用できる特別なタイプのデータセットです。標準データセットとビッグデータセットの主な違いは以下の通りです:
ビッグデータセットの作成
ビッグデータセットを作成するには、[データセット]ページの[アクション]メニューにある[ビッグデータセットの作成]リンクをクリックし、ビッグデータセットの名前を入力して[作成]をクリックします。
ビッグデータセット サマリーページランディングページ(概要ページ)は、標準のデータセット概要ページに非常に似ています。左側のナビゲーションメニューと、データセットに関する基本情報を含むメインエリアがあります:
アクション
データのインポートデータは、標準のデータセットと同じ方法で大きなデータをインポートできます。ユーザーは、ファイルまたはデータソースからデータをインポートできます。ただし、ビッグデータセットは標準のインジケータと属性を使用していませんが、代わりに各列がオブジェクトとして定義されています。これらのオブジェクトには、様々なデータタイプがあります:
インポート後、ユーザーはデータサンプルページを開いて、データのランダムに選択された部分を表示できます。
オブジェクトの管理オブジェクト(列)は、インポート中に自動的に作成するか、オブジェクト (列) は、インポート中に自動的に作成するか、データモデルページで定義できます。ユーザーは、新しいオブジェクトを追加する際に、名前、データ型、インデックス付け、空の値を含めることができるかどうかを指定できます。 Geoポイント、Geo JSON、ロングテキスト、ブール値、数値はインデックスに登録できないことに注意してください。 行をクリックして、オブジェクトを編集および削除することもできます。 キューブキューブは、ビッグデータセットの集計データを含むデータテーブルです。ユーザーは、集計を定義し、フィルターを適用してデータを制限できます。その後、キューブのデータをデータセットにインポートできます。各ビッグデータセットは複数のキューブを持つことができ、各キューブは異なる設定を持つことができます。 キューブの作成キューブを作成するには、ユーザーは以下の手順に従う必要があります:
キューブのサマリーユーザーは[キューブ]ページで、ビッグデータセットに関連付けられたすべてのキューブを含むテーブルを表示できます。各キューブについて、スケジュールおよび最後のイベントに関する情報が利用可能です。ユーザーは、行またはキューブの名前をクリックすることでキューブを編集することもできます。キューブごとにいくつかのアクションも使用できます:
キューブの実行前述のように、実行は手動で、データ変更時に、またはスケジュールによって実行できます。
ユーザーは、[スケジュール]列の日付をクリックしてキャンセルを確認することにより、次にスケジュールされている実行をキャンセルすることもできます。これは実行をキャンセルするだけで、削除はしないことに注意してください。手動で実行した後、スケジュールが復元されます。スケジュールされた実行を完全に削除するには、ユーザーはキューブを編集し、実行スケジュールを削除する必要があります。
キューブの数が多くなる可能性があるため、同時に実行されるキューブの数には制限があります。デフォルトでは、キューブの同時実行数は5です。変更するには、[管理]から[構成]を開きます。Import executor pool size設定で、制限を定義します。
テーブルテーブルは、API を使用してビッグ・データ・セットのデータにアクセスするために使用されます。設定は、キューブの設定と同じです。 UID を設定するオプションが追加されています。このオプションにより、対応する行の数が追加され、集計が無効になります。 API を使用してデータを取得する方法については、こちらのドキュメントを参照してください。 ビッグデータセットのバックアップビッグデータセットのXMLバックアップを使用する場合、ターゲットデータセットとキューブ内のマッピングは保存されません。復元後、再度構成する必要があります。 |
Overview
Content Tools