Page History
| Sv translation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
Building process of data sets is triggered by the data or structure change in the underlying data sets (when automatic rebuild is enabled) or manually by user. During the building process, all referenced data sets are locked for performing changes. Any changes done to the underlying data sets (Changing joins structure, changing data, etc.) will cause, that the join is flagged as needed to be rebuilt, but the rebuild itself is not scheduled. When the joined data sets is flagged as needed to be rebuilt, the existing materialized view in the back end database is invalidated and only the data preview will be displayed (by default 10 000 rows). Once the rebuilding is finished, all (updated) data will be again available.
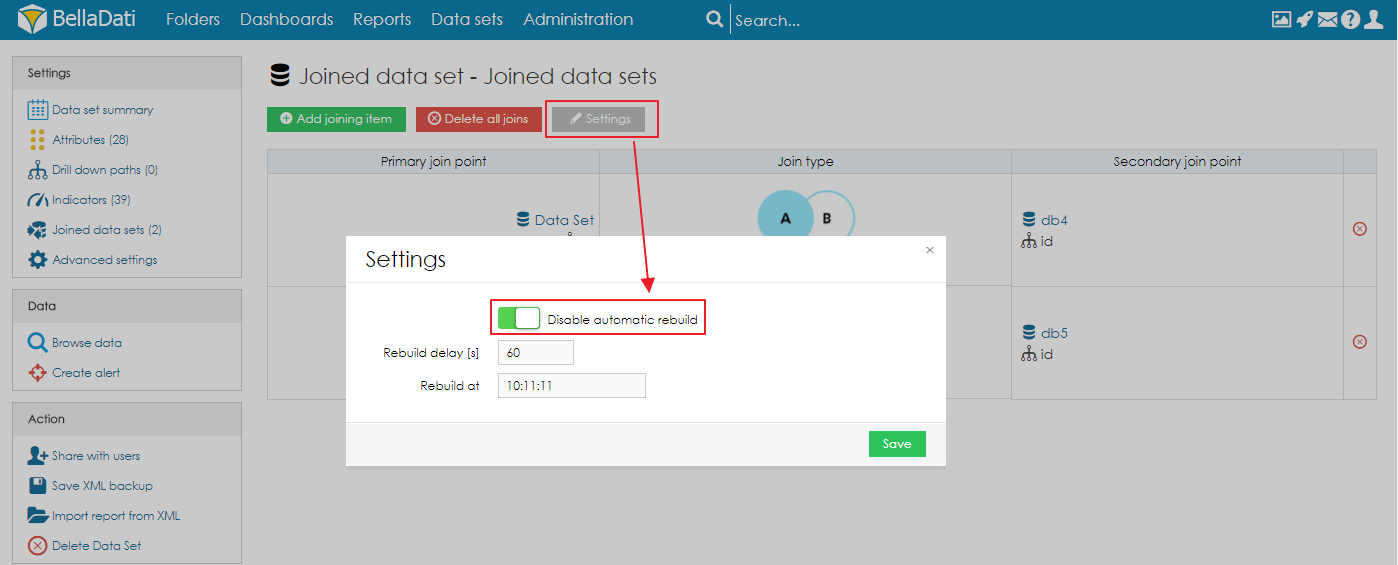
Disabling the building processDisable process for particular data setThere are situations, when we don't want to start the building process automatically, especially in the "big" data sets. It is possible to disable automatic rebuild in the settings of the joined data set:
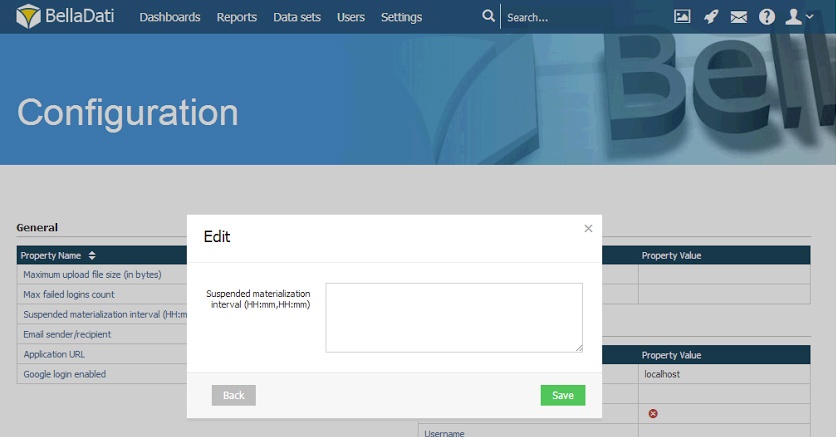
Disable process for all data sets in specific time interval
In specific cases, for example if there are many joined data sets build on several daily updated data sets, each change of the underlying data set triggers the building process. It may cause "locking" errors when the system will try to import data into another referenced data set which is part of the join. For this situations, you can disable the building process for the specific time interval:
Rebuild delay and Custom Rebuild time
In some cases, it might an efficient solution to define a rebuild delay or set up a custom rebuild time. They are useful in situation when there are two or more imports to the underlying data sets scheduled to almost identical time. Without the delay, first import will trigger the rebuild. This will lock the data sets which will cause failure of the rest of the imports. By setting up a delay or a custom rebuild time, the rebuild won't be mediately triggered and all the imports will be successfully finished. By using custom rebuild time, it is possible to schedule the rebuild to a time when the load of the server is the smallest.
It is possible to set them up in the settings of the joined data set:
|

| Sv translation | ||
|---|---|---|
| ||
Každá spojená skupina dát musí byť aktualizovaná predtým ako je možné použiť jej dáta. Proces aktualizácie je automaticky spustený každou zmenou v zdrojových dátach. Počas procesu aktualizácie sú zamknuté všetky prepojené skupiny dát a nie je možné v nich vykonávať zmeny. Vypnutie automatickej aktualizácieVypnutie procesu aktualizácie pre konkrétnu skupinu dátNiekedy však nechceme aby sa naša skupina dát aktualizovala automaticky - typicky pri "veľkých" skupinách dát. Po tom ako bol proces aktualizácie spustený je možné ho vypnúť v informačnou okne v hornej časti stránky prehľadu skupiny dát.
Vypnutie procesu pre všetky skupiny dát v danom časovom úseku
V niektorých prípadoch, keď každá zmena spustí aktualizáciu veľkého počtu skupín dát, napríklad ak existuje množstvo prepojených skupín dát vystavaných na skupinách, ktoré sú denne aktualizované, sa môžu vyskytnúť chyby nakoľko sa aplikácia snaží importovať dáta do skupiny, ktorá je zamknutá, kvôli aktualizácii. Pre takéto prípady je dostupná funkcia, ktorá zastaví proces aktualizácia na určený časový interval:
|
| Sv translation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
データセットの構築プロセスは、基礎となるデータセットのデータや構造の変更(自動再構築が有効な場合)、またはユーザーによる手動でトリガーされます。構築プロセス中、参照データセットはすべて、変更を実行するためにロックされます。基礎となるデータセットに加えられた変更(結合構造の変更、データの変更など)により、必要に応じて結合に再構築のフラグが立てられますが、再構築自体はスケジュールされません。結合されたデータセットに必要に応じて再構築のフラグが立てられると、バックエンドデータベースの既存のマテリアライズドビューが無効になり、データプレビューのみが表示されます(デフォルトでは10,000行)。再構築が完了すると、すべての(更新された)データが再び利用可能になります。
構築プロセスの無効化特定のデータセットのプロセスを無効にする特に「大きな」データセットで、構築プロセスを自動的に開始したくない場合があります。結合されたデータセットの設定で自動再構築を無効にすることができます:
特定の時間間隔ですべてのデータセットのプロセスを無効にする
特定の場合、例えば、毎日更新される複数のデータセットに基づいて多数の結合データセットが構築されている場合、基礎となるデータセットが変更されるたびに構築プロセスがトリガーされます。システムが、結合の一部である別の参照データセットにデータをインポートしようとすると、「ロック」エラーが発生する場合があります。この状況では、特定の時間間隔で構築プロセスを無効にできます:
再構築の遅延とカスタム再構築時間
場合によっては、再構築の遅延を定義したり、カスタムの再構築時間を設定したりすることが効率的なソリューションになる場合があります。それらは、ほぼ同じ時間にスケジュールされた基礎となるデータセットへのインポートが2つ以上ある場合に役立ちます。遅延なしで、最初のインポートが再構築をトリガーします。これにより、データセットがロックされ、残りのインポートが失敗します。遅延またはカスタム再構築時間を設定することにより、再構築は中間的にトリガーされず、すべてのインポートが正常に完了します。カスタム再構築時間を使用することで、サーバーの負荷が最小になる時間に再構築をスケジュールできます。
結合されたデータセットの設定でそれらを設定することが可能です:
|
| Sv translation | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
Der Erstellungsprozess von Datensätzen wird durch die Daten- oder Strukturänderung in den zugrunde liegenden Datensätzen (wenn der automatische Neuaufbau aktiviert ist) oder manuell durch den Benutzer ausgelöst. Während des Bauprozesses werden alle referenzierten Datensätze für Änderungen gesperrt. Das Ändern der Join-Struktur (Join-Punkt hinzufügen, Join-Punkt entfernen, Join-Punkt ändern, Typ ändern, alle entfernen) führt dazu, dass der Join als notwendig für den Neuaufbau gekennzeichnet wird, aber der Neuaufbau selbst nicht geplant wird. Deaktivieren des BauprozessesDeaktivierungsprozess für einen bestimmten DatasetEs gibt Situationen, in denen wir den Bauprozess nicht automatisch starten wollen, insbesondere in den "großen" Datensätzen. Es ist möglich, den automatischen Neuaufbau in den Einstellungen des verbundenen Datasets zu deaktivieren:
Deaktivierungsprozess für alle Datensätze in einem bestimmten Zeitintervall
In Einzelfällen, z.B. wenn es viele verbundene Datensätze gibt, die auf mehreren täglich aktualisierten Datensätzen aufbauen, löst jede Änderung des zugrunde liegenden Datasets den Bauprozess aus. Es kann zu "Sperrfehlern" kommen, wenn das System versucht, Daten in einen anderen referenzierten Dataset zu importieren, der Teil des Joins ist. Für diese Situationen können Sie den Bauprozess für das jeweilige Zeitintervall deaktivieren:
Wiederherstellungsverzögerung und benutzerdefinierte Wiederherstellungszeit
In einigen Fällen kann es eine effiziente Lösung sein, eine Verzögerung für den Neuaufbau zu definieren oder eine benutzerdefinierte Wiederherstellungszeit einzurichten. Sie sind nützlich in Situationen, in denen zwei oder mehr Importe in die zugrunde liegenden Datensätze mit nahezu identischer Zeit geplant sind. Ohne Verzögerung löst der erste Import den Neuaufbau aus. Dadurch werden die Datensätze gesperrt, was zum Ausfall des restlichen Imports führt. Durch die Einrichtung einer Verzögerung oder einer benutzerdefinierten Umbauphase wird der Neuaufbau nicht sofort ausgelöst und alle Importe werden erfolgreich abgeschlossen. Durch die Verwendung der benutzerdefinierten Wiederherstellungszeit ist es möglich, den Wiederherstellungsvorgang auf einen Zeitpunkt zu planen, zu dem die Last des Servers am geringsten ist.
Es ist möglich, sie in den Einstellungen des verbundenen Datasets einzurichten:
|
Overview
Content Tools