Page History
...
| Sv translation | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
列設定
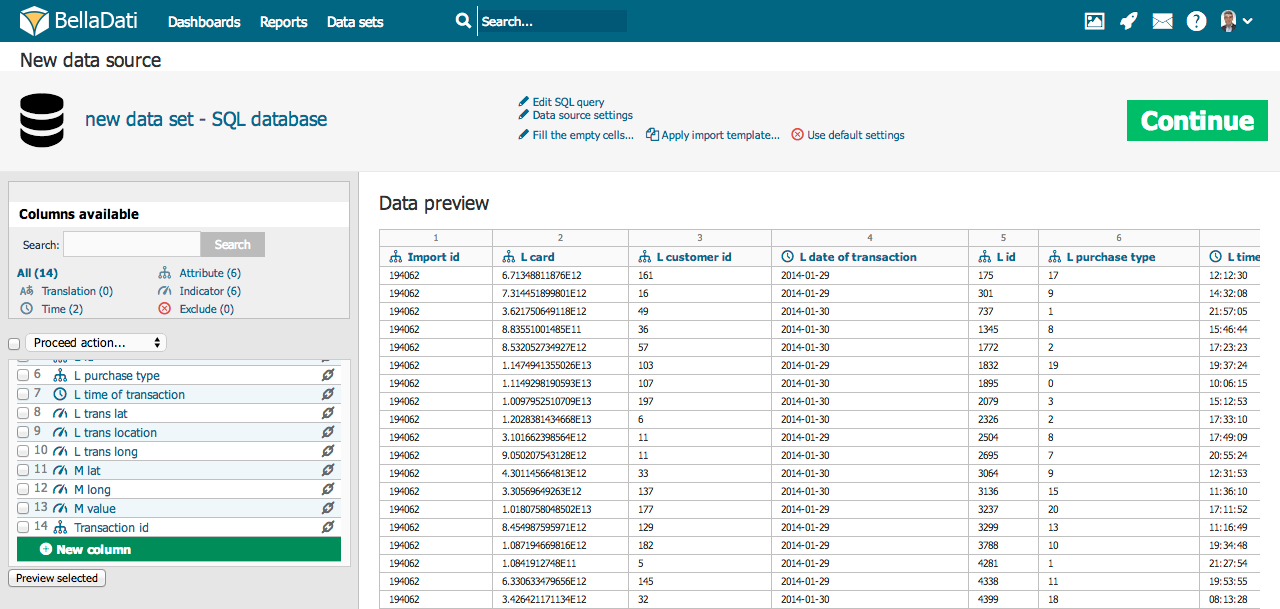
特定の列のタイプを変更する場合は、列のリスト(インポート画面の左側)で選択した列の名前をクリックします。次のステップで、複数の列の意味を1つのタイプに変更することもできます - 選択した列の横にあるチェックボックスをクリックしてマークし、上のメニューから意味を選択します。 列には次の8つの意味があります(データ型): 日付/時刻 (個別) – 特定の行の時刻インデックス。様々な時間形式で表示できます(言語にも依存します - 詳細については、この章の関連部分を参照してください)。 1回のインポートで複数の日付/時刻列を選択できます。 日時 – 特定の行の日時インデックス。様々な日時形式で表示できます(言語にも依存します - 詳細については、この章の関連部分を参照してください)。1回のインポートで複数の日時列を選択できます。ミリセカンドも日時でサポートされています。 ロングテキスト – ロングテキストを定義。この列タイプは、長さが220文字を超える値を含む列に使用する必要があります。視覚化および集計では使用できません。次のユースケースに適しています:
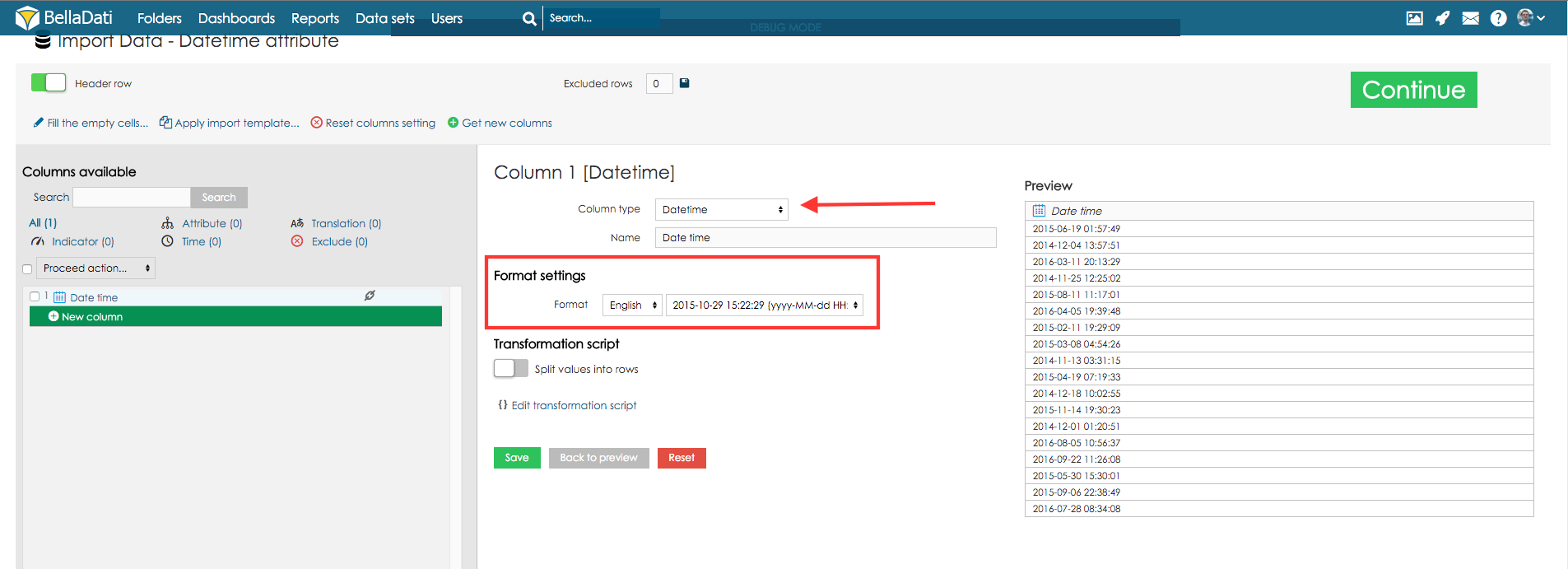
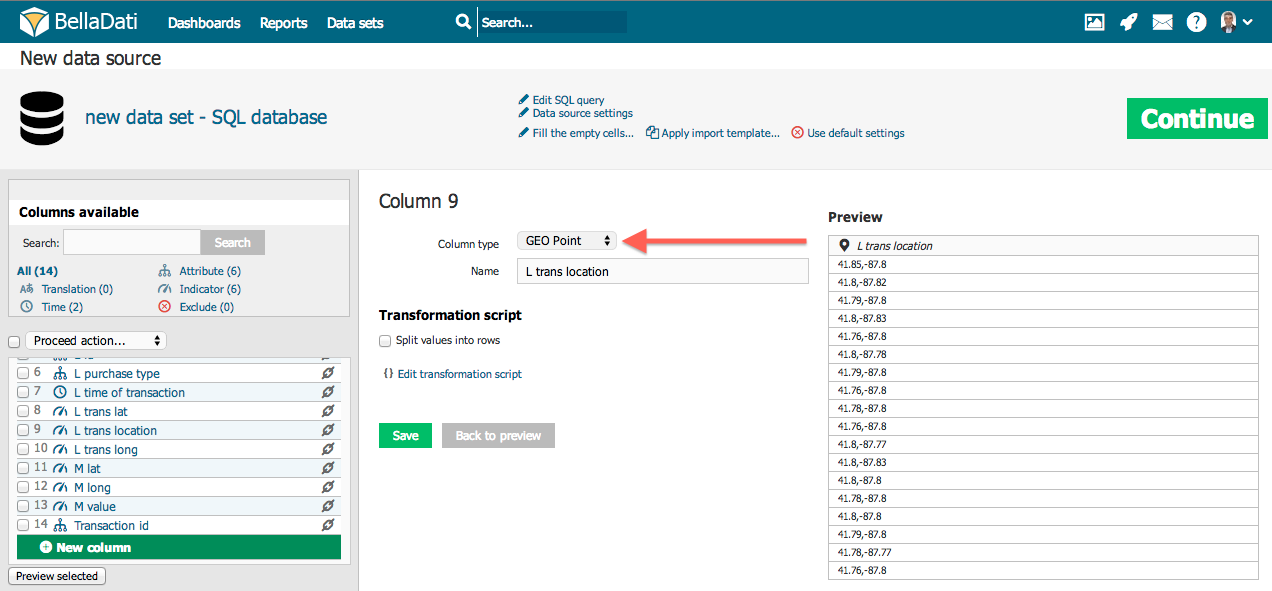
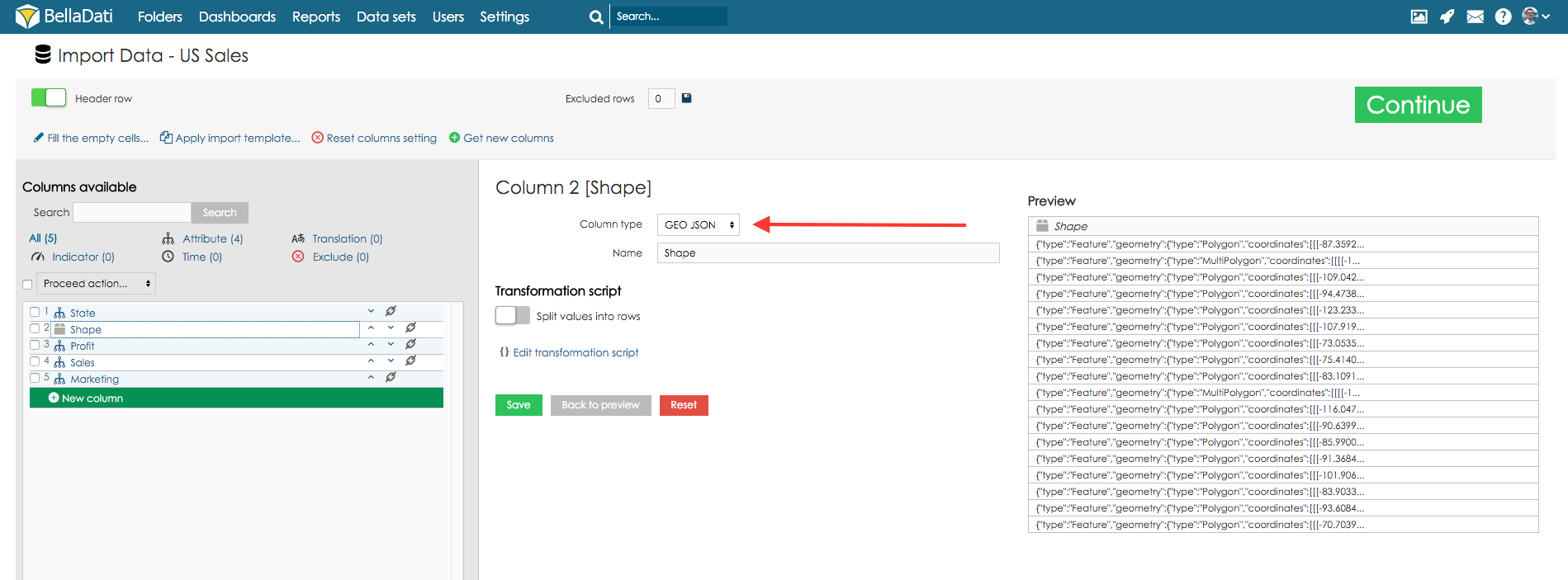
属性 – ドリルダウンパスのカテゴリを定義します。通常、短いテキスト(例: アフィリエイト、製品、顧客、従業員、部門など)です。すべての属性列は、データセットに1つの属性を作成します。これらの属性は、ドリルダウンパスで自由に組み合わせることができます。 Geoポイント – 緯度/経度をGeoポイント属性タイプにマッピングできます。その後、この属性をGeo Mapビュータイプで使用して、特定の場所にデータをプロットできます。 GeoJSON – Geo JSON属性タイプに形状をマッピングできます。その後、この属性をGeo Mapビュータイプで使用して、形状として表示される特定の場所にデータをプロットできます。 翻訳 – 属性として識別される他の列の言語翻訳を定義します。 インジケータ – インジケータは通常、数値データであり、ユーザーの関心の主要なポイントです。 インポートしない – これらの列はまったくインポートされません(列に含まれない、無効、重要でないデータを含む場合に役立ちます)。 「選択したプレビュー」ボタンをクリックすると、マークされた列のプレビューを表示できます。このようにして、データとその意味設定をより適切に表示できます。データに含まれる列が多すぎる場合は、列リストの上にある検索ラベルを使用して適切な列を見つけ、その設定を確認できます。この検索フィールドの下には、特定の種類の列の数を示す統計が表示されます。 日付時刻ソースデータに日付時刻の値が含まれている場合は、それらを日付時刻属性にマップできます。この単一の列には、日付と時刻の両方が含まれます。例: 2014年4月5日午前10時43分43秒 次の例を参照してください:
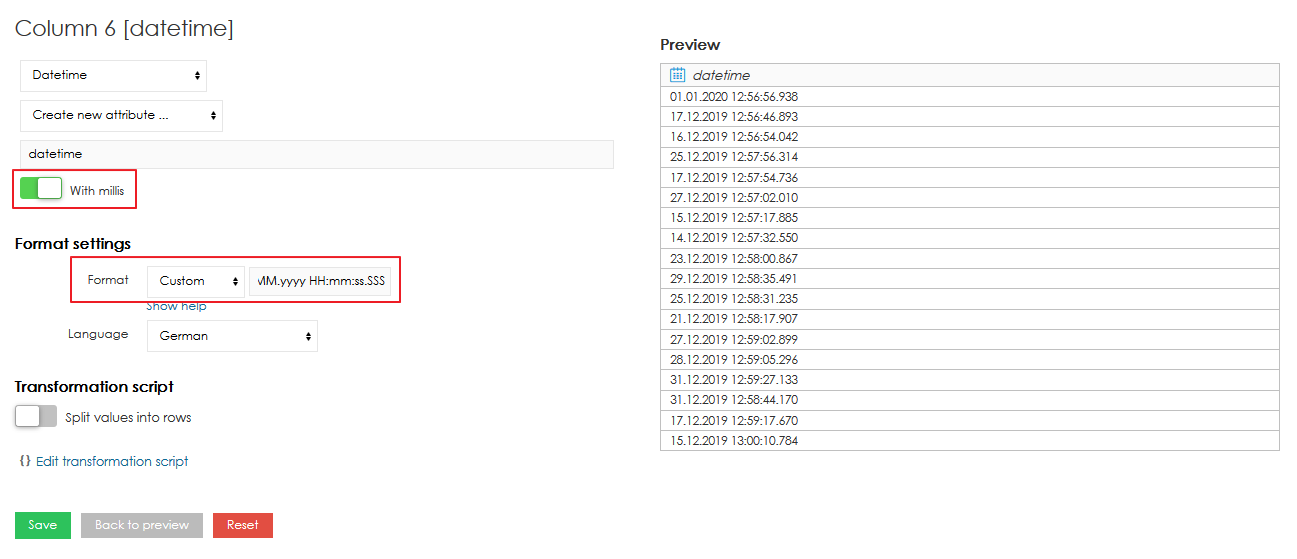
Datetime attribute also supports values with milliseconds. To use the milliseconds, option "" has to be enabled and correct datetime format has to be used ("SSS" for milliseconds, see below). 日時属性はミリセカンドの値もサポートします。ミリセカンドを使用するには、「With millis」オプションを有効にし、正しい日時形式を使用する必要があります(ミリセカンドの場合は「SSS」、以下を参照)。
日付時刻フォーマット各列には特定の形式のタイプがあります。この形式は、インポート中に自動的に検出されます。ただし、時間データが非常に特殊な形式である可能性があります。この場合、様々な言語で利用可能な形式のリストを使用できます。 利用可能な形式から選択しない場合は、データ用に独自のカスタム形式を定義することもできます。この場合、以下のリストから言語を選択し、これらの意味に従ってデータ形式を説明するコードを入力する必要があります(文字数はコードの解釈に影響することに注意してください):
区切り文字は、ソースデータに含まれる区切り文字と等しくなければなりません(スペース、ドット、セミコロンなど)。ソースデータにさらに区切られた列に時間が含まれている場合(月、日、年)、最初にそれらの列をマージする必要があります(この章の前の部分で説明)。次の表は、ソースデータと適切なタイムコードの組み合わせを示しています。
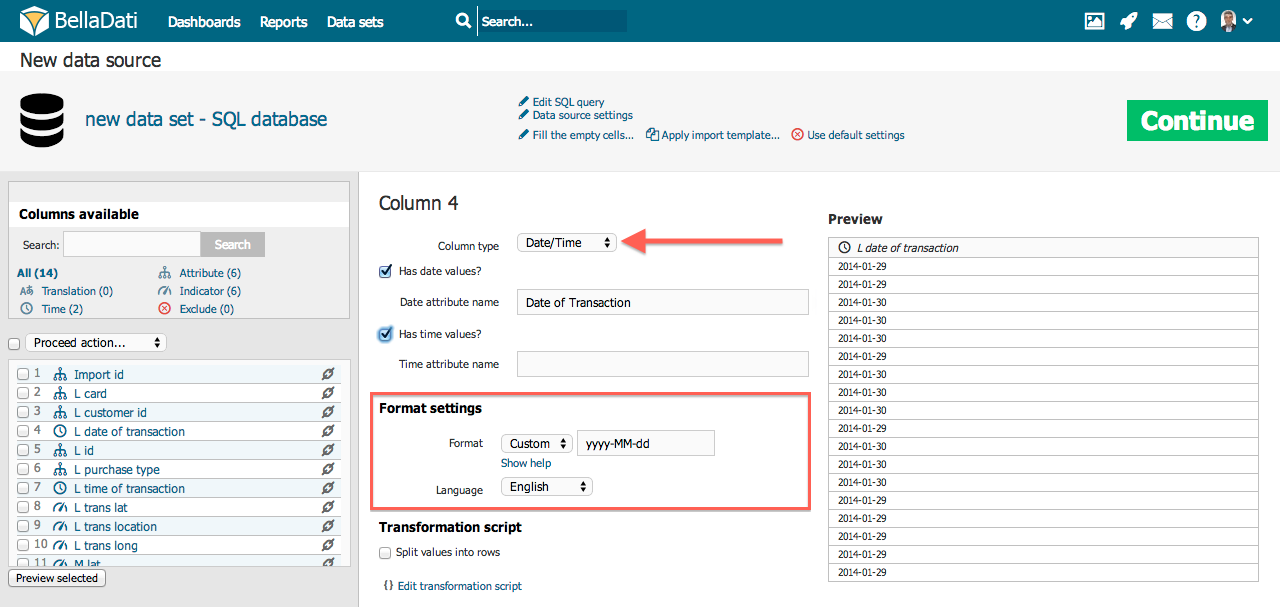
日付/時刻ソースデータに日付/時刻値が含まれている場合、それらを適切な日付属性または時刻属性にマップできます。単一の列には、日付と時刻の両方を含めることができます。 例: 5 Apr 2014 10:43:43 AM(2014年4月5日午前10時43分43秒) この場合、5 Apr 2014(2014年4月5日)の日付部分は日付属性にマップされ、時間部分の10:43:43 AM(午前10時43分43秒)は時間属性にマップされます。次の例を参照してください:
日付/時刻形式の定義は、日付時刻列と同じです。 翻訳BellaDatiでは、属性の翻訳を直接インポートできます。属性の翻訳を設定するには、言語のメタフレーズを含む列に移動し、次のことを行います:
Geoポイント経度/緯度をGEOポイント属性にマッピングするには、緯度/経度を「緯度;経度」の形式で単一の列に指定する必要があります。例: 43.56;99.32。小数点区切り文字は.(ドット)です 。変換スクリプトを使用して実行できます。 例: 経度が列1に、緯度が列2に格納されている場合、value(2) + ";" + value(1)。 |
| Note |
|---|
プロパティはバージョン2.9.1以降で使用可能です。 |
属性については、プロパティを変更できます:
インデックス付き - ユーザーは各列のインデックス作成を無効にできます。これはパフォーマンスに影響する可能性があることに注意してください。ドリルダウンと集計に使用されるすべての列でインデックスを有効にする必要があります。デフォルトでは有効になっています。
空のセルの補充
通常、インポートされたデータには空のセルが含まれます。通常、この空のセルを独自の値("0"、"none"、"N/A"など)に置き換える必要があります。これを行う場合、これらの空のセルに入力する方法の2つの可能性があります:
グローバル– すべての列で空のセルに選択した値を入力します(バッチ列設定の下にあります)
ローカル– 特定の列で選択した値で空のセルを埋めます(特定の列設定ウィンドウにあります)
グローバル変更は、エンコード設定のすぐ下にある青い一番上の行で利用できます。クリックした後、値を入力するだけで、データのすべての空のセルに入力されます。
ローカル変更は、リスト内の列名をクリックで利用可能です。そこで、空のセルに独自の値を入力できます(ただし、この特定の列に対してのみ)。これらの2つの方法を簡単に組み合わせることができます - 例えば、すべての空のセルに「0」値を入力できますが、1つの特定の属性列に「N / A」値を再入力できます。
列のマージ
列のマージ機能により、インポートプロセス中に、より多くのソース列から1つのターゲット列にデータをロードできます。
典型的な使用例は次の通りです:
時間は複数の列に区切られる(日、月、年、時刻を異なる列に)
1つのエンティティを表す2つの列(1人の名と姓など)
列リストのチェーンアイコンをクリックし、マージする別の列を選択し、値の間に追加される適切なセパレーターを選択します(スペース、コンマ、ドット、セミコロン、パイプ)。マージされた列を切断することもできます。
列をマージしてより高度なオプションを設定する別の方法は、変換スクリプトを使用することです。
変換スクリプト
変換スクリプトにより、インポート中に高度なデータ変換が可能になります。これらのスクリプトは、Groovyプログラミング言語の構文に基づいています。
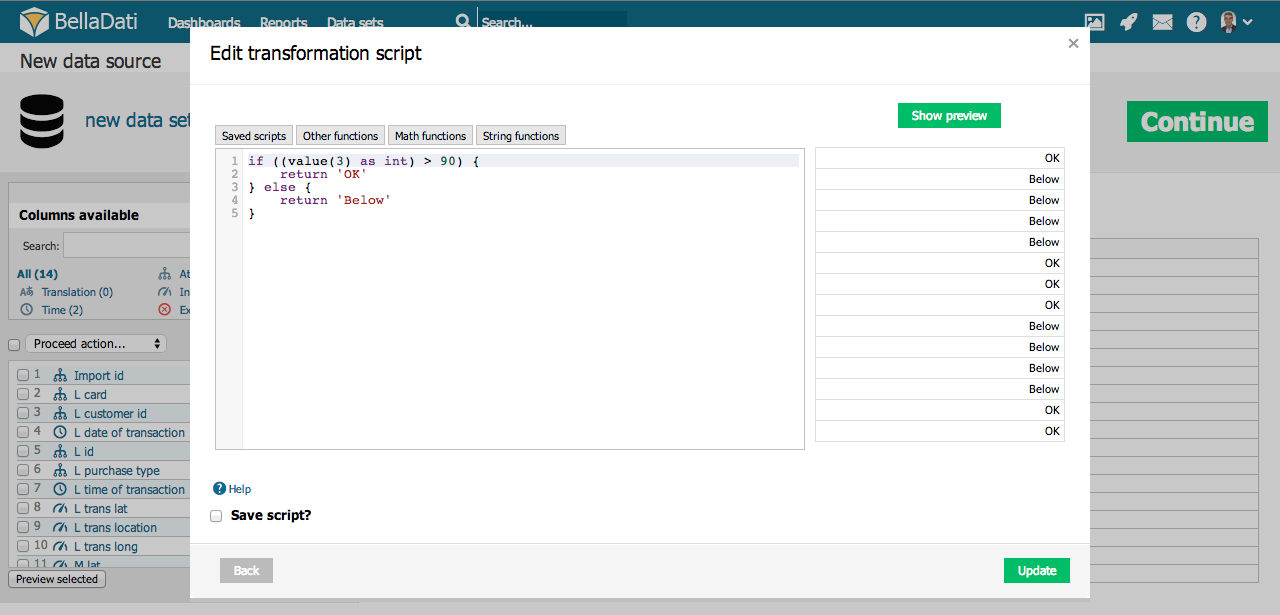
変換スクリプトを使用すると、次のことができます:
定義された機能と条件に従って、BellaDatiデータウェアハウスに保存されている値を変更します。
他の列の値を変換または結合して、新しい列を作成します(日付/時刻、属性、インジケータ)。異なるセルの値には0からインデックスが付けられ、インポート設定画面内の列名の近くに表示されます。
日付/時刻で高度な計算を実行します(例: 2つの日付の間に行われた何らかのアクションの期間)。
基本的なスクリプトコマンド:
value() – 現在のセルの実際の値を返します
value(index) – 実際の行の目的の(インデックス付き)位置のセルの値を返します
name() – 列の名前を返します
name(index) – 目的の位置にある列の名前を返します
format() – 実際の列の形式の値を返します(時間とインジケータ列タイプのみ)
actualDate() – 実際の日付をdd.MM.yyyy形式で返します
actualDate('MM/dd/yyyy') – 選択した形式で実際の日付を返します(例: MM/dd/yyyy)
excludeRow() – 行を除外します
| Info |
|---|
これらの変換は、Data Sourcesからのスケジュールされた自動インポートを含む各インポートに適用されます。 |
詳細については、変換スクリプトガイドを参照してください。
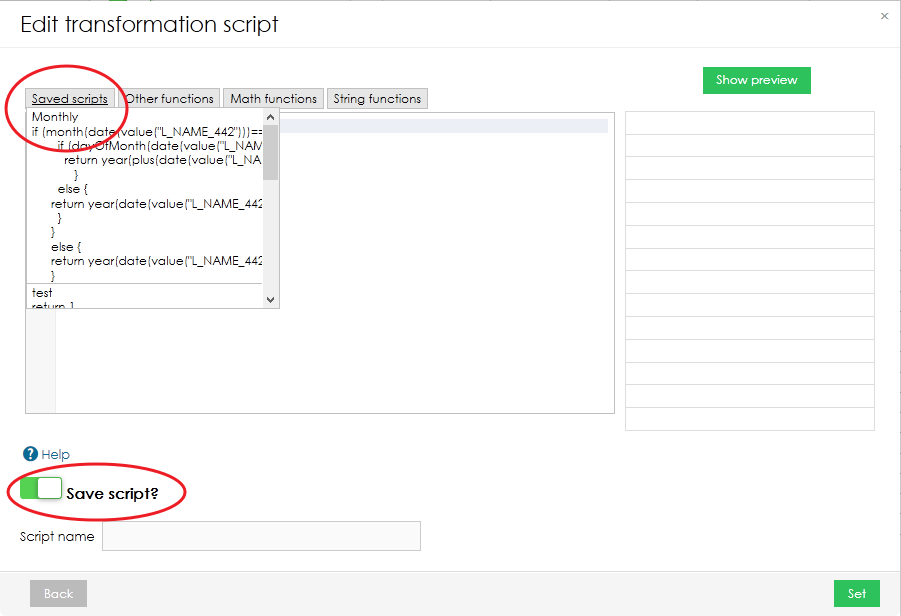
変換スクリプトの再利用
今後スクリプトを再び使用する予定がある場合は、左下隅のトグルを切り替えることでスクリプトを保存できます。保存したスクリプトは、「変換スクリプトの編集」ポップアップウィンドウのトップメニューにあります。
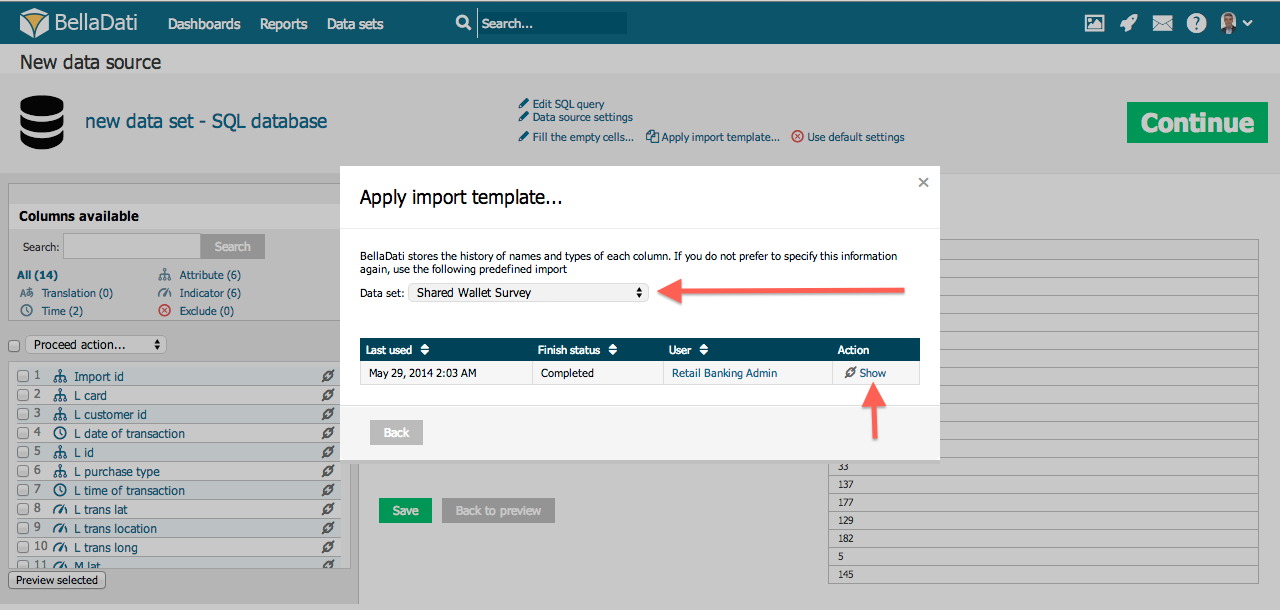
テンプレートのインポート
この機能により、以前のインポートや異なるデータセットからインポート設定を再利用できます。ページの上部にある[テンプレートのインポート]リンクをクリックして使用できます。
ポップアップでは、次のことができます:
データセットの選択
要求された日付とインポートステータスに従って、このデータセットに割り当てられたインポートテンプレートを選択します
インポートテンプレートの詳細を表示(列設定)
インポートテンプレートの並べ替え
| Note |
|---|
テンプレートを適用すると、現在のすべてのインポート設定が上書きされます。 |
アクセスできるすべてのデータセットで使用されている既存のインポート設定から選択できます。これらのテンプレートは、インポートが正常に終了すると自動的に作成されます。
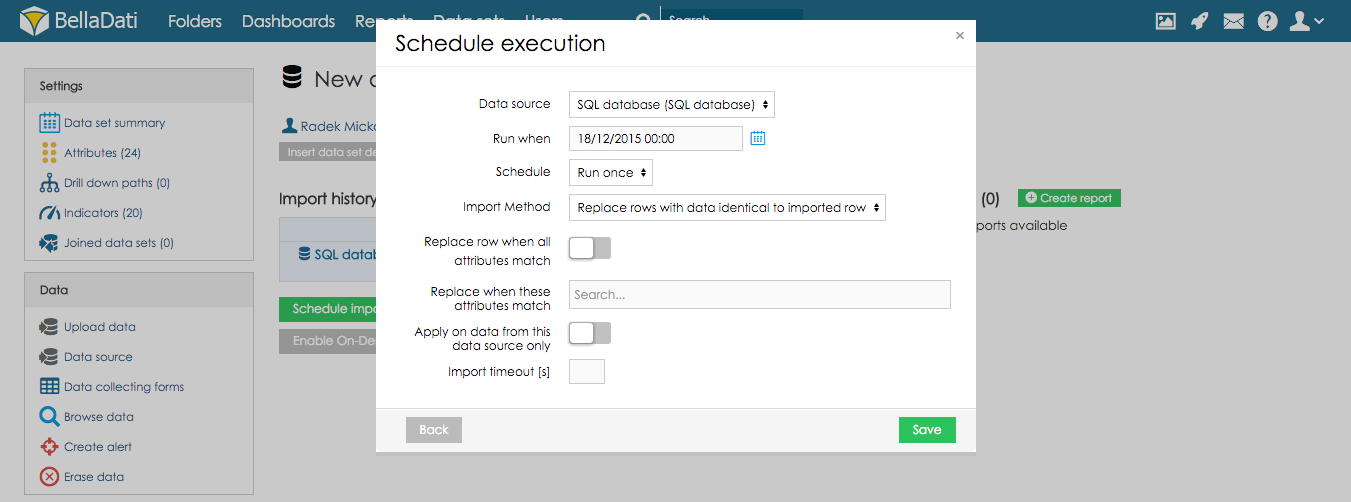
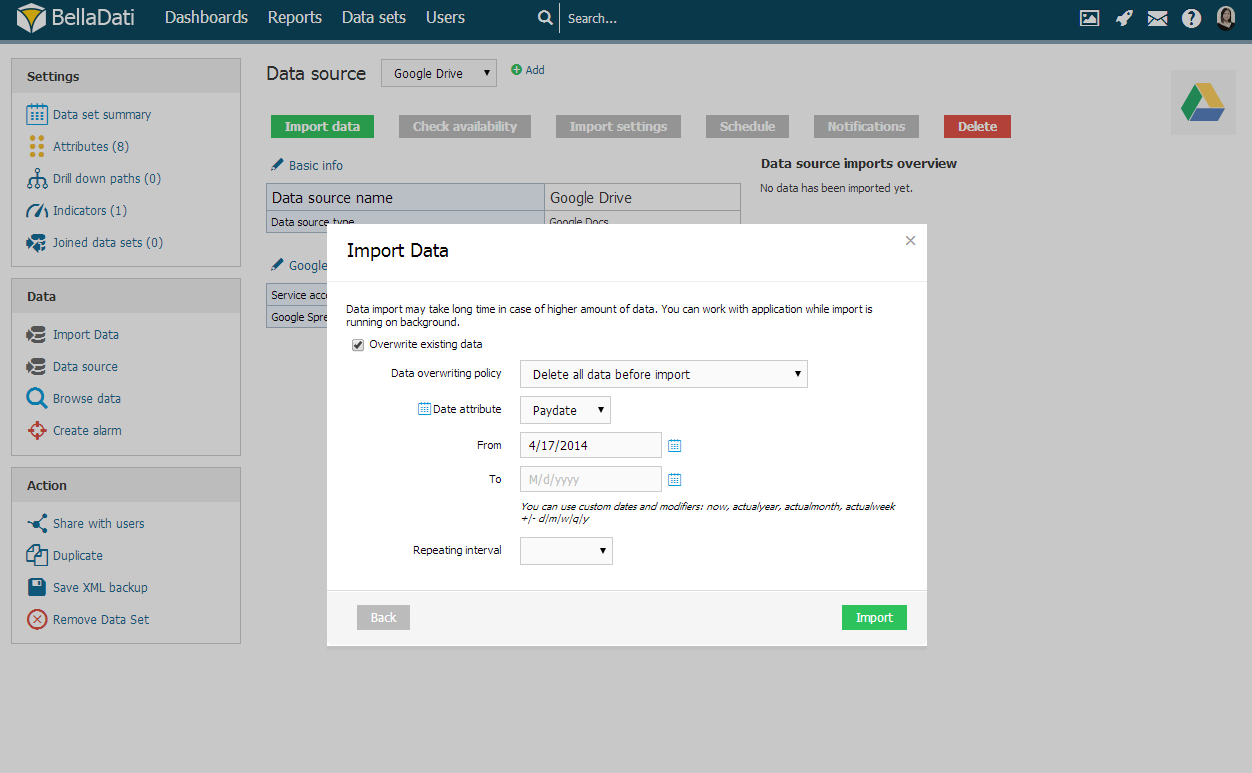
データの上書きポリシー
データセットに既存のデータがある場合、これらのデータをどう処理するかを次のオプションから選択できます:
データセットに行を追加: インポートされたデータは既存のデータに追加されます(デフォルト)。
データセットのすべての行を削除: データセットのすべての行を削除します(1つのデータソースにのみに適用可)。
- 日付範囲に基づいてすべての行を削除: 選択された日付範囲のデータが削除されます。
インポートされた行と同一データの行を削除: インポートされたデータと同じ選択された属性の組み合わせを持つすべての既存のレコードを削除します。
インポートされた行と同一データで行を置き換え: インポートされたデータと同じ選択された属性の組み合わせですべてのレコードを置換します。
インポートされた行と同一データで行を置き換え
属性に従ってデータを置換する場合、BellaDatiでは次のことができます:
すべての属性の選択
特定の属性を選択 – インポート手順は、目的の属性を比較し、現在の属性がデータベースに既に保存されている値と等しい場合、行を上書きします。
インポートされた行と同一データの行を削除
属性に従ってデータを削除する場合、BellaDatiでは次のことができます:
すべての属性の選択
特定の属性を選択 - インポート手順は、目的の属性を比較し、現在の属性がデータベースに既に保存されている値と等しい場合、行を上書きします。
このインポート方法は、選択したデータソースからインポートされたデータにのみ適用できます。
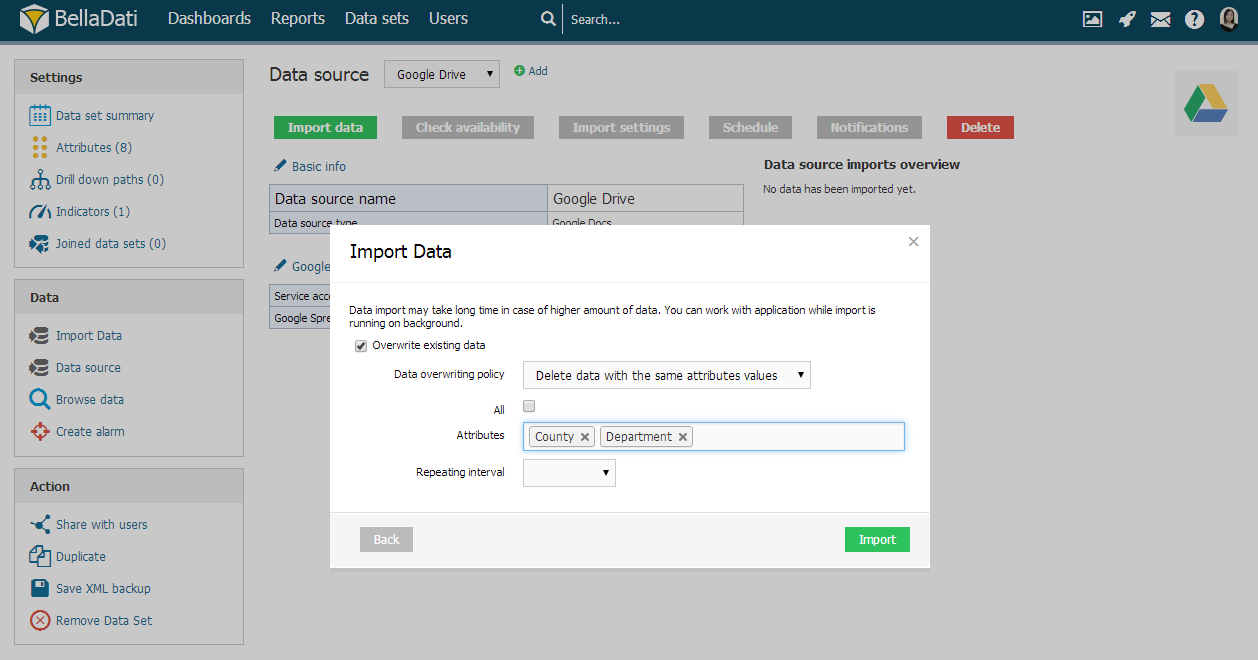
このインポート方法は、選択したデータソースからインポートされたデータにのみ適用できます。
インポート前にすべてのデータを削除
インポート前にすべてのデータを削除する場合、BellaDatiでは特定の時間間隔を選択できます。データの消去を制限するには、FromおよびToを設定します。
| Tip |
|---|
カレンダーアイコンを使用して、目的の時間間隔を快適に選択します。 |
| Info |
|---|
カスタムの日付と修飾子を使用できます: now、actualyear、actualmonth、actualweek +|- d|m|w|q|y。 |
インポートの進行状況
| Note |
|---|
大量のデータのインポートが完了するまでに時間がかかる場合があります。 |
データは非同期にインポートされているため、インポート中もBellaDati機能を使用できます。ユーザーはインポート中にログアウトすることもできます。
データセットの概要ページには、実際のインポートの進行状況バーと推定時間と割合が表示されます。
インポートが完了する前に、次のことができます:
- 実行中のインポートをキャンセル: このインポートに関連するすべてのデータは、BellaDatiデータウェアハウスから消去されます。
メールによる通知: インポートが完了すると、電子メールが送信されます。
次に
...
Overview
Content Tools