Page History
| Sv translation | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
Big Data Sets are a special type of data sets which can be used to store very large amount of data and build pre-calculated cubes. The main differences between standard data sets and big data sets are:
Creating Big Data Set
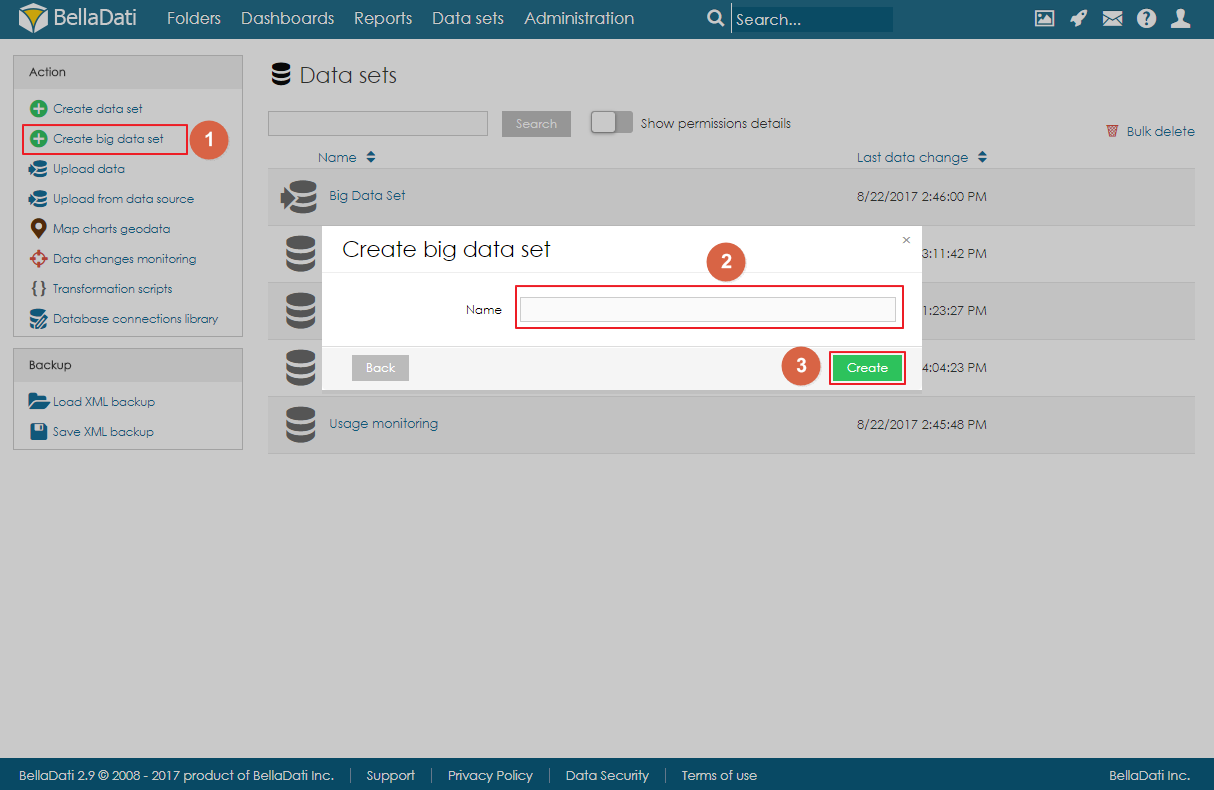
Big Data Set can be created by clicking on the link Create big data set in the Action menu on Data Sets page, filling in the name of the big data set and clicking on Create.
Big Data Set summary pageThe landing page (summary page) is very similar to standard data set summary page. There are a left navigation menu and the main area with basic information about the data set:
Importing DataData can be imported to big the data the same way as to standard data set. Users can either import data from a file or from a data source. However, big data set is not using standard indicators and attributes, but instead, each column is defined as an object. These objects can have various data types:
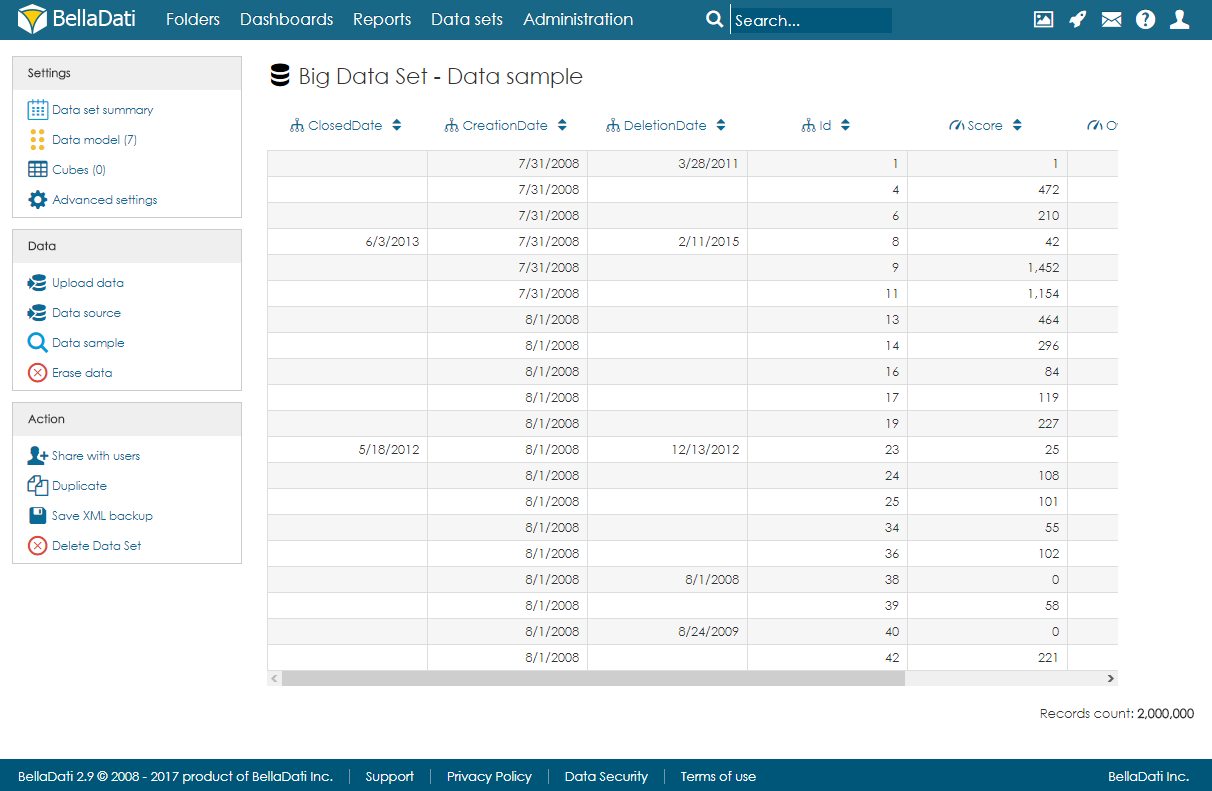
After import, users can open the data sample page to see a randomly selected part of the data.
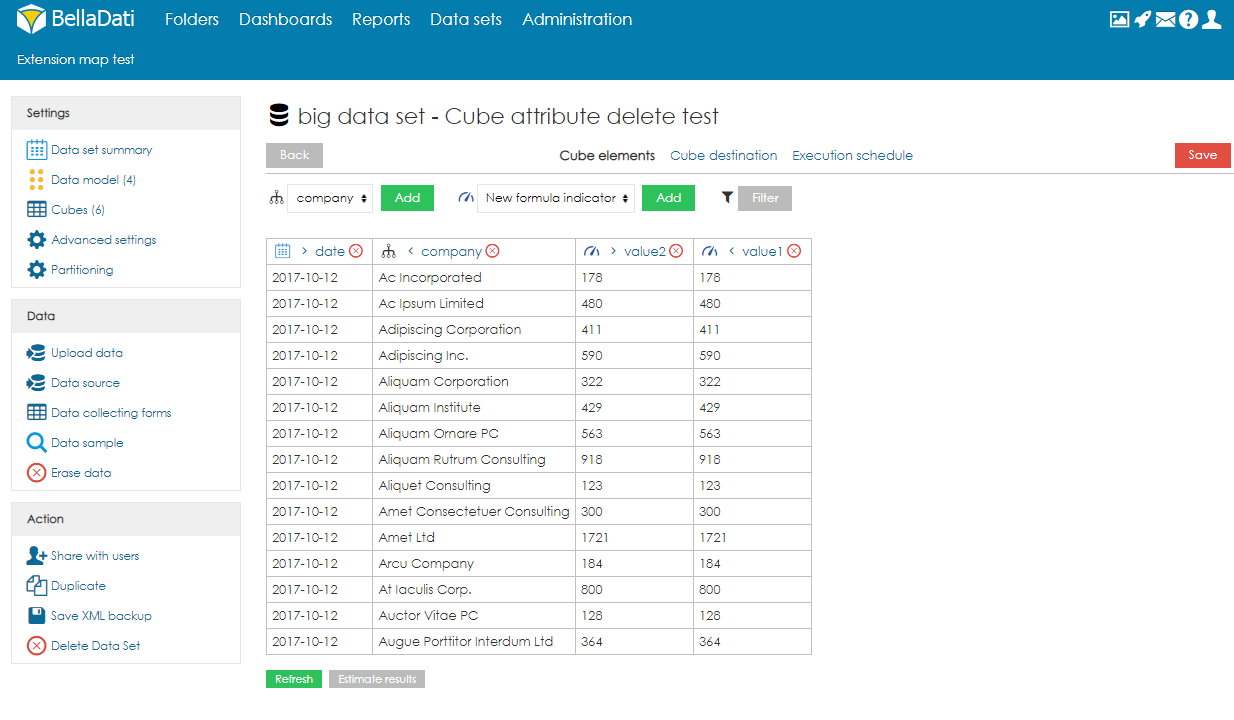
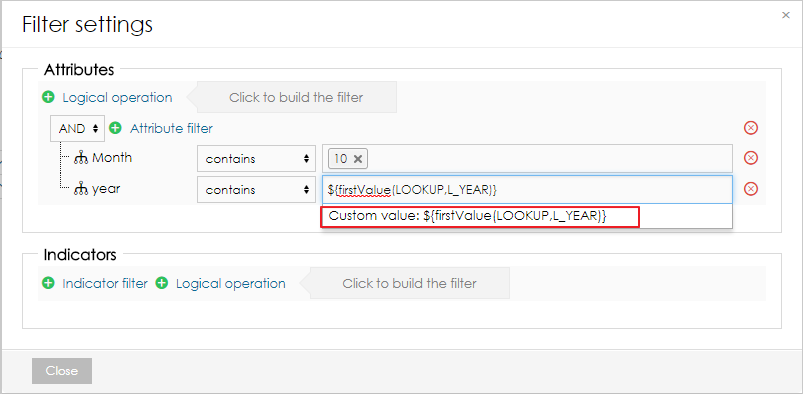
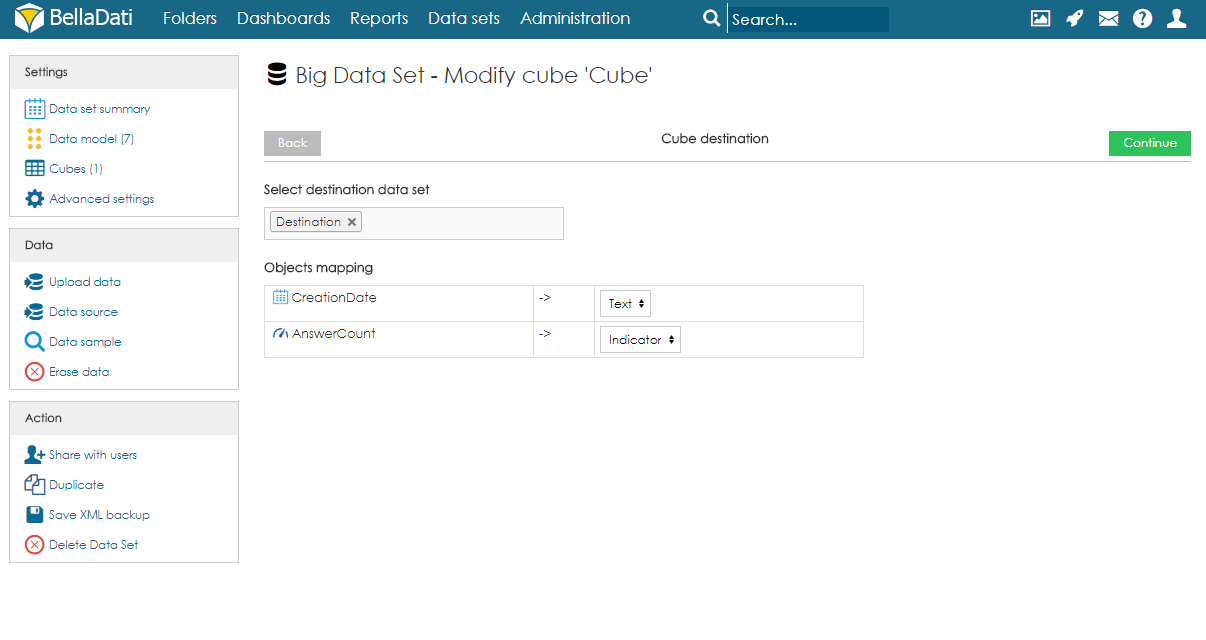
Managing ObjectsObjects (columns) can be created automatically during the import or they can be defined on the data model page. When adding a new object, users can specify its name, data type, indexation and whether they can contain empty values or not. Please note that GEO point, GEO JSON, long text, boolean and numeric cannot be indexed. Objects can be also edited and deleted by clicking on the row. CubesCube is a data table which contains aggregated data from the big data set. Users can define the aggregation and also limit the data by applying filters. Data from the cube can be then imported to a data set. Each big data set can have more than one cube and each cube can have different settings. Creating CubeTo create a cube, users need to follow these steps:
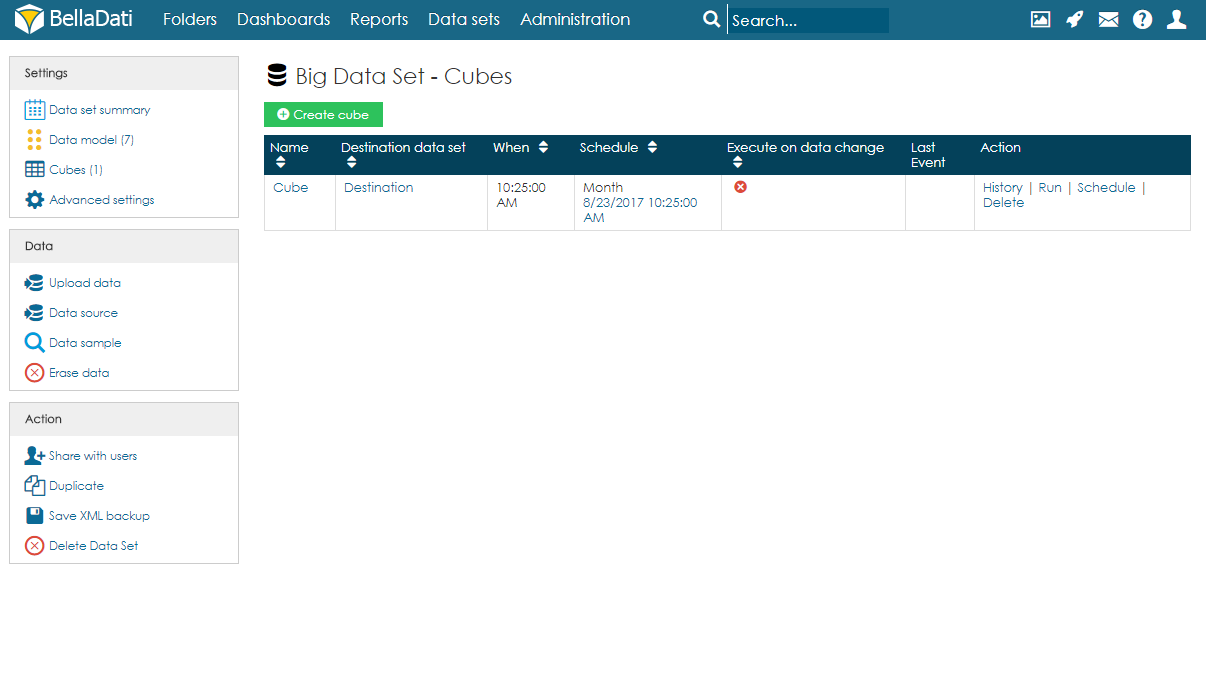
Cubes summaryOn the Cubes page, users can see a table with all cubes associated with the big data set. For each cube, information about the schedule and last event are available. Users can also edit the cube by clicking anywhere on the row or on the name of the cube. Several actions are also available for each cube:
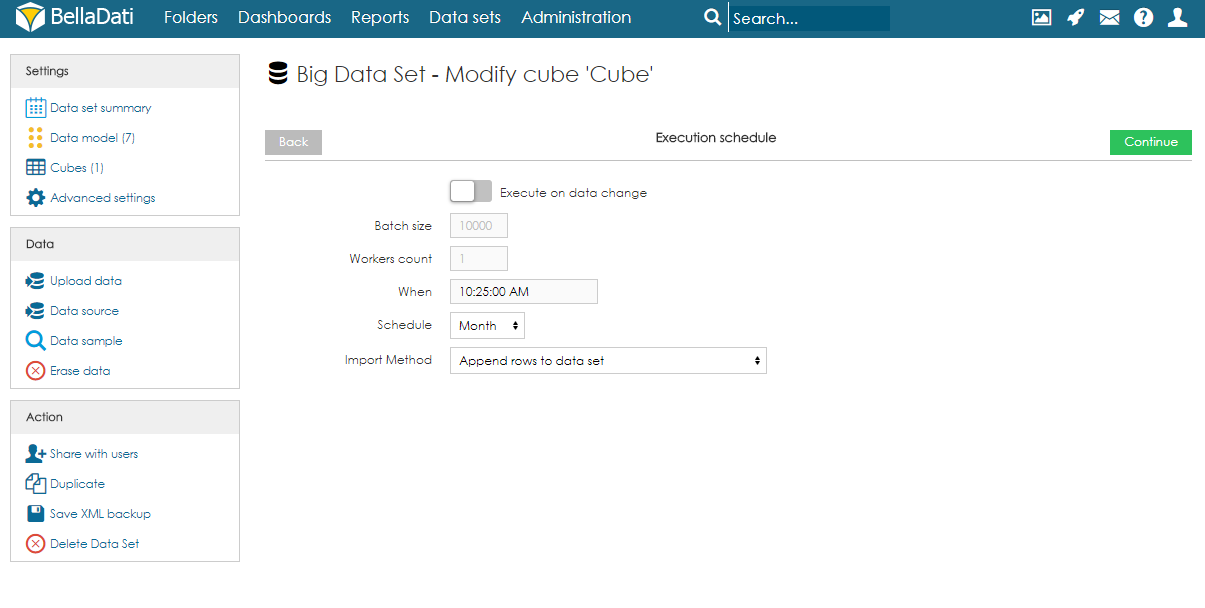
Cube executionAs mentioned above, execution can be run manually, on data change or by schedule.
Users can also cancel the next scheduled execution by clicking on the date in the column Schedule and confirming the cancellation. Please note this will only cancel the execution and it won't delete it. After running the execution manually, the schedule will be restored. To delete the scheduled execution completely, users have to edit the cube and delete the Execution schedule. Backup of Big Data SetWhen using the XML backup of big data set, the target data set and mapping in the cube is not stored. After restoring, they have to be set up again.
|
| Sv translation | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
Große Datensätze [Original Seitentitel]
Big Data Sets sind eine spezielle Art von Datensätzen, die verwendet werden können, um sehr große Datenmengen zu speichern und vorbereitete Cubes zu bilden.
Creating Big Data Set
Ein großer Datensatz kann erstellt werden, indem Sie auf den Link Großen Datensatz erstellen im Menü Aktion auf der Seite Datensätze klicken, den Namen des großen Datensatzes eingeben und auf Erstellen klicken.
Zusammenfassungsseite für große DatensätzeDie Landing Page (Summary Page) ist der Standard-Datensatzübersichtsseite sehr ähnlich. Es gibt ein linkes Navigationsmenü und den Hauptbereich mit grundlegenden Informationen über den Datensatz:
Daten importierenDaten können wie bei einem Standarddatensatz in große Datenmengen importiert werden. Benutzer können entweder Daten aus einer Datei oder aus einer Datenquelle importieren. Der große Datensatz verwendet jedoch keine Standardkennzeichen und -attribute, sondern jede Spalte ist als Objekt definiert. Diese Objekte können verschiedene Datentypen haben:
Nach dem Import können Benutzer die Datenprobenseite öffnen, um einen zufällig ausgewählten Teil der Daten anzuzeigen.
Objekte verwaltenObjekte (Spalten) können beim Import automatisch angelegt oder auf der Datenmodellseite definiert werden. Beim Hinzufügen eines neuen Objekts können Benutzer dessen Namen, Datentyp, Indexierung und ob sie leere Werte enthalten dürfen oder nicht, angeben. Bitte beachten Sie, dass GEO point, GEO JSON, Langtext, boolesch und numerisch nicht indiziert werden können. Sie können auch Objekte bearbeiten und löschen, indem Sie auf die Zeile klicken. CubesCube ist eine Datentabelle, die aggregierte Daten aus dem großen Datensatz enthält. Benutzer können die Aggregation definieren und die Daten durch die Anwendung von Filtern einschränken. Daten aus dem Cube können dann in einen Datensatz importiert werden. Jeder große Datensatz kann mehr als einen Cube haben und jeder Cube kann unterschiedliche Einstellungen haben. Cube erstellenUm einen Cube zu erstellen, müssen Benutzer diesen Schritten folgen:
Zusammenfassung der CubesAuf der Seite Cubes sehen die Benutzer eine Tabelle mit allen Cubes, die dem großen Datensatz zugeordnet sind. Für jeden Cube stehen Informationen über den Zeitplan und die letzte Veranstaltung zur Verfügung. Benutzer können den Würfel auch bearbeiten, indem sie irgendwo auf die Zeile oder den Namen des Würfels klicken. Für jeden Cube stehen auch mehrere Aktionen zur Verfügung:
Cube-AusführungWie bereits erwähnt, kann die Ausführung manuell, bei Datenänderung oder nach Zeitplan erfolgen.
Der Benutzer kann auch die nächste geplante Ausführung abbrechen, indem er auf das Datum in der Spalte Zeitplan klickt und die Abbestellung bestätigt. Bitte beachten Sie, dass dadurch nur die Ausführung abgebrochen und nicht gelöscht wird. Nachdem die Ausführung manuell ausgeführt wurde, wird der Zeitplan wiederhergestellt. Um die geplante Ausführung vollständig zu löschen, müssen Benutzer den Cube bearbeiten und den Ausführungsplan löschen. Sicherung eines großen DatensatzesBei der Verwendung der XML-Sicherung von großen Datensätzen werden der Zieldatensatz und das Mapping im Cube nicht gespeichert. Nach der Wiederherstellung müssen sie neu eingerichtet werden.
|
Overview
Content Tools