Page History
| Sv translation | ||
|---|---|---|
| ||
Custom source data can display report source data directly from cube linked to the current data set. ENABLING CUSTOM DATA SOURCE IN CUBECustom Data Source needs to be activated firstly in the 3rd step of the cube settings.
Your Custom Data Source will be linked with the data set used as the destination of your Cube. ENABLING CUSTOM DATA SOURCE DATASETCustom source data need to be enabled for each data set. Open data set Advanced Settings and Enable Custom Data Source function.
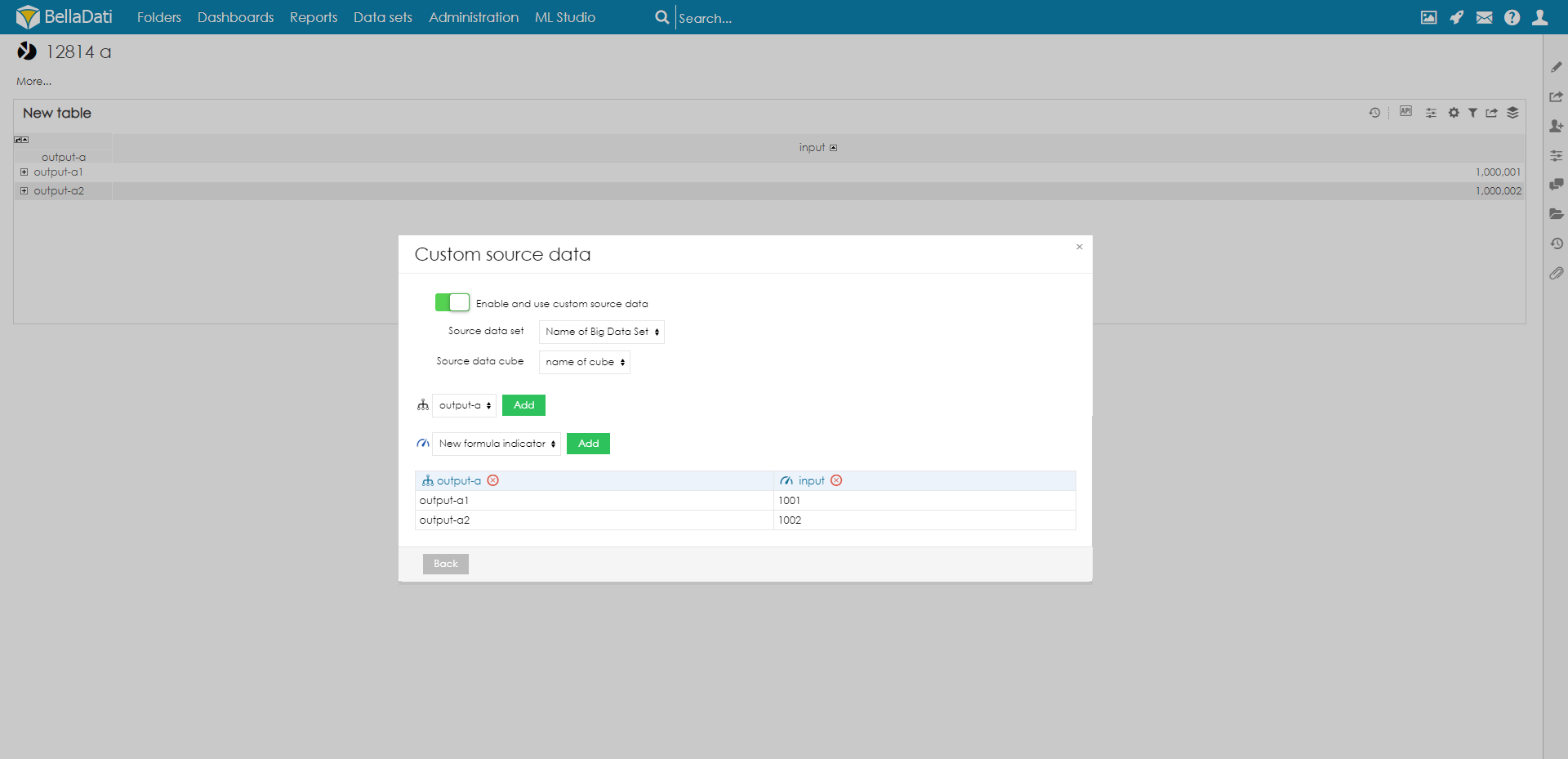
Set up a custom data source in the reportAfter you enable the Custom Data Source function in the data set, the Custom source data option will be available in the table settings:
The following settings are available:
Select Attributes and Indicator in the order they should be displayed as the table source data. The applied source data settings will be applied to the selected table.
|
| Sv translation | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||
Big Data Sets sind eine spezielle Art von Datensätzen, die verwendet werden können, um sehr große Datenmengen zu speichern und vorbereitete Cubes zu bilden.
Erstellen eines großen Datensatzes
Ein großer Dataset kann erstellt werden, indem Sie auf den Link Großen Dataset erstellen im Menü Aktion auf der Seite Datensätze klicken, den Namen des großen Datasets eingeben und auf Erstellen klicken. Zusammenfassungsseite für große DatensätzeDie Landing Page (Summary Page) ist der Standard-Datasetübersichtsseite sehr ähnlich. Es gibt ein linkes Navigationsmenü und den Hauptbereich mit grundlegenden Informationen über den Dataset:
Daten importierenDaten können wie bei einem StandardDataset in große Datenmengen importiert werden. Benutzer können entweder Daten aus einer Datei oder aus einer Datenquelle importieren. Der große Dataset verwendet jedoch keine Standardkennzeichen und -attribute, sondern jede Spalte ist als Objekt definiert. Diese Objekte können verschiedene Datentypen haben:
Nach dem Import können Benutzer die Datenprobenseite öffnen, um einen zufällig ausgewählten Teil der Daten anzuzeigen. Objekte verwaltenObjekte (Spalten) können beim Import automatisch angelegt oder auf der Datenmodellseite definiert werden. Beim Hinzufügen eines neuen Objekts können Benutzer dessen Namen, Datentyp, Indexierung und ob sie leere Werte enthalten dürfen oder nicht, angeben. Bitte beachten Sie, dass GEO point, GEO JSON, Langtext, boolesch und numerisch nicht indiziert werden können. Sie können auch Objekte bearbeiten und löschen, indem Sie auf die Zeile klicken. CubesCube ist eine Datentabelle, die aggregierte Daten aus dem großen Dataset enthält. Benutzer können die Aggregation definieren und die Daten durch die Anwendung von Filtern einschränken. Daten aus dem Cube können dann in einen Dataset importiert werden. Jeder große Dataset kann mehr als einen Cube haben und jeder Cube kann unterschiedliche Einstellungen haben. Cube erstellenUm einen Cube zu erstellen, müssen Benutzer diesen Schritten folgen:
Zusammenfassung der CubesAuf der Seite Cubes sehen die Benutzer eine Tabelle mit allen Cubes, die dem großen Dataset zugeordnet sind. Für jeden Cube stehen Informationen über den Zeitplan und die letzte Veranstaltung zur Verfügung. Benutzer können den Würfel auch bearbeiten, indem sie irgendwo auf die Zeile oder den Namen des Würfels klicken. Für jeden Cube stehen auch mehrere Aktionen zur Verfügung:
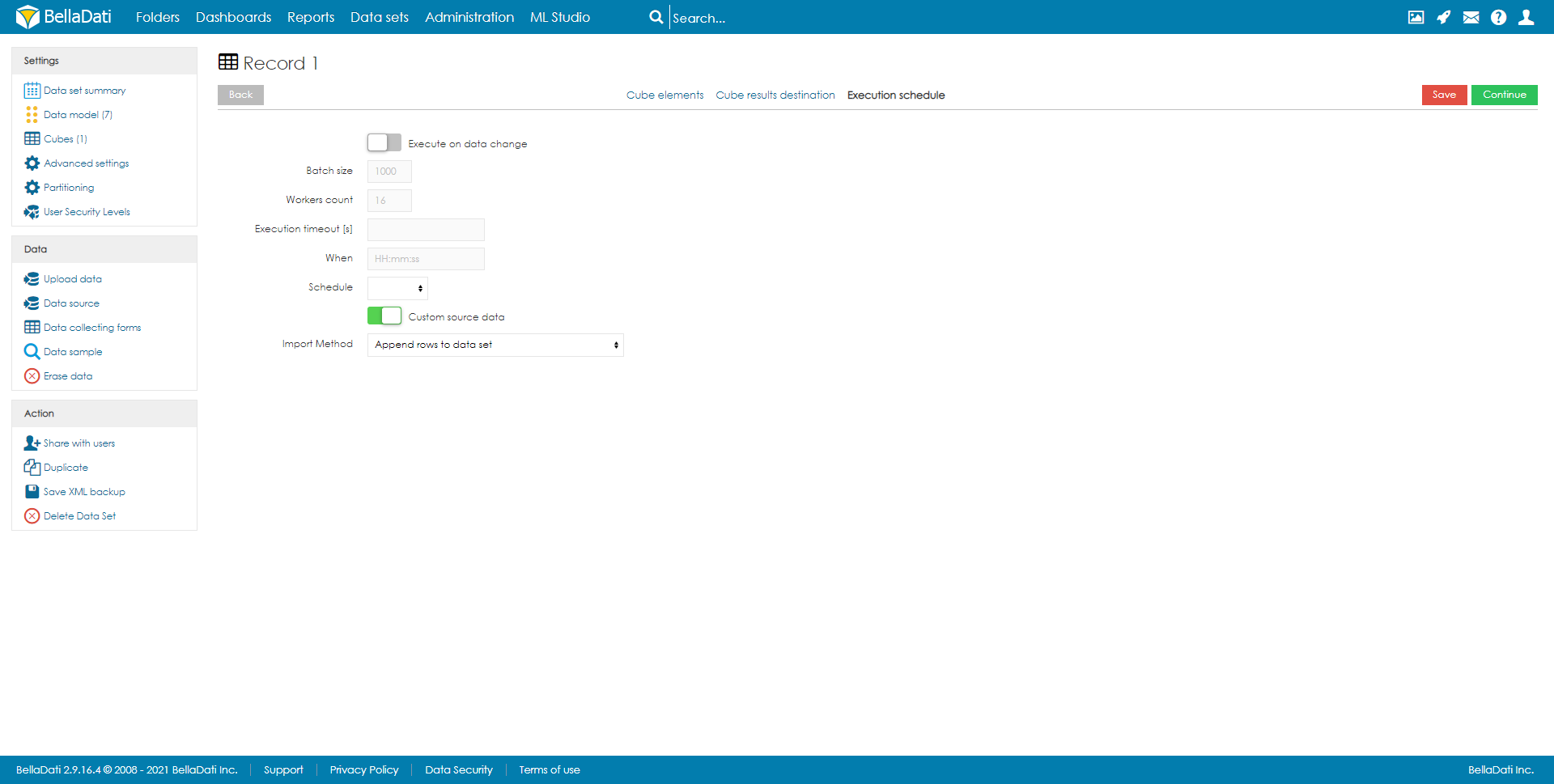
Cube-AusführungWie bereits erwähnt, kann die Ausführung manuell, bei Datenänderung oder nach Zeitplan erfolgen.
Der Benutzer kann auch die nächste geplante Ausführung abbrechen, indem er auf das Datum in der Spalte Zeitplan klickt und die Abbestellung bestätigt. Bitte beachten Sie, dass dadurch nur die Ausführung abgebrochen und nicht gelöscht wird. Nachdem die Ausführung manuell ausgeführt wurde, wird der Zeitplan wiederhergestellt. Um die geplante Ausführung vollständig zu löschen, müssen Benutzer den Cube bearbeiten und den Ausführungsplan löschen. Sicherung eines großen DatasetsBei der Verwendung der XML-Sicherung von großen Datensätzen werden der Zieldataset und das Mapping im Cube nicht gespeichert. Nach der Wiederherstellung müssen sie neu eingerichtet werden.
|
| Sv translation | ||
|---|---|---|
| ||
カスタムデータソースは、現在のデータセットにリンクされたキューブから直接レポートのソースデータを表示できます。 レポートをビッグデータセットに直接作成することはできません。最初にキューブを作成する必要があります。キューブでのカスタムデータソースの有効化ビッグデータセットでは、すべてのデータを閲覧することはできません。ランダムデータのサンプルのみが利用可能です。データサンプルでは、フィルター、編集機能、削除機能は使用できません。カスタムデータソースは、キューブ設定の3つ目のステップで最初に有効化する必要があります。 ビッグデータセットは結合できません。
カスタムデータソースは、キューブの宛先として使用されるデータセットにリンクされます。 ビッグデータセットの主な利点は、事前に計算されたキューブを作成できるため、レポートの読み込み時間が高速化されることです。カスタムデータソースデータセットの有効化ビッグデータセットの作成カスタムソースデータは、データセットごとに有効にする必要があります。 noteデータセットの詳細設定を開き、カスタムデータソース機能を有効にします。 | ||
ライセンスとドメインでビッグデータセット機能を有効にする必要があることに注意してください。 |
| Code Block | ||
|---|---|---|
| ||
${firstValue(DATA_SET_CODE,L_ATTRIBUTE)}
${lastValue(DATA_SET_CODE,L_ATTRIBUTE)}
${firstValue(DATA_SET_CODE,M_INDICATOR)}
${lastValue(DATA_SET_CODE,M_INDICATOR)} |
この関数は、カスタム値としてフィルターに追加する必要があります。
フィルター式を追加することもできます。これにより、ユーザーはより複雑なフィルターアルゴリズムを作成できます。getLastSuccessfulCubeExecution()関数を使用して、最後に成功したキューブ実行の日付と時刻を取得することもできます。
| Code Block | ||
|---|---|---|
| ||
def f = createFilter()
andFilter(f, 'M_TIMESTAMP_INDICATOR', 'GT', timestamp(datetime(getLastSuccessfulCubeExecution().toString('yyyy-MM-dd HH:mm:ss'))))
return f |
バッチサイズ (デフォルトは1,000) - 1つのバッチで実行される行数。特別な場合には、値を増減することが有益な場合があります。ただし、ほとんどの場合、デフォルトのままにしておくことを強くお勧めします。
ワーカーカウント (デフォルトは8) - パラレル実行に使用するワーカーの数。
- 実行タイムアウト [s] - 実行の最大期間を設定します。
いつ - 最初の実行時間。
スケジュール - 実行頻度。
インポート方法 - 宛先データセットのデータで何が起こるべきか。詳細については、データの上書きポリシーをご覧ください。
キューブのサマリー
ユーザーは[キューブ]ページで、ビッグデータセットに関連付けられたすべてのキューブを含むテーブルを表示できます。各キューブについて、スケジュールおよび最後のイベントに関する情報が利用可能です。ユーザーは、行またはキューブの名前をクリックすることでキューブを編集することもできます。キューブごとにいくつかのアクションも使用できます:
- 履歴 - 以前の実行とその結果のリストを参照します。
- 実行 - 手動で実行します。
- スケジュール - 実行を再スケジュールします。以前の設定は上書きされます。
- 削除 - キューブを削除します。
キューブの実行
前述のように、実行は手動で、データ変更時に、またはスケジュールによって実行できます。
- 手動実行 - [アクション]列の[実行]をクリックすると、ユーザーは手動で実行を開始できます。また、インポート方法を選択することもできます。インポート方法は、スケジュールによる実行に使用される方法とは異なる場合があります。
- データの変更時 - ビッグデータセットに変更があるたびに、実行が開始されます。既に実行中のキューブの実行がある場合、新しい実行はキューに入れられ、前のキューブの実行が完了した後に自動的にトリガーされます。
- スケジュールによる実行 - 指定された時間が経過した後、定期的に実行されます。
ユーザーは、[スケジュール]列の日付をクリックしてキャンセルを確認することにより、次にスケジュールされている実行をキャンセルすることもできます。これは実行をキャンセルするだけで、削除はしないことに注意してください。手動で実行した後、スケジュールが復元されます。スケジュールされた実行を完全に削除するには、ユーザーはキューブを編集し、実行スケジュールを削除する必要があります。
ビッグデータセットのバックアップ
ビッグデータセットのXMLバックアップを使用する場合、ターゲットデータセットとキューブ内のマッピングは保存されません。復元後、再度構成する必要があります。
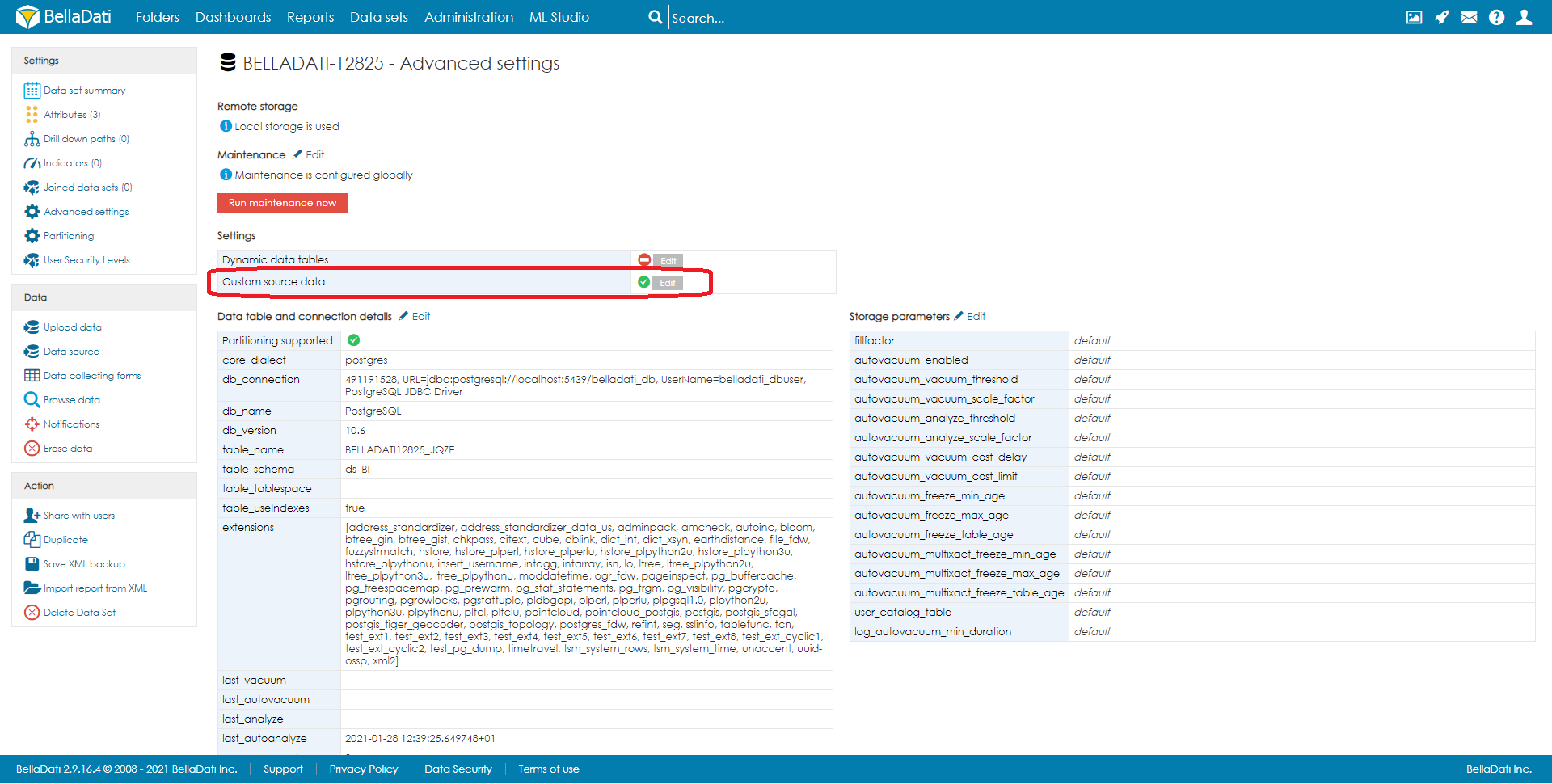
レポートでカスタムデータソースを設定
データセットでカスタムデータソース機能を有効にすると、テーブル設定で[カスタムソースデータ]オプションを使用できるようになります:
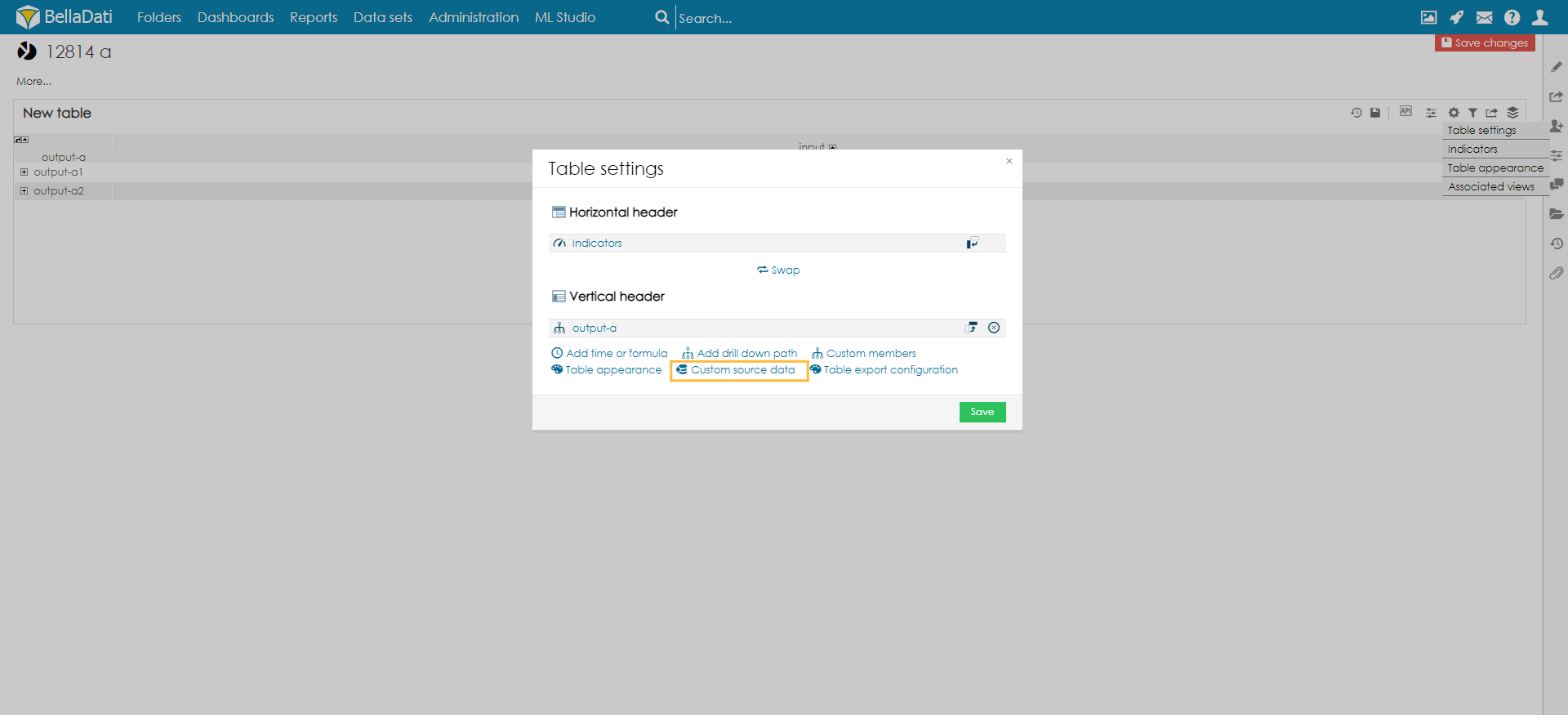
次の設定を使用可能です:
- ソースデータセット - 現在のデータセットと、このデータセットへの宛先を含んだキューブを持つ、すべてのビッグデータセットを表示します。
- (BellaDati 2.9.18まで) ソースデータキューブ - 選択したビッグデータセットのすべてのキューブを表示し、宛先をこのデータセットに設定します。
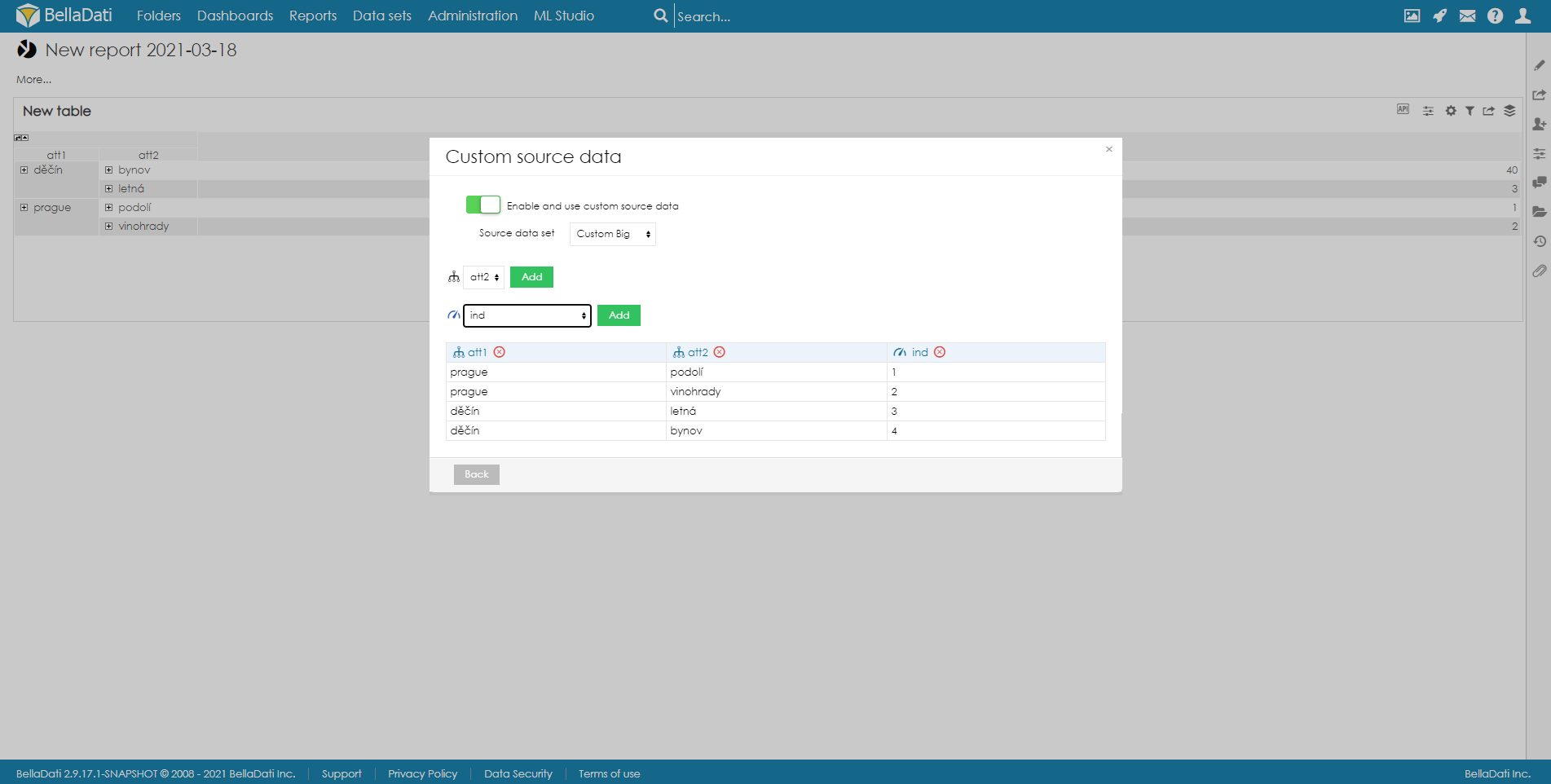
テーブルソースデータとして表示される順序で、属性とインジケータを選択します。
適用されたソースデータ設定は、選択したテーブルに適用されます。
| Sv translation | ||
|---|---|---|
| ||
| Sv translation | ||
| ||
| Sv translation | ||
| ||
Overview
Content Tools