Page History
| Sv translation | ||
|---|---|---|
| ||
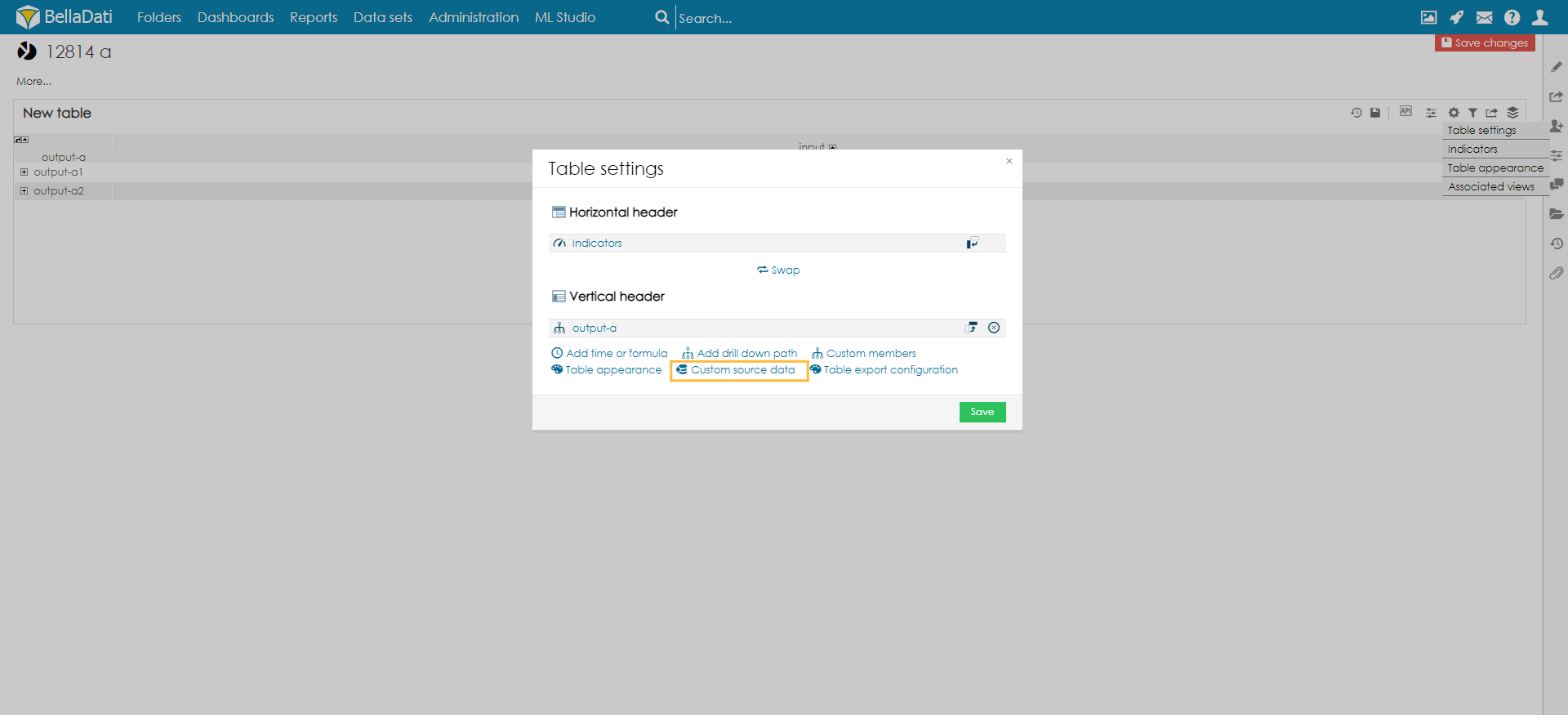
Custom source data can display report's source data directly from from assign cube ENABLING CUSTOM DATA SOURCE IN CUBECustom Data Source needs to be activated firstly in 3rd step of settings of your cube.
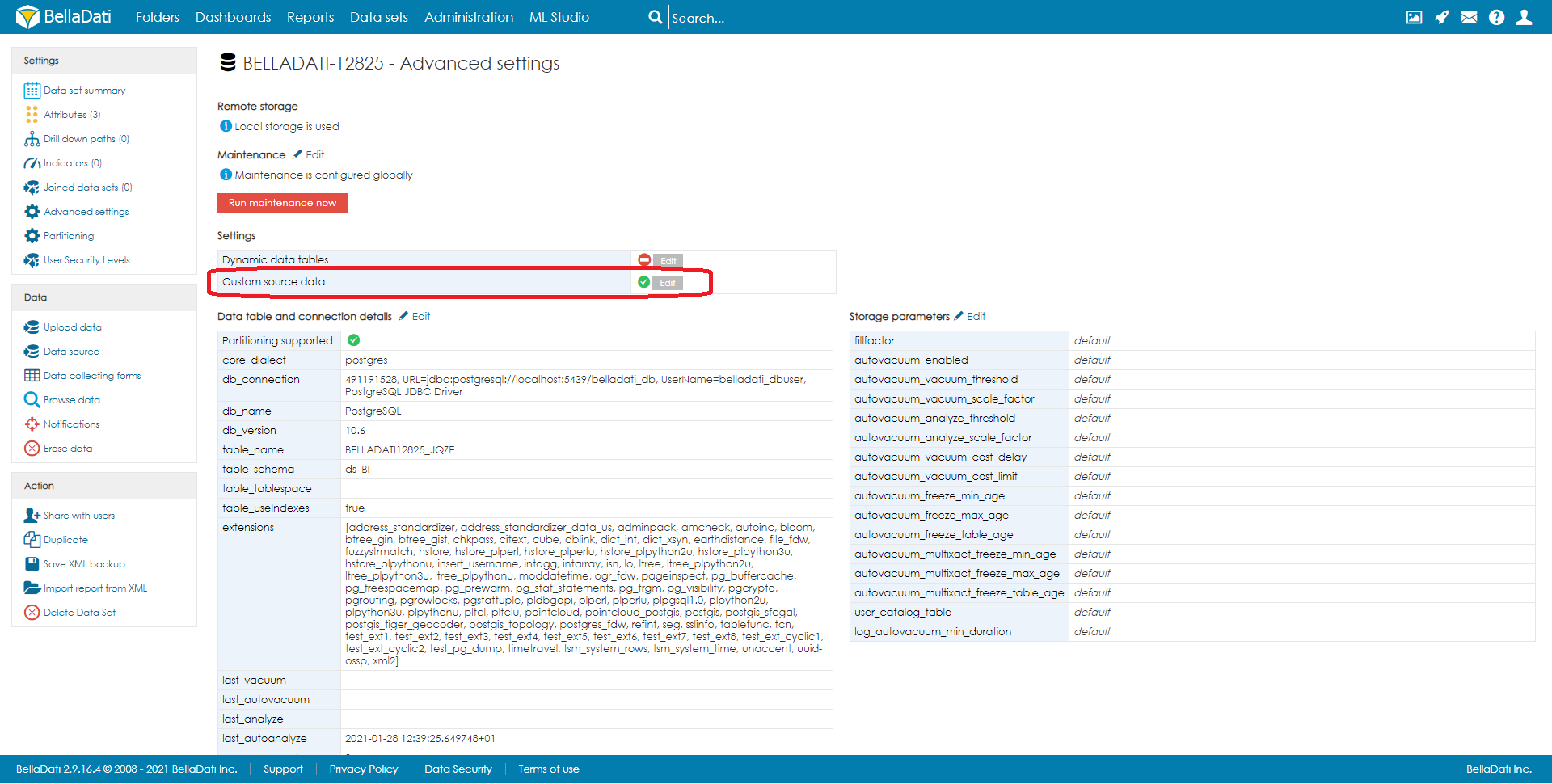
Your Custom Data Source will be linked with Destination of your Cube. ENABLING CUSTOM DATA SOURCE DATASETYou need to enable access from your DataSet to Custom Data Source. In your DataSet open Advanced Settings and Enable Custom Data Source.
Set up custom data source in reportAfter you allowed your DataSet to accept Custom Data Source you can now open your report and edit your settings
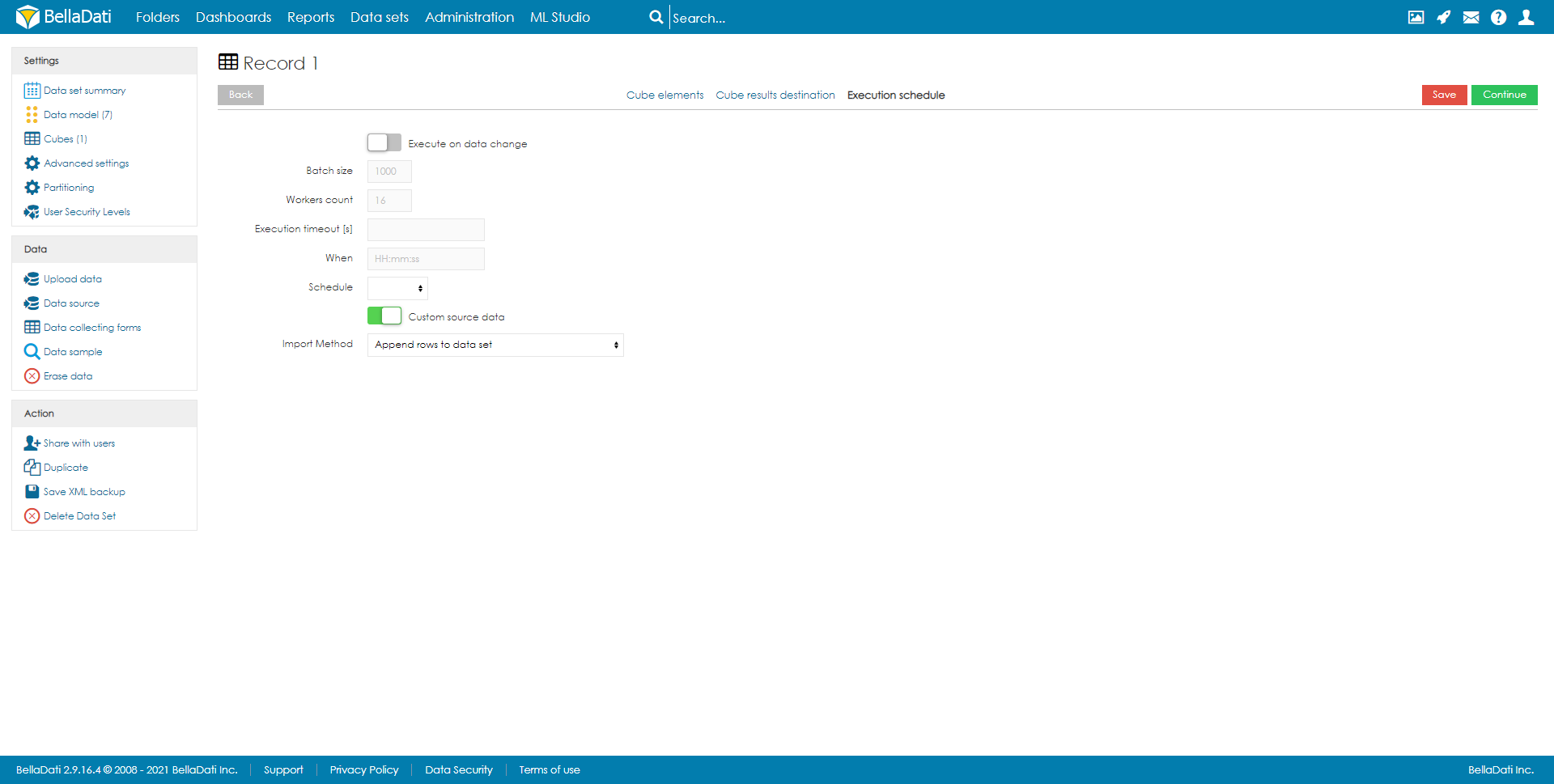
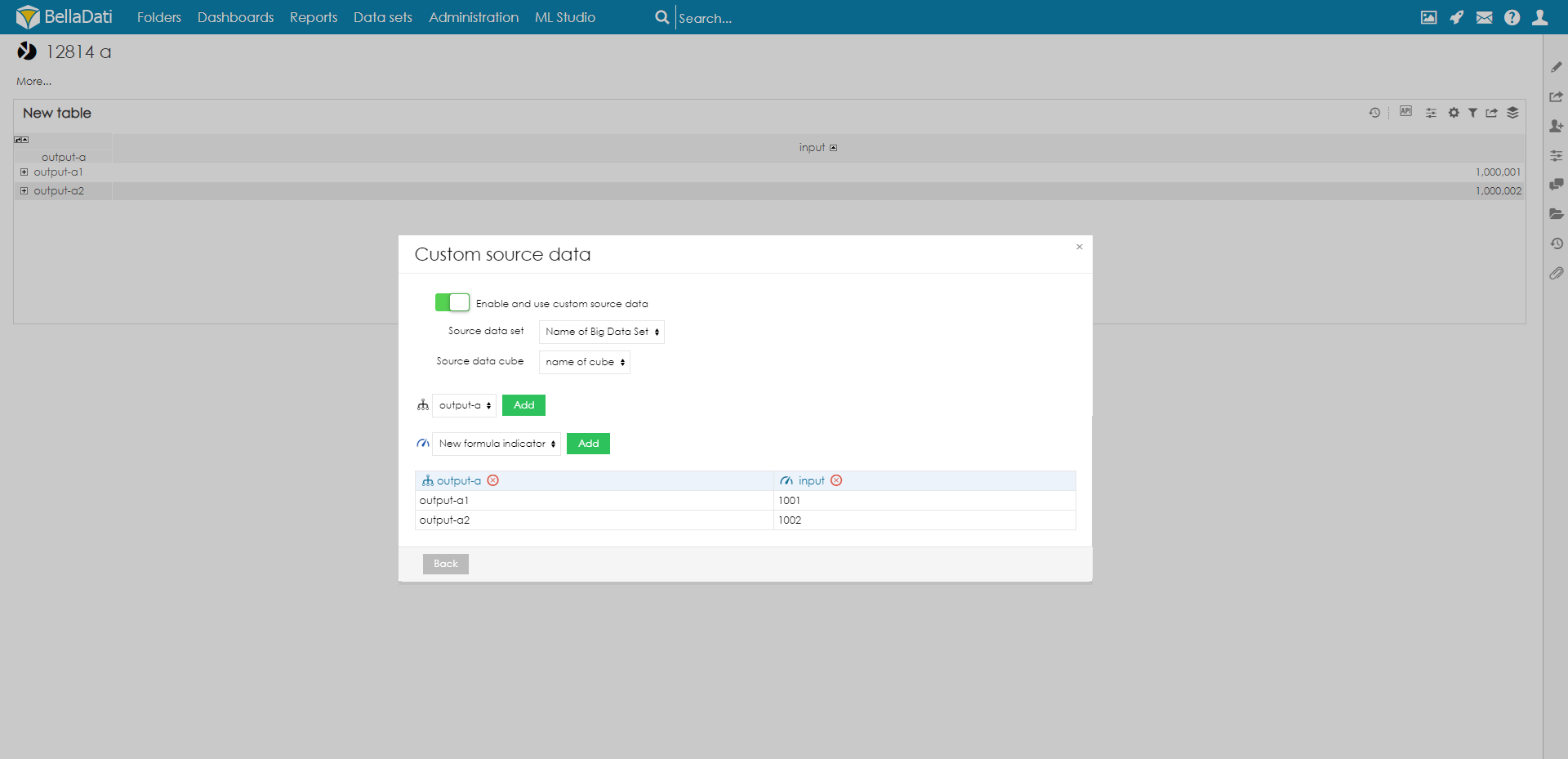
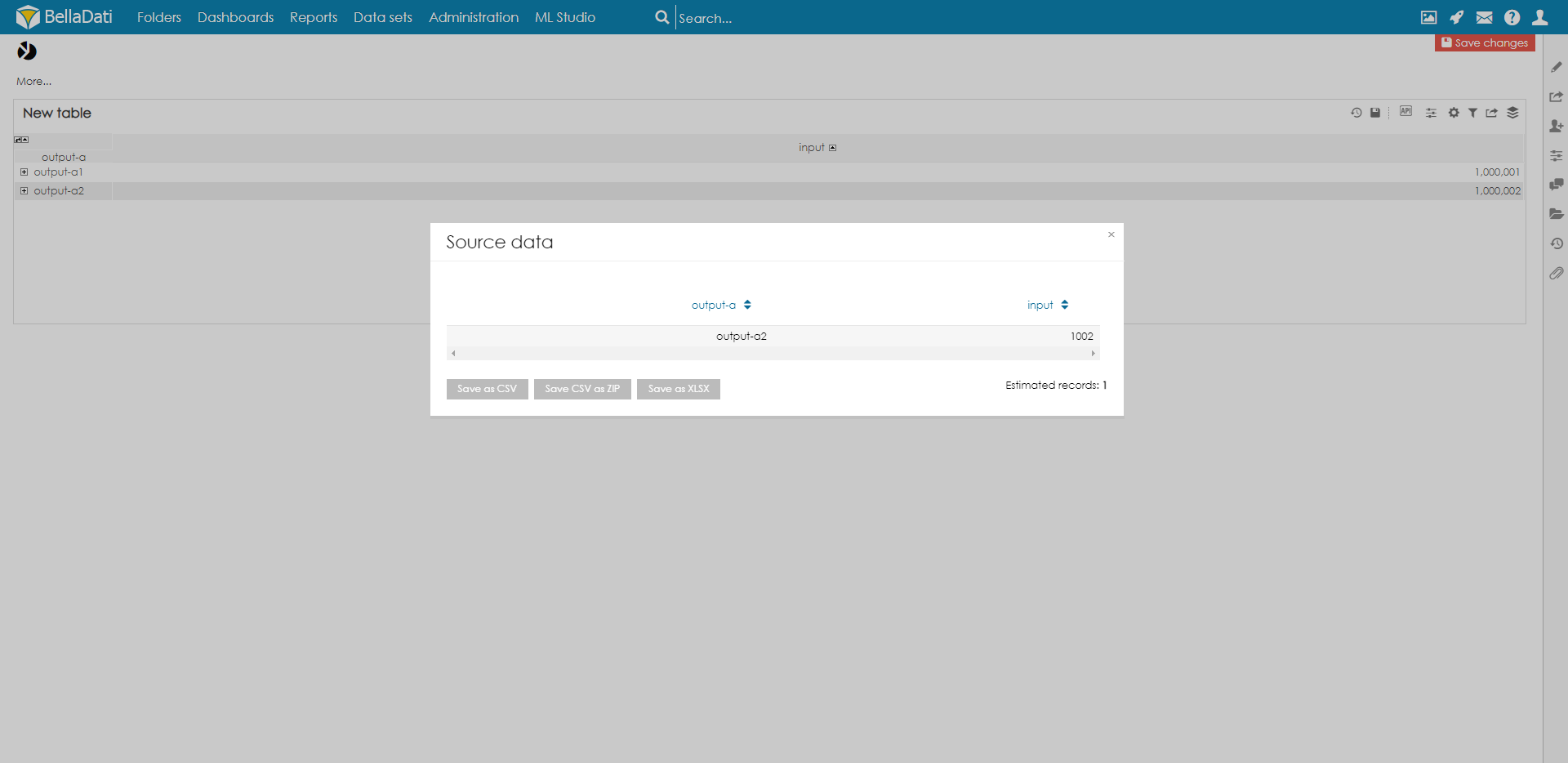
Now you should set your Custom Data Source
Select your Attributes and Indicator in order you want them to be displayed in Data Source. When all settings are applied, when looking at data source of cell you get data directly from cube.
|
| Sv translation | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||
Big Data Sets sind eine spezielle Art von Datensätzen, die verwendet werden können, um sehr große Datenmengen zu speichern und vorbereitete Cubes zu bilden.
Erstellen eines großen Datensatzes
Ein großer Dataset kann erstellt werden, indem Sie auf den Link Großen Dataset erstellen im Menü Aktion auf der Seite Datensätze klicken, den Namen des großen Datasets eingeben und auf Erstellen klicken. Zusammenfassungsseite für große DatensätzeDie Landing Page (Summary Page) ist der Standard-Datasetübersichtsseite sehr ähnlich. Es gibt ein linkes Navigationsmenü und den Hauptbereich mit grundlegenden Informationen über den Dataset:
Daten importierenDaten können wie bei einem StandardDataset in große Datenmengen importiert werden. Benutzer können entweder Daten aus einer Datei oder aus einer Datenquelle importieren. Der große Dataset verwendet jedoch keine Standardkennzeichen und -attribute, sondern jede Spalte ist als Objekt definiert. Diese Objekte können verschiedene Datentypen haben:
Nach dem Import können Benutzer die Datenprobenseite öffnen, um einen zufällig ausgewählten Teil der Daten anzuzeigen. Objekte verwaltenObjekte (Spalten) können beim Import automatisch angelegt oder auf der Datenmodellseite definiert werden. Beim Hinzufügen eines neuen Objekts können Benutzer dessen Namen, Datentyp, Indexierung und ob sie leere Werte enthalten dürfen oder nicht, angeben. Bitte beachten Sie, dass GEO point, GEO JSON, Langtext, boolesch und numerisch nicht indiziert werden können. Sie können auch Objekte bearbeiten und löschen, indem Sie auf die Zeile klicken. CubesCube ist eine Datentabelle, die aggregierte Daten aus dem großen Dataset enthält. Benutzer können die Aggregation definieren und die Daten durch die Anwendung von Filtern einschränken. Daten aus dem Cube können dann in einen Dataset importiert werden. Jeder große Dataset kann mehr als einen Cube haben und jeder Cube kann unterschiedliche Einstellungen haben. Cube erstellenUm einen Cube zu erstellen, müssen Benutzer diesen Schritten folgen:
Zusammenfassung der CubesAuf der Seite Cubes sehen die Benutzer eine Tabelle mit allen Cubes, die dem großen Dataset zugeordnet sind. Für jeden Cube stehen Informationen über den Zeitplan und die letzte Veranstaltung zur Verfügung. Benutzer können den Würfel auch bearbeiten, indem sie irgendwo auf die Zeile oder den Namen des Würfels klicken. Für jeden Cube stehen auch mehrere Aktionen zur Verfügung:
Cube-AusführungWie bereits erwähnt, kann die Ausführung manuell, bei Datenänderung oder nach Zeitplan erfolgen.
Der Benutzer kann auch die nächste geplante Ausführung abbrechen, indem er auf das Datum in der Spalte Zeitplan klickt und die Abbestellung bestätigt. Bitte beachten Sie, dass dadurch nur die Ausführung abgebrochen und nicht gelöscht wird. Nachdem die Ausführung manuell ausgeführt wurde, wird der Zeitplan wiederhergestellt. Um die geplante Ausführung vollständig zu löschen, müssen Benutzer den Cube bearbeiten und den Ausführungsplan löschen. Sicherung eines großen DatasetsBei der Verwendung der XML-Sicherung von großen Datensätzen werden der Zieldataset und das Mapping im Cube nicht gespeichert. Nach der Wiederherstellung müssen sie neu eingerichtet werden.
|
| Sv translation | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||
ビッグデータセットは、非常に大量のデータを保存し、事前に計算されたキューブを構築するために使用できる特別なタイプのデータセットです。標準データセットとビッグデータセットの主な違いは以下の通りです:
ビッグデータセットの作成
ビッグデータセットを作成するには、[データセット]ページの[アクション]メニューにある[ビッグデータセットの作成]リンクをクリックし、ビッグデータセットの名前を入力して[作成]をクリックします。 ビッグデータセット サマリーページランディングページ(概要ページ)は、標準のデータセット概要ページに非常に似ています。左側のナビゲーションメニューと、データセットに関する基本情報を含むメインエリアがあります:
データのインポートデータは、標準のデータセットと同じ方法で大きなデータをインポートできます。ユーザーは、ファイルまたはデータソースからデータをインポートできます。ただし、ビッグデータセットは標準のインジケータと属性を使用していませんが、代わりに各列がオブジェクトとして定義されています。これらのオブジェクトには、様々なデータタイプがあります:
インポート後、ユーザーはデータサンプルページを開いて、データのランダムに選択された部分を表示できます。 オブジェクトの管理オブジェクト(列)は、インポート中に自動的に作成するか、データモデルページで定義できます。ユーザーは、新しいオブジェクトを追加する際に、名前、データ型、インデックス付け、空の値を含めることができるかどうかを指定できます。 Geoポイント、Geo JSON、ロングテキスト、ブール値、数値はインデックスに登録できないことに注意してください。 行をクリックして、オブジェクトを編集および削除することもできます。 キューブキューブは、ビッグデータセットの集計データを含むデータテーブルです。ユーザーは、集計を定義し、フィルターを適用してデータを制限できます。その後、キューブのデータをデータセットにインポートできます。各ビッグデータセットは複数のキューブを持つことができ、各キューブは異なる設定を持つことができます。 キューブの作成キューブを作成するには、ユーザーは以下の手順に従う必要があります:
キューブのサマリーユーザーは[キューブ]ページで、ビッグデータセットに関連付けられたすべてのキューブを含むテーブルを表示できます。各キューブについて、スケジュールおよび最後のイベントに関する情報が利用可能です。ユーザーは、行またはキューブの名前をクリックすることでキューブを編集することもできます。キューブごとにいくつかのアクションも使用できます:
キューブの実行前述のように、実行は手動で、データ変更時に、またはスケジュールによって実行できます。
ユーザーは、[スケジュール]列の日付をクリックしてキャンセルを確認することにより、次にスケジュールされている実行をキャンセルすることもできます。これは実行をキャンセルするだけで、削除はしないことに注意してください。手動で実行した後、スケジュールが復元されます。スケジュールされた実行を完全に削除するには、ユーザーはキューブを編集し、実行スケジュールを削除する必要があります。 ビッグデータセットのバックアップビッグデータセットのXMLバックアップを使用する場合、ターゲットデータセットとキューブ内のマッピングは保存されません。復元後、再度構成する必要があります。
|
| Sv translation | ||
|---|---|---|
| ||
| Sv translation | ||
|---|---|---|
| ||
| Sv translation | ||
|---|---|---|
| ||
Overview
Content Tools