| Note |
|---|
BellaDati 2.9からビッグデータセットが利用可能です |
ビッグデータセットは、非常に大量のデータを保存し、事前に計算されたキューブを構築するために使用できる特別なタイプのデータセットです。標準データセットとビッグデータセットの主な違いは以下の通りです: - レポートをビッグデータセットに直接作成することはできません。最初にキューブを作成する必要があります。
- ビッグデータセットでは、すべてのデータを閲覧することはできません。ランダムデータのサンプルのみが利用可能です。データサンプルでは、フィルター、編集機能、削除機能は使用できません。
- ビッグデータセットは結合できません。
| Tip |
|---|
ビッグデータセットの主な利点は、事前に計算されたキューブを作成できるため、レポートの読み込み時間が高速化されることです。 |
ビッグデータセットの作成| Note |
|---|
ライセンスとドメインでビッグデータセット機能を有効にする必要があることに注意してください。 |
ビッグデータセットを作成するには、[データセット]ページの[アクション]メニューにある[ビッグデータセットの作成]リンクをクリックし、ビッグデータセットの名前を入力して[作成]をクリックします。 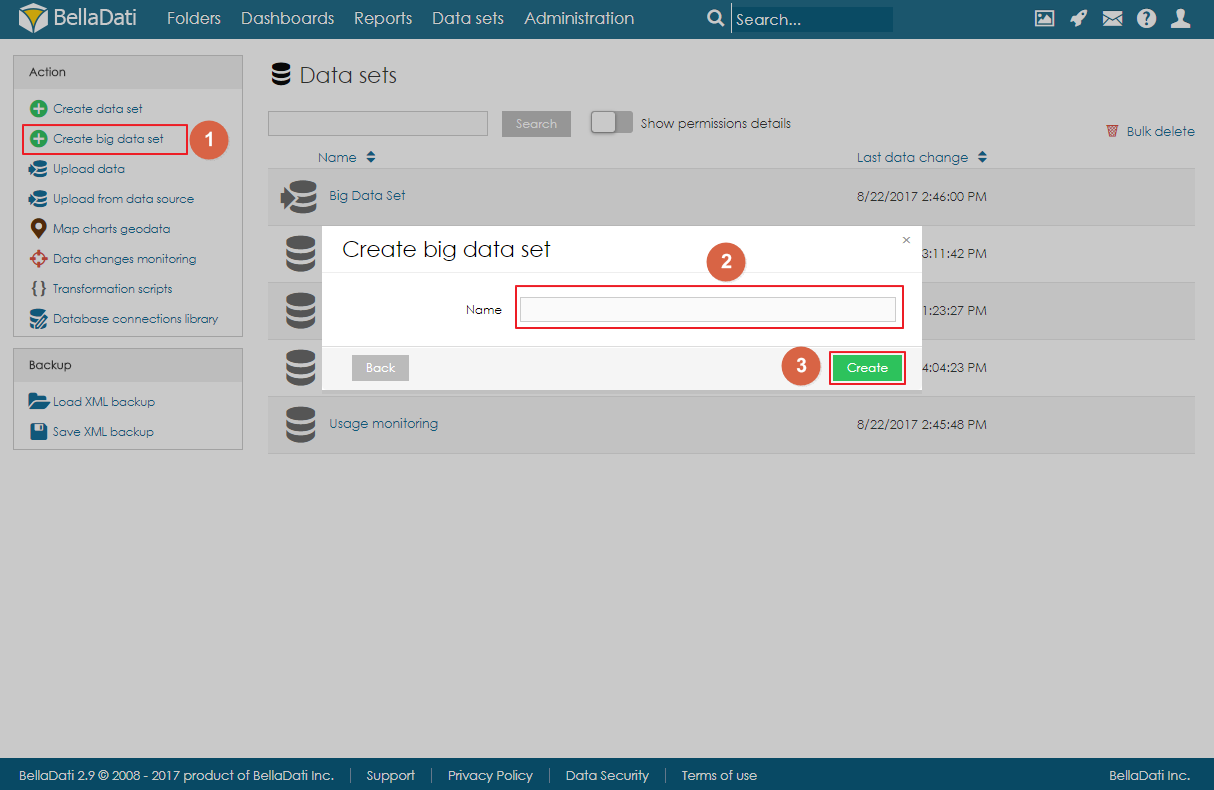
ビッグデータセット サマリーページランディングページ(概要ページ)は、標準のデータセット概要ページに非常に似ています。左側のナビゲーションメニューと、データセットに関する基本情報を含むメインエリアがあります: - 説明
- 最終更新日
- レコード数
- キューブの概要
- インポートの履歴
データのインポートData can be imported to big the data the same way as to standard data set. Users can either import data from a file or from a data source. However, big data set is not using standard indicators and attributes, but instead, each column is defined as an object. These objects can have various data types: データは、標準のデータセットと同じ方法で大きなデータをインポートできます。ユーザーは、ファイルまたはデータソースからデータをインポートできます。ただし、ビッグデータセットは標準のインジケータと属性を使用していませんが、代わりに各列がオブジェクトとして定義されています。これらのオブジェクトには、様々なデータタイプがあります: - テキスト
- 日付
- 時間
- 日付時間
- GEOポイント
- GEO JSON
- ロングテキスト
- ブール値
- 数値
インポート後、ユーザーはデータサンプルページを開いて、データのランダムに選択された部分を表示できます。 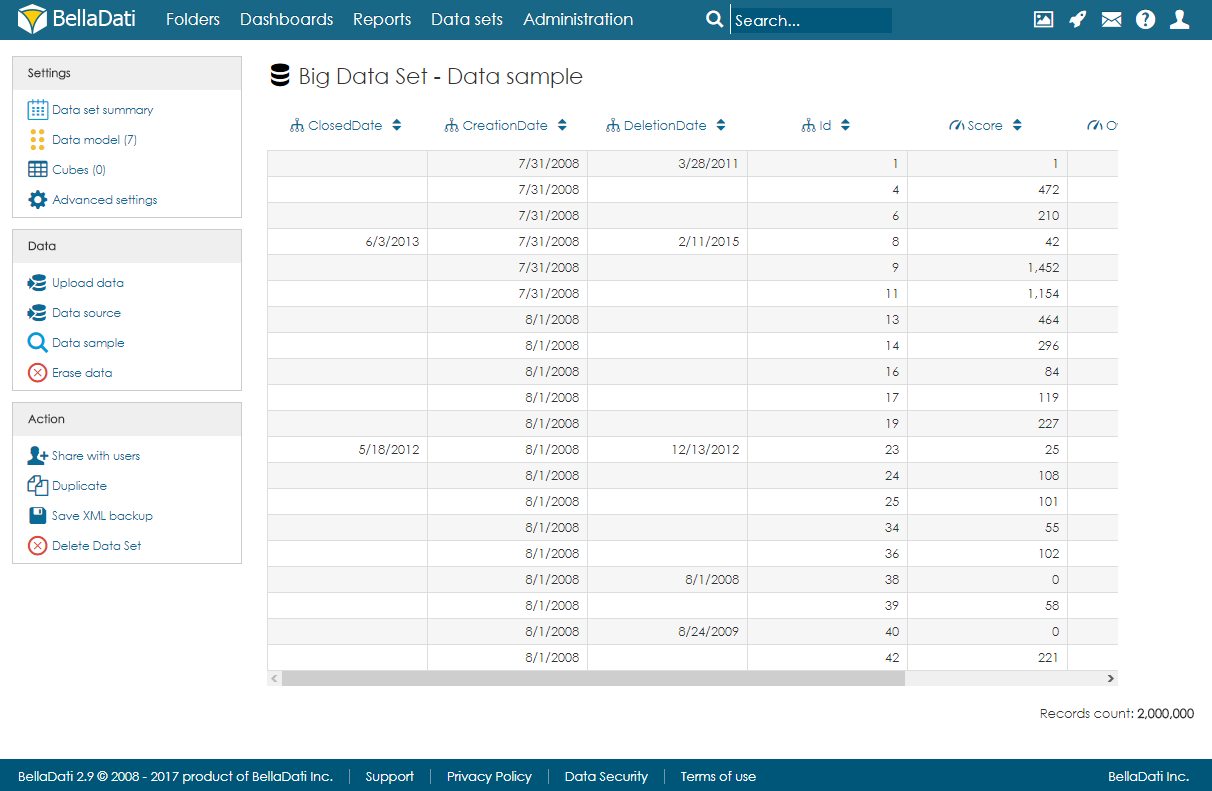 Image Removed Image Removed
オブジェクトの管理オブジェクト(列)は、インポート中に自動的に作成するか、データモデルページで定義できます。ユーザーは、新しいオブジェクトを追加する際に、名前、データ型、インデックス付け、空の値を含めることができるかどうかを指定できます。 GEOポイント、GEO JSON、ロングテキスト、ブール値、数値はインデックスに登録できないことに注意してください。 行をクリックして、オブジェクトを編集および削除することもできます。 キューブキューブは、ビッグデータセットの集計データを含むデータテーブルです。ユーザーは、集計を定義し、フィルターを適用してデータを制限できます。その後、キューブのデータをデータセットにインポートできます。各ビッグデータセットは複数のキューブを持つことができ、各キューブは異なる設定を持つことができます。 キューブの作成キューブを作成するには、ユーザーは以下の手順に従う必要があります: データは、標準のデータセットと同じ方法で大きなデータをインポートできます。ユーザーは、ファイルまたはデータソースからデータをインポートできます。ただし、ビッグデータセットは標準のインジケータと属性を使用していませんが、代わりに各列がオブジェクトとして定義されています。これらのオブジェクトには、様々なデータタイプがあります: - テキスト
- 日付
- 時間
- 日付時間
- GEOポイント
- GEO JSON
- ロングテキスト
- ブール値
- 数値
インポート後、ユーザーはデータサンプルページを開いて、データのランダムに選択された部分を表示できます。 Image Added オブジェクトの管理オブジェクト(列)は、インポート中に自動的に作成するか、データモデルページで定義できます。ユーザーは、新しいオブジェクトを追加する際に、名前、データ型、インデックス付け、空の値を含めることができるかどうかを指定できます。 GEOポイント、GEO JSON、ロングテキスト、ブール値、数値はインデックスに登録できないことに注意してください。 行をクリックして、オブジェクトを編集および削除することもできます。 キューブキューブは、ビッグデータセットの集計データを含むデータテーブルです。ユーザーは、集計を定義し、フィルターを適用してデータを制限できます。その後、キューブのデータをデータセットにインポートできます。各ビッグデータセットは複数のキューブを持つことができ、各キューブは異なる設定を持つことができます。 キューブの作成キューブを作成するには、ユーザーは以下の手順に従う必要があります: - [キューブの作成]をクリックします。
- 名前と、説明(オプション)を入力します。
- 列(属性要素とデータ要素)を選択します。属性要素は、キューブの集約を定義します。例えば、ユーザーが国列を選択すると、データは国ごとに集計されます(1行
- [キューブの作成]をクリックします。
- 名前と、説明(オプション)を入力します。
- 列(属性要素とデータ要素)を選択します。属性要素は、キューブの集約を定義します。例えば、ユーザーが国列を選択すると、データは国ごとに集計されます(1行= 1国)。ユーザーは数式インジケータを作成することもできます。リアルタイムで、ユーザーは画面の右側にキューブのプレビューを表示することもできます。プレビューはデータサンプルのみに基づいて構築されます。つまり、空の場合もありますが、実行後に一部のデータがデータセットにインポートされることに注意してください。名前の横にある矢印を使用して、属性とインジケータの順序を変更できます。
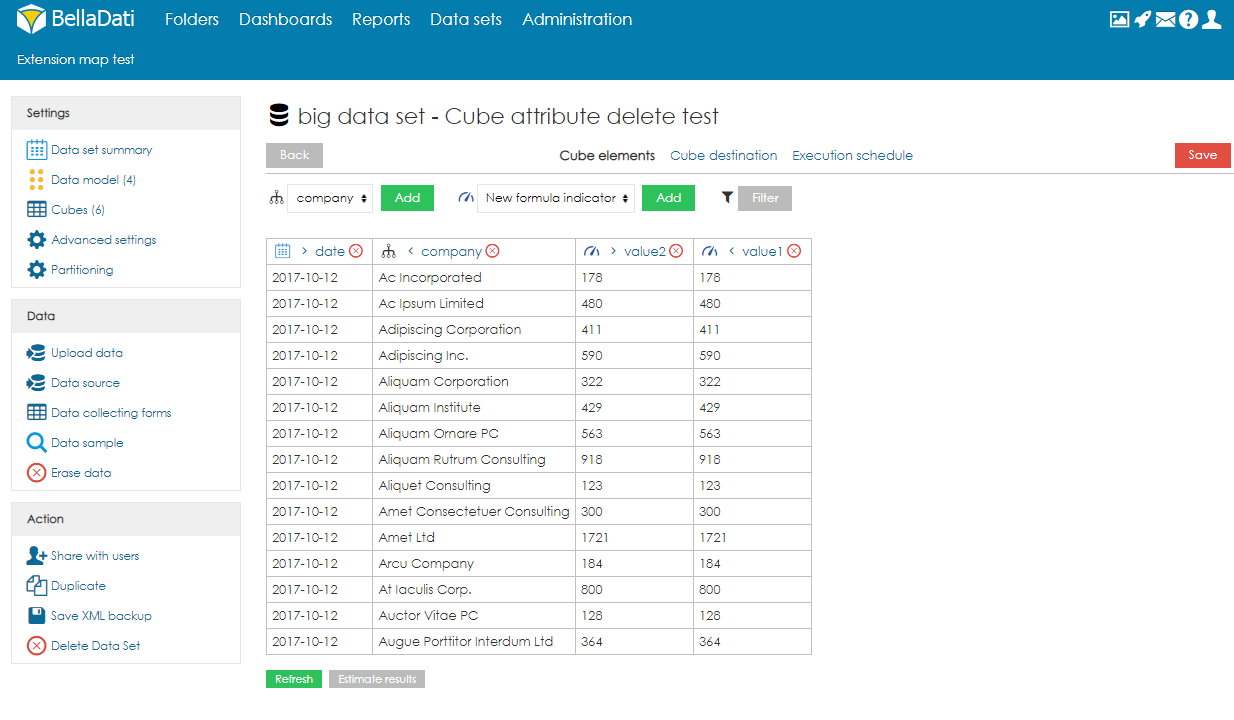 - オプションで、ユーザーはフィルターを適用してデータの一部のみを処理することもできます。
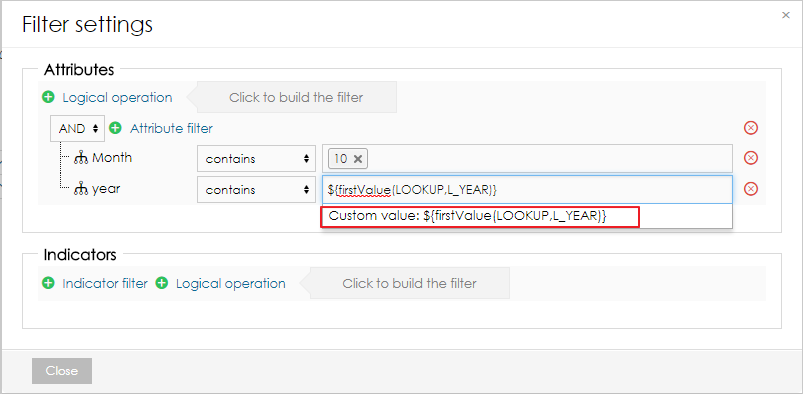
フィルターでは、ユーザーは次の関数を使用して、異なるデータセットの最初と最後の値を参照できます: | Code Block |
|---|
| ${firstValue(DATA_SET_CODE,L_ATTRIBUTE)}
${lastValue(DATA_SET_CODE,L_ATTRIBUTE)}
${firstValue(DATA_SET_CODE,M_INDICATOR)}
${lastValue(DATA_SET_CODE,M_INDICATOR)} |
この関数は、カスタム値としてフィルターに追加する必要があります。
 フィルター式を追加することもできます。これにより、ユーザーはより複雑なフィルターアルゴリズムを作成できます。getLastSuccessfulCubeExecution()関数を使用して、最後に成功したキューブ実行の日付と時刻を取得することもできます。 | Code Block |
|---|
| def f = createFilter()
andFilter(f, 'M_TIMESTAMP_INDICATOR', 'GT', timestamp(datetime(getLastSuccessfulCubeExecution().toString('yyyy-MM-dd HH:mm:ss'))))
return f |
Select destination data set and mapping. By using the search field, users have to select destination data set. After execution, data will be imported from the cube to this data set. After choosing the data set, users have to specify the mapping. Each column of the cube has to be assigned to an attribute or indicator of the destination data set. Attribute elements can be mapped to attribute columns in destination data set. Data elements can be mapped to indicator columns and also attribute columns.
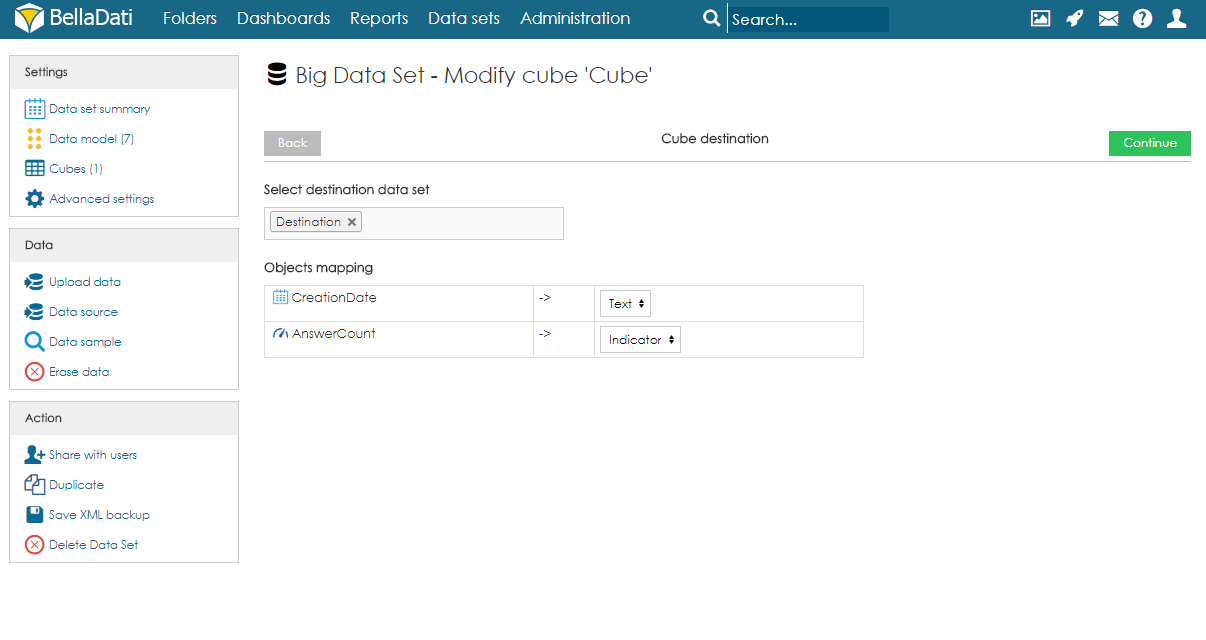 Image Removed Image Removed - Set up execution schedule. The execution can be run manually, on data change or by schedule. When scheduling the execution, users can specify following parameters:
Batch size (default 1000) - the number of rows which will be executed in one batch. In special cases, it might be beneficial to increase or decrease the value. However, in most cases, we strongly suggest to leave in on default. Workers count (default 8) - the number of workers which should be used for parallel execution. - Execution timeout [s] - sets the maximum duration of the execution.
When - time of the first execution. Schedule - how often should be executed. Import Method - what should happen with data in the destination data set. See Data overwriting policy for more information. 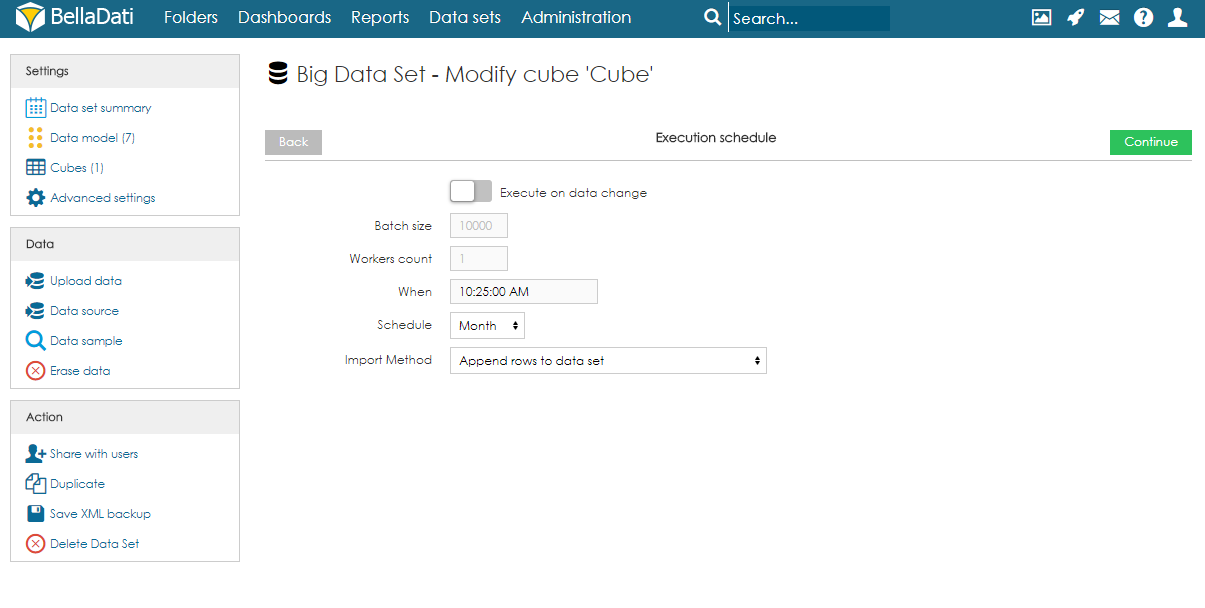 Image Removed Image Removed
キューブのサマリー On the Cubes page, users can see a table with all cubes associated with the big data set. For each cube, information about the schedule and last event are available. Users can also edit the cube by clicking anywhere on the row or on the name of the cube. Several actions are also available for each cube: - History - see a list of previous executions and their result.
- Run - manually run the execution.
- Schedule - reschedule the execution. Previous settings will be overwritten.
- Delete - delete the cube.
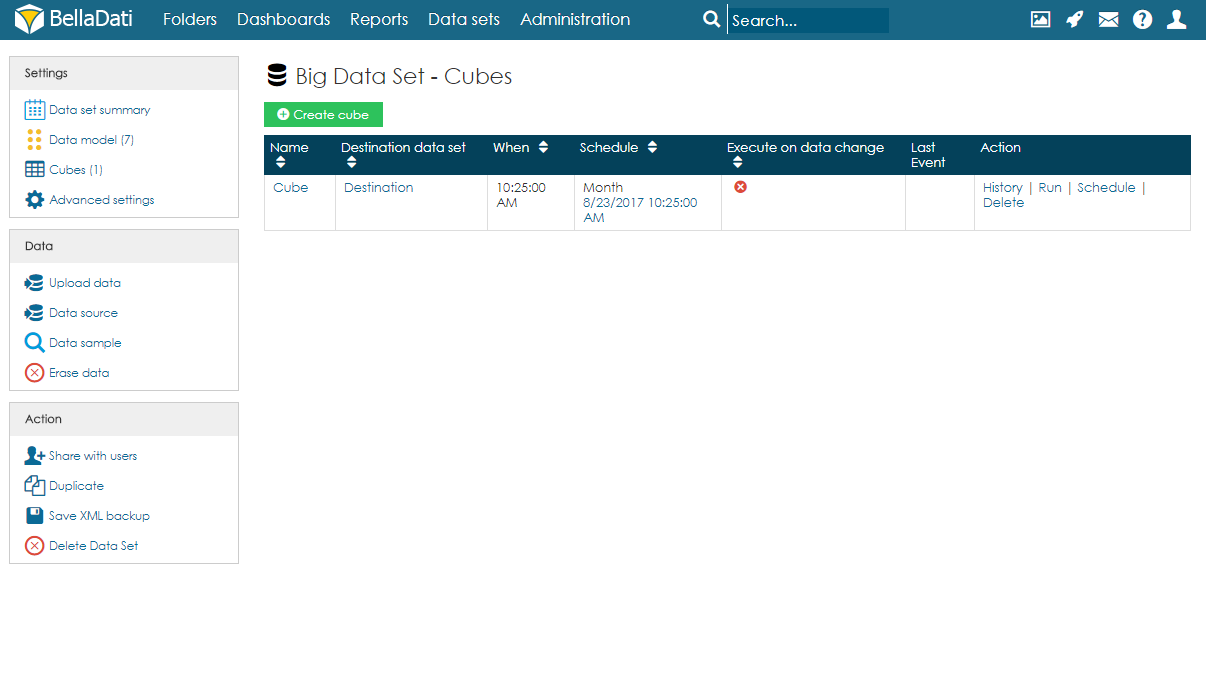 Image Removed Image Removed
キューブの実行As mentioned above, execution can be run manually, on data change or by schedule. - Manual execution - by clicking on Run in the Action column, users can start the execution manually. They can also select the import method, which can be different than the one used for scheduled execution.
- On data change - every time there is a change in the big data set, the execution will be started.
- Scheduled execution - execution will be run periodically after after specified amount of time.
- 宛先データセットとマッピングを選択します。ユーザーは検索フィールドを使用して、宛先データセットを選択する必要があります。実行後、データはキューブからこのデータセットにインポートされます。データセットを選択した後、ユーザーはマッピングを指定する必要があります。キューブの各列は、宛先データセットの属性またはインジケータに割り当てる必要があります。属性要素は、宛先データセットの属性列にマッピングできます。データ要素は、インジケータ列および属性列にマップできます。
Image Added - 実行スケジュールを設定します。実行は手動で、データの変更時、またはスケジュールで実行できます。実行をスケジュールする際、ユーザーは以下のパラメーターを指定できます:
バッチサイズ (デフォルトは1,000) - 1つのバッチで実行される行数。特別な場合には、値を増減することが有益な場合があります。ただし、ほとんどの場合、デフォルトのままにしておくことを強くお勧めします。 ワーカーカウント (デフォルトは8) - パラレル実行に使用するワーカーの数。 - 実行タイムアウト [s] - 実行の最大期間を設定します。
いつ - 最初の実行時間。 スケジュール - 実行頻度。 インポート方法 - 宛先データセットのデータで何が起こるべきか。詳細については、データの上書きポリシーをご覧ください。 Image Added
キューブのサマリーユーザーは[キューブ]ページで、ビッグデータセットに関連付けられたすべてのキューブを含むテーブルを表示できます。各キューブについて、スケジュールおよび最後のイベントに関する情報が利用可能です。ユーザーは、行またはキューブの名前をクリックすることでキューブを編集することもできます。キューブごとにいくつかのアクションも使用できます: - 履歴 - 以前の実行とその結果のリストを参照します。
- 実行 - 手動で実行します。
- スケジュール - 実行を再スケジュールします。以前の設定は上書きされます。
- 削除 - キューブを削除します。
Image Added キューブの実行前述のように、実行は手動で、データ変更時に、またはスケジュールによって実行できます。 - 手動実行 - [アクション]列の[実行]をクリックすると、ユーザーは手動で実行を開始できます。また、インポート方法を選択することもできます。インポート方法は、スケジュールによる実行に使用される方法とは異なる場合があります。
- データの変更時 - ビッグデータセットに変更があるたびに、実行が開始されます。
- スケジュールによる実行 - 指定された時間が経過した後、定期的に実行されます。
ユーザーは、[スケジュール]列の日付をクリックしてキャンセルを確認することにより、次にスケジュールされている実行をキャンセルすることもできます。これは実行をキャンセルするだけで、削除はしないことに注意してください。手動で実行した後、スケジュールが復元されます。スケジュールされた実行を完全に削除するには、ユーザーはキューブを編集し、実行スケジュールを削除する必要があります。Users can also cancel the next scheduled execution by clicking on the date in the column Schedule and confirming the cancellation. Please note this will only cancel the execution and it won't delete it. After running the execution manually, the schedule will be restored. To delete the scheduled execution completely, users have to edit the cube and delete the Execution schedule. ビッグデータセットのバックアップビッグデータセットのXMLバックアップを使用する場合、ターゲットデータセットとキューブ内のマッピングは保存されません。復元後、再度構成する必要があります。 |