Big Data Sets are available since BellaDati 2.9
Big Data Sets are a special type of data sets which can be used to store very large amount of data. The main differences between standard data sets and big data sets are:
- Reports cannot be built directly on big data sets. Cubes have to be created first.
- In big data sets, it is not possible to browse all data. Only random data sample is available. Filters, edit function and delete function is not available in the data sample.
- Big data sets cannot be joined.
Creating Big Data Set
Please note that Big Data Set functionality needs to be enabled in the license and in the domain.
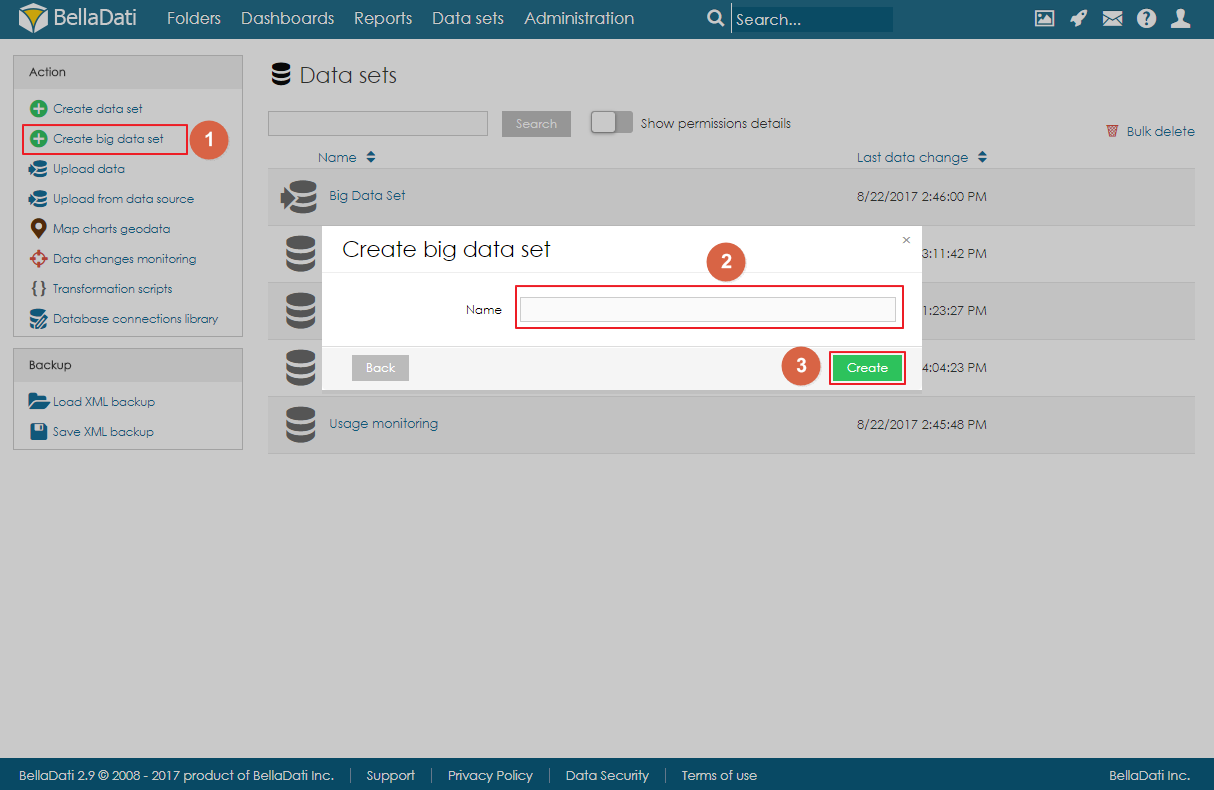
Big Data Set can be created by clicking on the link Create big data set in the Action menu on Data Sets page, filling in the name of the big data set and clicking on Create.
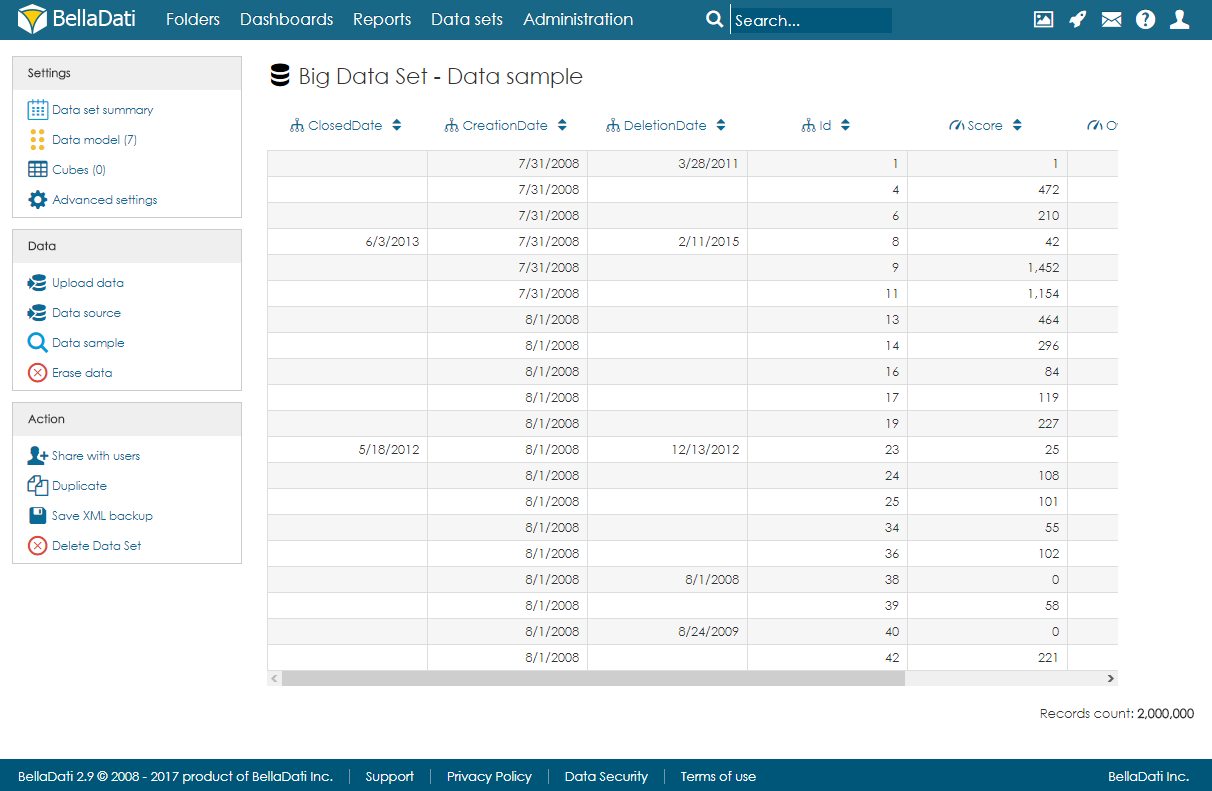
Big Data Set summary page
The landing page (summary page) is very similar to standard data set summary page. There are a left navigation menu and the main area with basic information about the data set:
- description,
- date of last change,
- records count,
- cubes overview,
- import history.
Importing Data
Data can be imported to big the data the same way as to standard data set. Users can either import data from a file or from a data source. However, big data set is not using standard indicators and attributes, but instead, each column is defined as an object. These objects can have various data types:
- text,
- date,
- time,
- datetime,
- GEO point,
- GEO JSON,
- long text,
- boolean,
- numeric.
After import, users can open the data sample page to see a randomly selected part of the data.
Managing Objects
Objects (columns) can be created automatically during the import or they can be defined on the data model page. When adding a new object, users can specify its name, data type, indexation and whether they can contain empty values or not. Please note that GEO point, GEO JSON, long text, boolean and numeric cannot be indexed.
Objects can be also edited and deleted by clicking on the row.
Cubes
Cube is a data table which contains aggregated data from the big data set. Users can define the aggregation and also limit the data by applying filters. Data from the cube can be then imported to a data set. Each big data set can have more than one cube and each cube can have different settings.
Creating Cube
To create a cube, users need to follow these steps:
- Click on Create cube
- Fill-in the name and optionally the description.
- Select which columns (attribute elements and data elements). Attribute elements define the aggregation of the cube. For example, if the user selects column Country, the data will be aggregated for each country (one row = one country). In the real-time, users can also see the preview of the cube on the right side of the screen. Please note that the preview is built on the data sample only, which means that it can be empty, although some data will be imported to the data set after the execution.
- Optionally, users can also apply filters to work with only part of the data.
- Select destination data set and mapping. By using the search field, users have to select destination data set. After execution, data will be imported from the cube to this data set. After choosing the data set, users have to specify the mapping. Each column of the cube has to be assigned to an attribute or indicator of the destination data set.
Backup of Big Data Set
When using the XML backup of big data set, the target data set and mapping in the cube is not stored. After restoring, they have to be set up again.
Overview
Content Tools